
Lumina Image2.0:日本語プロンプトも可能!@ComfyUI

Lumina Image2.0は最近、ComfyUIが対応した画像生成AIモデルです。
ここにGithubリポジトリがあります。
<特徴 by GPT>
①多言語プロンプト対応の強化
リポジトリの解説によれば、英語だけでなく日本語や他言語でも比較的スムーズに生成ができるよう設計されています。
②細部の表現力とスタイル変換機能
Lumina-Image-2.0は人物の顔や建築物など、細部の表現が向上しているとされています。特に顔部分の歪みや手指などが従来モデルより自然に表現できるように工夫が加えられています。
※Githubリポジトリだとリアル系の画像もありますが、生成した範囲だとプロンプトの問題もあるのかもしれませんがアニメ調のものしか出力されませんでした。。。
<ComfyUIでの使用方法>
モデルは以下のところに配置します。テキストエンコーダーなどオールインワンモデルの様です。
以下に配置します。
ComfyUI/models/checkpoints
Paperspaceで使用する方は以下のコマンド(一時ディレクトリ用)
!curl -L -o /tmp/ComfyUI/models/checkpoints/lumina_2.safetensors "https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/resolve/main/all_in_one/lumina_2.safetensors?download=true"
以下のワークフローを読み込んで実行します。
これは公式のものをそのままjsonファイルにしたものです。

流れとしてはモデルから「モデルサンプリングオーラフロー」、CLIP、empty SD3 latentからKサンプラーに向かうという流れでシンプルです。
プロンプト内容を見ると以下のような感じです。
You are an assistant designed to generate superior images with the superior degree of image-text alignment based on textual prompts or user prompts. <Prompt Start> a cute anime girl with massive fennec ears mouth open and a big fluffy tail long blonde hair and blue eyes wearing a maid outfit with a long black dress and a white apron splattered with purple liquid with white gloves and black leggings sitting on a large cushion in the middle of a kitchen in a dark victorian mansion drinking a glass with a galaxy inside
これを見ると、最初の<Prompt Start>までは、システムプロンプトで指示を入れているようです。
サンプラーはEular、スケジューラーはsimple、CFGの設定もできますね。
少し触ってみた館では、比較的多くのサンプラーとスケジューラで生成可能な印象です。

<生成速度>
1024x1024の解像度で24秒かかりました。PaperspaceのA4000の使用
デフォルトの「torch compile」ノードを使用したところ、初回は時間がかかりましたが、その後の生成は18秒程度に短縮しました。
WaveSpeedはエラーで使えませんでした。
対応が進めばいい感じの速度になりそうですね。

<プロンプトを日本語にした生成例>


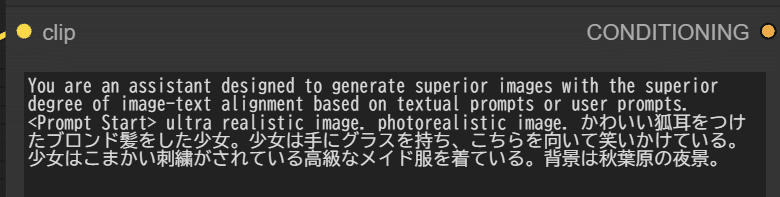

ということで、日本語のプロンプトにも比較的よく対応する感じのようです。
これはかなりうれしいですね。英語になおさなくて良いという点からは、プロンプト面からはとっつきやすいモデルと感じました。
テキストエンコーダーは、「Gemma-2-2B」ですので、NSFWワードは無視されるようです。
このページの下の方を見ていたら、このページ自体が「Open source」と書いてありました。
リンクをクリックするとGithubリポジトリに移動して、そこで付け加えたりできるようです。

面白い試みですね。