
「Omost canvas editor」を使用して、2個の違う色のりんごを描いてみる@Omost/ComfyUI

ComfyUIのOmostはかなり頻繁に更新されて、色々な機能が追加されています。最初に紹介した記事と比較すると数日しか経過していませんがGithubのページの記載がだいぶ変わっています。
「Region condition」についての記載が非常に増えているのが特徴です。
これは、LLMに推論させた後に出てくるcanvas画像で、全体の中のある部分の画像の内容を指定するものを言うようです。
その機能を試してみるために簡単?なものから始めて見ることにしました。
Omostで生成するパターンと、JSONをGPTにプレーンテキストに直して通常生成したものを比較してみます。
※今回はpony系のモデルのみ使用していますので、他のモデルの場合は結果が異なる可能性があります。また、seed値を固定せず生成しているので比較のところは画像は違うものになっています。
<OmostのLLMのプロンプトに入れたお題>
「テーブルの上に赤色と青色のリンゴが1つずつとなりに並んでおいてある」
JSONをGPTで変換した、Stable diffusion 用のプロンプト
On a table, there are a red apple and a blue apple placed side by side. The red apple is on the right and the blue apple is on the left. The table has a white table carpet, and a small dish is placed on top of the apples. In the background, there are walls and furniture, but they are not detailed, leaving the environment around the table unclear. The focus of the image is the contrast between the red and blue apples, highlighting their beauty and natural freshness. The red apple is depicted with a fresh, smooth skin, making it look delicious and vibrant. The blue apple, equally fresh, has a smooth skin and a bright, appealing appearance. The white table carpet enhances the overall beauty of the scene, providing a natural and fresh expression.
※最初、日本語でプロンプトで入力したところ、JSONの中身が「\u30c6\u30fc\u30d6\u30eb\u306e\u4e0a\u306b\u8d64\u8272\u3068\u9752\u8272\u306e\u30ea\u30f3\u30b4\u304c\uff11\u3064\u305a\u3064\u3068\u306a\u308a\u306b\u4e26\u3093\u3067\u304a\u3044\u3066\u3042\u308b」のような文字が入ったプロンプトが生成されました。
これだと、以下の上の様にまったく反映されませんでした。

気を取り直して、英語でプロンプトを入力して生成されたものです。
複数個のリンゴを出力してくれるようになりました。

「Omost canvas editor」を開いてみます。「Omost load canvas conditioning」のところで、右クリックして選択する開くことが出来ます。以下のようなのが出てきました。

これで、左側の色を選択すると、それに該当するプロンプトが出てきます。
これは一番上のものです。全体を反映する内容っぽいですね。他の項目部分の色が薄くなっています。

2番目はテーブルについてのプロンプトが記載されていました。

3番目が赤いリンゴについての記述です。

4番目が青いリンゴについての記述です。

右側のキャンバス部で、それぞれの図形の大きさや配置を変えることが出来ます。これだと、リンゴが重複している印象がありますので、分けてみます。
以下のようにしてみました。

これで、closeを押して、再度生成!!
ウーム。。。それほど効果がないのか、生成画像の方はそれほど変化が出てきませんでした。。。。
青いリンゴというのを学習していないのかという問題になりそう。

さらに、気を取り直して、「Dense diffusion」の方も作成してみました。
上から「Dense diffusion」「Omost通常」「通常生成」の順です。
ここまでくると、最初のリンゴの数は関係なくなってきています。。

「Dense diffusion」で生成される画像は、さきほど修正した様に左側に赤い感じの画像となり、右側に青っぽいものの画像が生成されています。
使用したチェックポイントが「青いリンゴ」を学習していないせいか、上手く出ていない可能性も考えられます。

別のチェックポイントを使用してみました。
別なリアル系モデル①
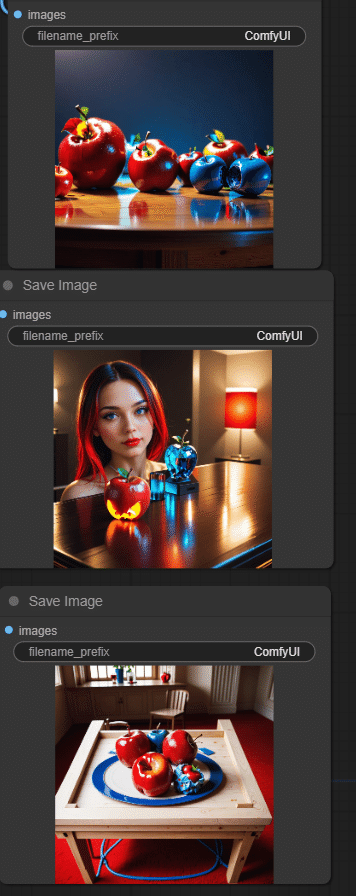
別なリアル系モデル②
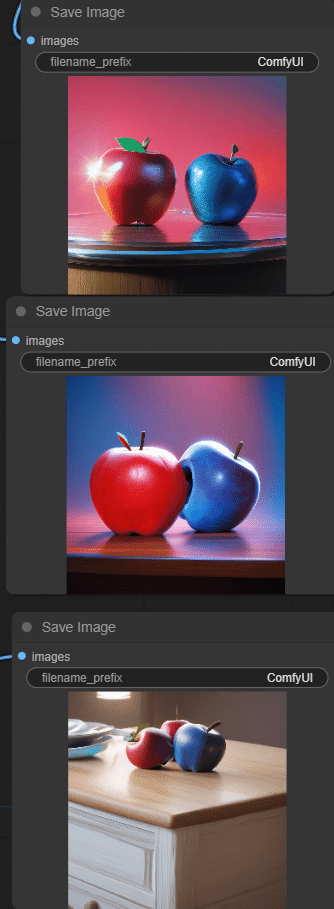
別なリアル系モデル③

※他のアニメ系モデルも3つほど使用しましたが、最初のものと同じ様な結果になったので割愛しています。
ということで、「Omost canvas editor」を使用してみた結果、以下のようか感じの印象でした。
①まずは、モデルが学習していない、もしくは弱いものは反映されにくい
②リアル系モデルの方が今回の検討だとOmostへの反応が良かった
リアル系モデルにおけるOmost canvas editorの反映度のイメージ
「Dense diffusion」>=「ComfyUI-Area」>>「通常生成」
アニメ系モデルにおけるOmost canvas editorの反映度のイメージ
「Dense diffusion」>>「ComfyUI-Area」>=「通常生成」
という感じでした。
使用するプロンプトの内容などによっても変わるとは思いますが、参考まで。
今回の結果を見てみると、Omostへの反応がいまいちなチェックポイントを使用していると「なんか効果ない気がする」みたいな印象になるのかもしれません。
<追記>
アニメ系モデルについては、上記の反応のよいリアル系モデルとマージするとOmostへの反応が良くなりました。
さらに難しめのプロンプト「One red apple and one yellow apple and one green apple are placed next to each other on the table.」
で、下のようにcanvasを調整してみました。
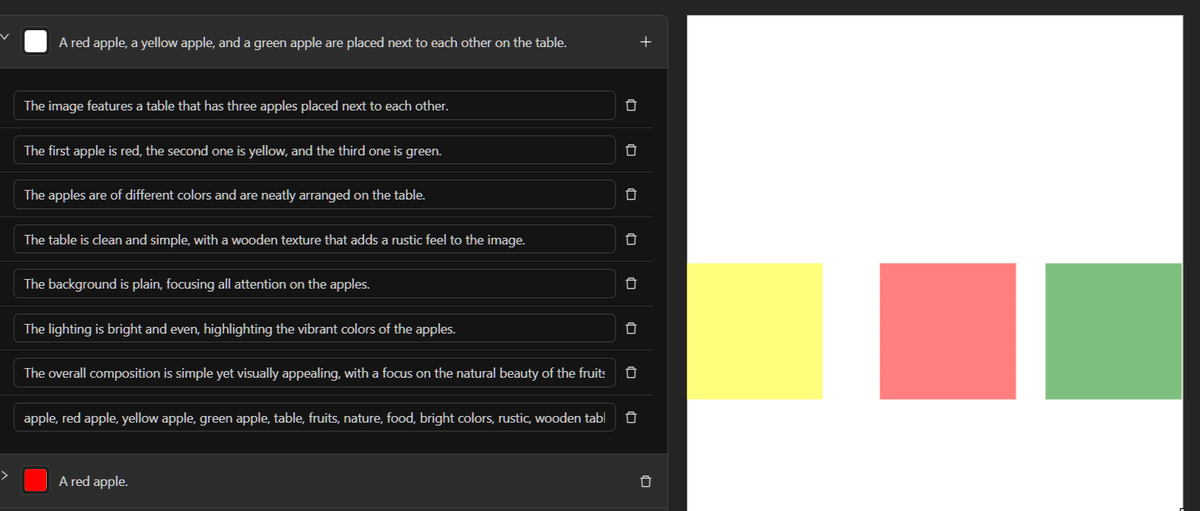
下の様な画像が出ました。

モデルのマージを行っている際に経験したこととしては、「Dense diffusion」よりmこ、「ComfyUI-Area」に反応の良いパターンがあった点です。
上の画像は「ComfyUI-Area」で生成したものになります。
この記事が気に入ったらサポートをしてみませんか?