
ComfyUI-ELLAを久しぶりに試してみた話(2024/10)

前回記事に記載した、Lavi-Bridgeを見直したついでに、ELLAも触って遊んでみました。
結論としては、こちらの方が良いですね。
SDXL対応がなされないのが残念です。
SD1.5でSDXLに近い出力をしてくれることが改めて感じられましたが、Pony系の出力は期待できません。
また、同じプロンプトだと比較的同じような人物になる傾向があるので、バリエーションを求めると厳しい可能性もありそうです。
同じプロンプトで、同じシード値なのですが、通常で生成される画像が全く違うという感じが面白いですね。
プロンプトはFLUXなどで使用する感じの文章でOKなので、FLUXが流行っている今なら試してみるのも面白いかも。
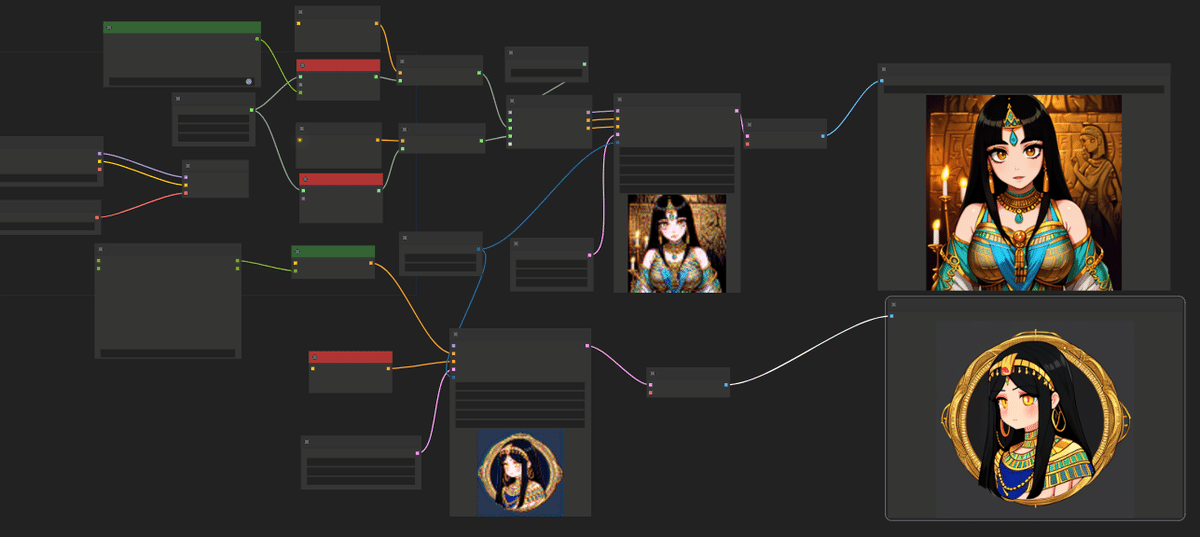
ワークフローを確認すると、ELLAの特徴は拡張性があることが分かります。
Lavi-Bridgeと比較すると、KSamplerにつながっているので、ここでコントロールネットとか追加が出来ます。Githubのサイトに、色んなパターンのワークフローがあり、それを物語っています。

また、プロンプトですが、T5を使用していますが、CLIPの分を追加することもできます。ここは大きいです。
ここでCLIPが対応している文章を入れることで、その雰囲気を追加することができます。

ご存じの方も多いかと思いますが、T5のみの使用も可能で、その場合は基本的に叡智なものは出ません。それは公式の方で「学習してない」みたいな感じで記載があったと思います。
しかし、CLIPを追加することで、叡智な部分を緩和することが出来る様になっています。また、Danbooruタグとかも、CLIPから入れるのが良いかも知れません。
これを経験するとFLUXのT5も無検閲とかにすると叡智なものが出やすくなるのかなとか思ったりしますが、探しても無いですね。Huggingfacwには。
さて、話を戻しますが、ELLAの拡張性が高いという話のついでにTiled diffusionも試してみました。
SDXLでやったのと同じフローにしましたが、こちらの方が効果が大きいですね。
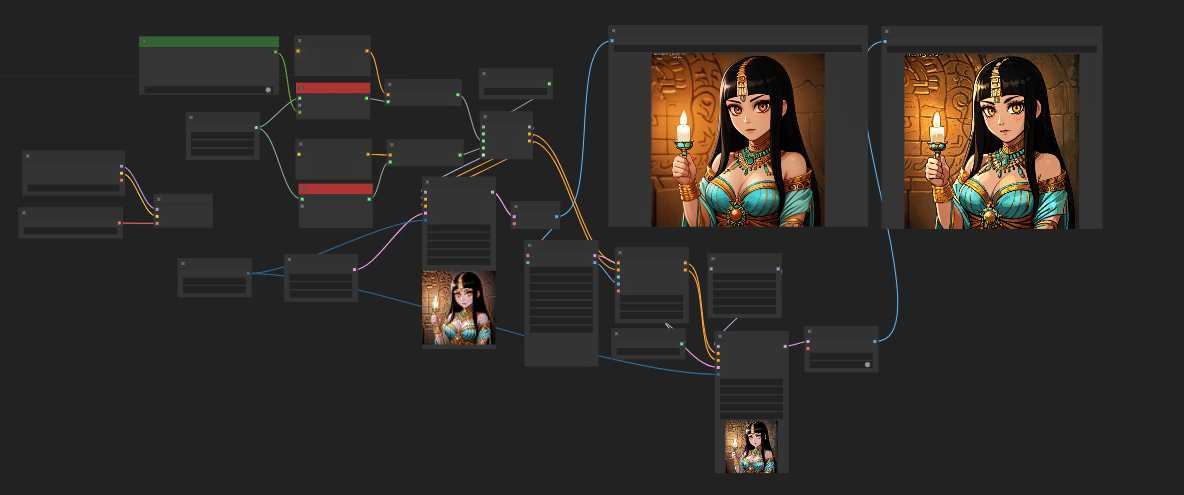
適当な調整ですが、書き込みが増えましたね。


ちなみに、本家が出している論文だとllama2をLLMとして使用していたりしていますが、それは公開されていません。
無検閲モデルとか使われることを危惧されているのかもしれません。
ちなみにGithubでは、公式が出しているもの以外で、2つほどELLAのComfyUI版を出しています。
どれも更新は最近していないので、公式のを使用するのが無難に思います。