
OmniGen-ComfyUIを試した話

OmnigenというのがComfyUIでも使用できるようになったらしいです。
しかし、実際に私の環境で使用しようとするとエラーで最初は動きませんでした。
Omnigenの簡単な紹介と、エラーの解決方法について記事にしています。
VectorSpaceLab/OmniGen: OmniGen: Unified Image Generation. https://arxiv.org/pdf/2409.11340
<Omnigenの解説:HPより>
Omnigenは、テキストから画像生成、特定の被写体を基にした生成、アイデンティティを保持した生成、画像編集、画像を条件とした生成など、さまざまなタスクに対応できる統合型の画像生成モデルです。Omnigenは追加のプラグインや操作を必要とせず、テキストプロンプトに応じて入力画像内の特徴(必要なオブジェクトや人のポーズ、深度マッピングなど)を自動で認識します。
⇒コントロールネット的なのも含めてこれ一つでいろいろとやってみますよということっぽいです。
<動作エラーについて>
Githubページに以下のような記事が出ており、エラー報告がいくつか出ています。
①公式ワークフローを読み込むといきなりテイストプロンプトの部分が赤くなって使えない問題
⇒以下のものをカスタムノードにGitcloneして追加すると解決しました。
②リンクにあるトラブル的なやつ
実際に動かすと、どうもスクリプトから自動的にHuggingfaceからモデルをダウンロードしようとするのですが、うまくいかない場合にエラーが出るようです。
これはモデルを別にダウンロードして配置すると解決します。
Shitao/OmniGen-v1 at main
以下の使いそうなやつを全て配置します。
配置先ディレクトリ
/ComfyUI/models/AIFSH/Shitao/OmniGen-v1/
<Omnigenのモデルをダウンロードして配置のコマンド:一時ディレクトリ指定>
import os
# ダウンロード先ディレクトリの設定
target_dir = "/tmp/ComfyUI/models/AIFSH/Shitao/OmniGen-v1/"
os.makedirs(target_dir, exist_ok=True)
# ダウンロードするファイルのURLリスト
urls = [
"https://huggingface.co/Shitao/OmniGen-v1/resolve/main/config.json?download=true",
"https://huggingface.co/Shitao/OmniGen-v1/resolve/main/model.safetensors?download=true",
"https://huggingface.co/Shitao/OmniGen-v1/resolve/main/special_tokens_map.json?download=true",
"https://huggingface.co/Shitao/OmniGen-v1/resolve/main/tokenizer.json?download=true",
"https://huggingface.co/Shitao/OmniGen-v1/resolve/main/tokenizer_config.json?download=true"
]
# 各URLからファイルをダウンロードし、指定ディレクトリに保存
for url in urls:
filename = url.split('/')[-1].split('?')[0]
filepath = os.path.join(target_dir, filename)
!wget -O "{filepath}" "{url}"VAEのダウンロード問題
Omnigenのモデルを配置して実行すると、VAEのダウンロードが開始されますが、これもうまくいかずエラーが起きました。
以下のところから、config.jsonとdiffusion_pytorch_model.safetensorsを配置します。
stabilityai/sdxl-vae at main

配置先/ComfyUI/models/AIFSH/Shitao/OmniGen-v1/vae
<コマンド>
import os
# ダウンロード先ディレクトリの設定
vae_dir = "/tmp/ComfyUI/models/AIFSH/Shitao/OmniGen-v1/vae"
os.makedirs(vae_dir, exist_ok=True)
# ダウンロードするファイルのURLリスト
vae_urls = [
"https://huggingface.co/stabilityai/sdxl-vae/resolve/main/config.json?download=true",
"https://huggingface.co/stabilityai/sdxl-vae/resolve/main/diffusion_pytorch_model.safetensors?download=true"
]
# 各URLからファイルをダウンロードし、指定ディレクトリに保存
for url in vae_urls:
filename = url.split('/')[-1].split('?')[0]
filepath = os.path.join(vae_dir, filename)
!wget -O "{filepath}" "{url}"これで公式のワークフローを動かすと動作しました。
注意点:生成にかなり時間がかかりました。
実際にOmniGenを動かしてみた
txt2imgだけのワークフロー
この単純なのが動作するのにここまで手間がかかるとは。。。。

txt2img+画像のワークフロー


後半のもので分かったのは、イメージを使用する場合は、以下のようにプロンプトで指定する必要があるようです。「image_1」みたいな。
The woman in image_1 waves her hand happily in the crowdこの解説には以下の本家のサイトを参考にすると良さそうです。
OmniGen/inference.ipynb at main · VectorSpaceLab/OmniGen
参照するイメージ(image_1)の人物を指定すると切り取ってくれるみたいなことの様です。
上のプロンプトだとimage_1に配置した画像の女性を切り取って、後半のプロンプトの内容を反映させてくれるみたいな感じと思われます。
上のサイトにあった、Image-conditional Generationという項目を試してみました。
コントロールネットみたいなこと
Generate the depth map for this image: <img><|image_1|></img>.本家の画像参照プロンプトと少し違うので、以下のような感じにしています。
Generate the depth map for this image_1.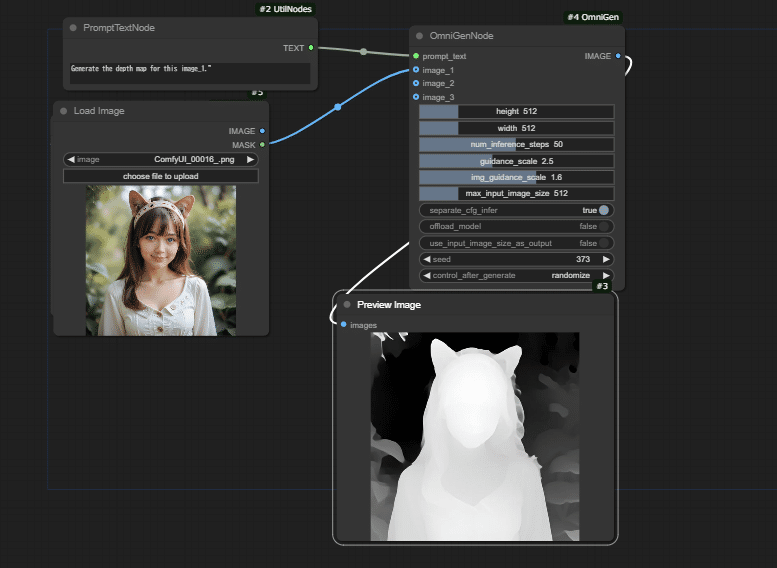
Depth画像を参照して画像を作る
例に挙がっているおじいさんにする内容をおばあさんに変更したもの。
Following the human pose of |image_1, generate a new photo: An elderly woman wearing a red-framed glasses stands dignified in front of an elegant villa. Her gray hair is neatly combed. She is dressed warmly in a fitted coat over a sweater. The beautiful park behind her.
<結論>
とても興味深い技術でしたが、もともとのOmniGenのモデルが15GBあるためか、生成にとても時間がかかります。
VRAM消費を抑えるには、画像サイズなどを小さくするのが良いとのことで、入力や出力のサイズを512にしても、paperspaceのfree A4000レベルだと2分程度は待つ必要がありました。
それならコントロールネットで良いのでは。。。。となる可能性もありますが、生成速度が改善されて、プロンプトの組み方が効率的になれば使いやすいのかもと思いました。