
Text-generation-webuiを試してみた&LLMモデルの探し方(我流)

Text-generation-webuiに関連した導入話
上のサイトがText-generation-webuiのgithubサイトです。
今回の記事はChat with RTXを触ってみて調べてみたら面白そうだったけど、とっつきにくいところもあるなといった内容です。
Text-generation-webuiのサイトを見ると2023年3月頃からあり、そこそこ前からあります、インストール方法など調べるとそのころの記事が出てくると思います。現在も頻繁に更新されているので機能自体は追加されて行っているもののようです。
今回は、ローカルでの運用ですが、youtubeでやっている内容が達成できればと思っています。
今回の記事は毛色を変えるためにStablediffusionなどの画像生成AIの用語とかに例えられる範囲で表現出来ればと思っています(主観目線)。
下のサイトはとても勉強になるサイトで、そもそもLLMとは?と言うところから今回のアプリの導入まで細かく書かれています。
今回の記事を書くにあたってとても参考になりました。
LLMはざっくりいうと、画像生成のチェックポイントに相当するものみたいです。ただ、容量は画像生成のよりは大きいものが多いです。
さて、Text-generation-webuiは、「テキスト生成に関してのAutomatic1111」を目指すというコンセプトのもののようです。
UIがAutomatic1111に近いこともありとっつきやすいかもしれません。
以下はサイトにあった対応するモデルの種類のようです。
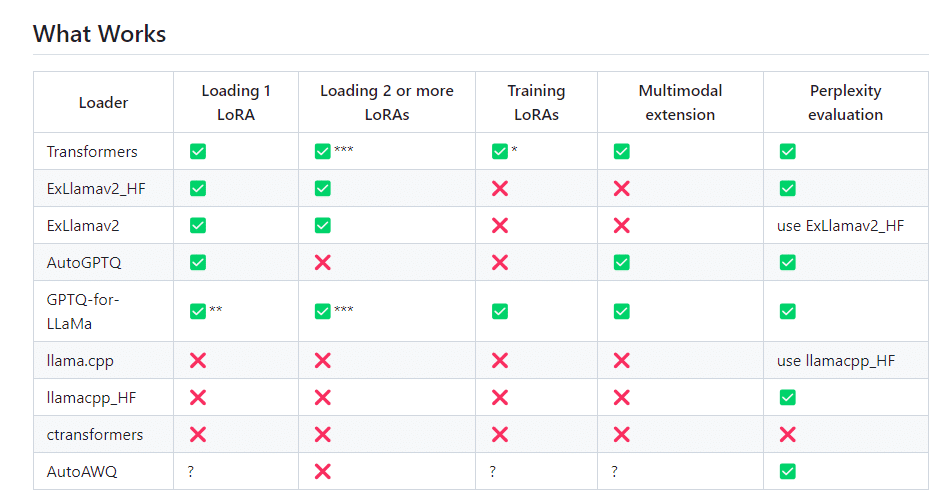
これは、Civitaiとかでモデルを検索する際の「SD1.5」とか「SDXL」みたいな違いなのかなと思います。
インストール方法:簡単
HPのリンクより「text-generation-webui-main」というzipファイルがダウンロードできます。22MB。
「Run the start_linux.sh, start_windows.bat, start_macos.sh, or start_wsl.bat script depending on your OS.」とありますので、「start_windows.bat」をクリックします。
そしたらコマンドプロンプトが立ち上がりました。
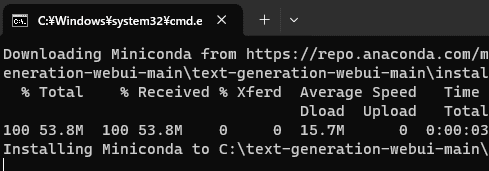
途中で質問が来ます(人によりそう)ので、放置していても処理が進まない可能性があります。
少し時間がかかりますがインストール出来ました。URLを開くとwebuiになります。
「字が小さい」と思われた方はいるかと思いますが、通常のブラウザと同様に拡大、縮小が出来ますのでそれで良いかと。
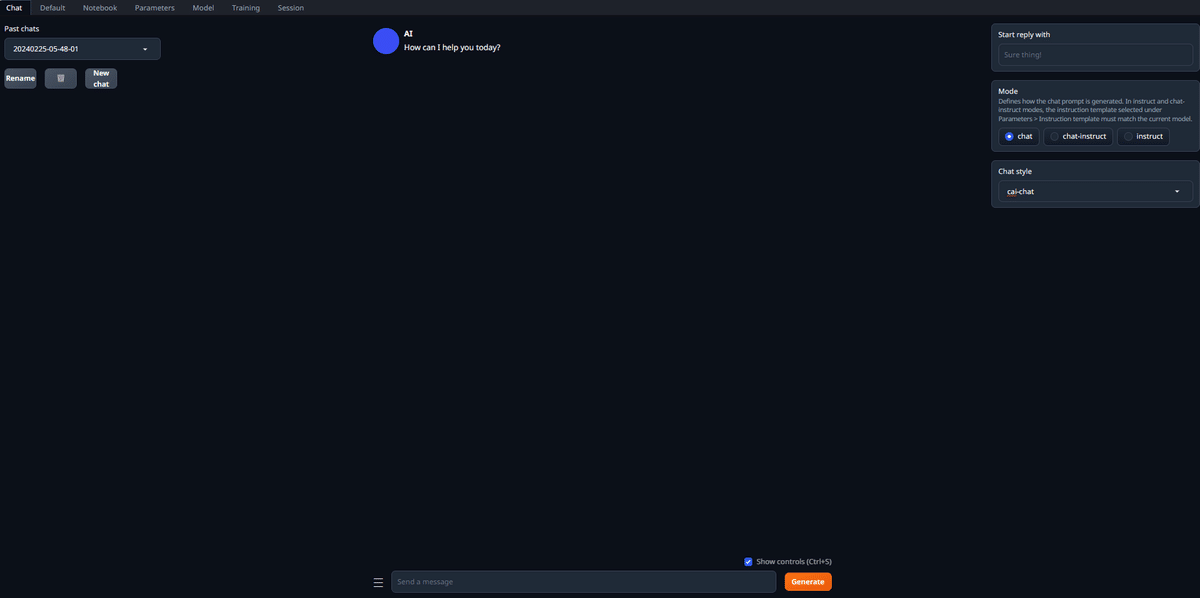
この画面が画像生成AIでいうと、画像生成を行う部分にあたるかと思います。画像生成では当然モデルとかVAEとかセットが必要になりますね。
終了するには、ブラウザを閉じるのと、コマンドプロンプトを閉じる必要があります。これはローカルのStablediffusionと同じですね。
モデルのダウンロード方法:これも簡単
この段階ではモデルが入っていないので、モデルのダウンロードします。
ダウンロードの仕方自体は簡単で、「Model」タブに行き、右下のところにURLを入れるとダウンロードしてくれるようです。
Stablediffusionでいうと、拡張機能のmodel downloaderに相当するものでしょうか。
残念ながらcivitaiとかでやっているようなファイルだけダウンロードしてフォルダに入れればOKとかはうまくいかなさそうな感じです。
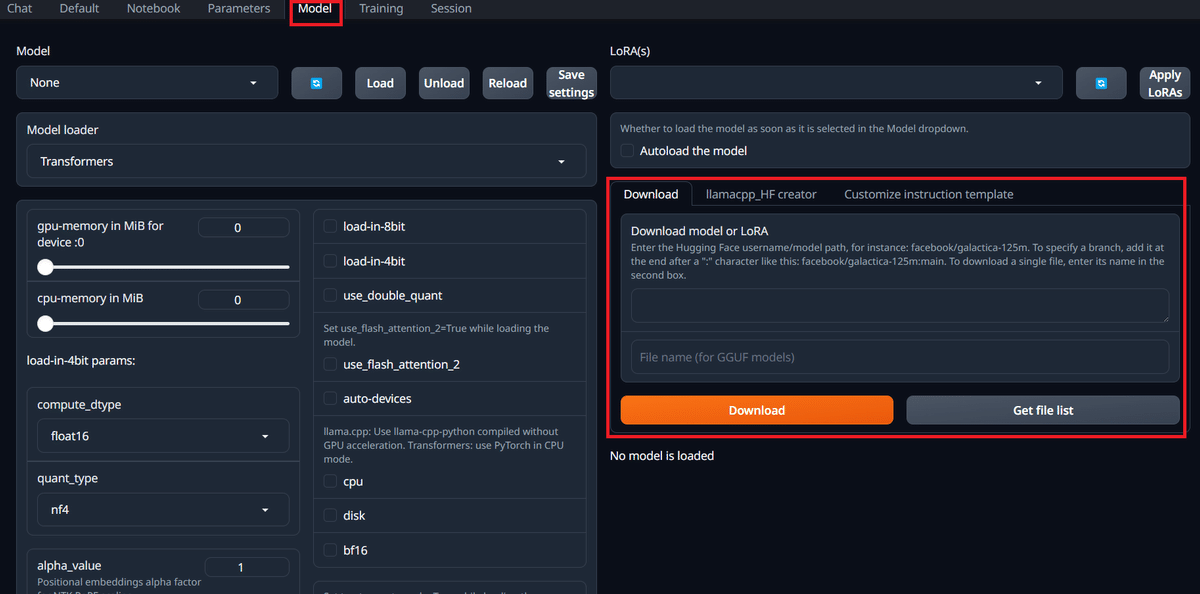
モデルの探し方① モデルの型
さて、今回、「text-generation-webui」をやってみる際の大きな関門となったのがこのモデル選びになります。
画像生成だとCivitaiで生成画像を見て、いい感じのやつを使うとかできますが、テキスト生成だと何を参考にしたらよいかわからないですね。
私も初学者なので詳しくは分かりませんが、同じモデルでも色んな段階に分かれて公開されている様です。これは画像生成では見ない感じですね。どれでも画像生成出来るので。学習前、学習済、調整済みたいな感じです。
例えばチャットの会話をしたい場合とかはそう言う調整的なのがされているのがある様です。
instructとか最後についてます。ついてないのでも会話できるとか書いてあるやつもあり、それも良いのかもしれません。
なので、最初はこの文言がついてるモデルか会話対応しているものを選ぶのが得策です。
モデルの探し方② 基本
最初に紹介したyoutubeにモデル探しのコツについて話しており、そこでは2段階での検索について言及していました。
まずは、下のランキングサイトで最近のものやスコアが高いやつとかから目をつけます。
これは適宜更新しているので、内容は時期によって変わります。
モデル名をクリックするとサイトに詳細が出てくるので、このアプリでも対応しているのを確認したり、特徴を確認したり出来ます。
スコアの高いやつは性能が良いので、上から順が良い気がします。civitaiのフィルターで評価高い順みたいな感じなのでしょうか。
次にhuggingface内で、そのモデルについてのインストラクトモデル、検閲無しモデルを検索してあるか探します。
と言う流れが基本的なものかと感じました。
今の流れの中で、あと2点、モデル選びに関わる内容について簡単に説明しておきます。
モデルの探し方③ 検閲無しモデル
これは、通常のモデルの場合、検閲事項の質問に対して拒否する様に調整されています。
前回記事で、Chat with RTXで拒否された感じですね。
その対策として、有志でそれを取り除いた検閲無しモデルと言うのがあります。下のサイトが、検閲無しモデルを作成された方が記載した内容です。どんな感じで作ってるかとか詳しく書いてます。
モデルの探し方④ 日本語対応
英語を基本としたモデルが多く、それらを運用する際に英語になってしまうのですが、日本語を学習したモデルもあります。こちらだと翻訳作業無しで行え、より自然な日本語でのやり取りが可能になりますが、検閲無しモデルはあまり無い気がします。
モデルの探し方⑤ モデルの容量を確認する
モデルの容量が大きすぎると時間がかかるのと、上手く動かない可能性があります。
例えば、検閲なしモデルを探すことにし、以下のサイトの中から選んでみることにしました。
サイトを開くと以下のようになっています。一応、ダウンロード数が多い順に並んでいるようです。
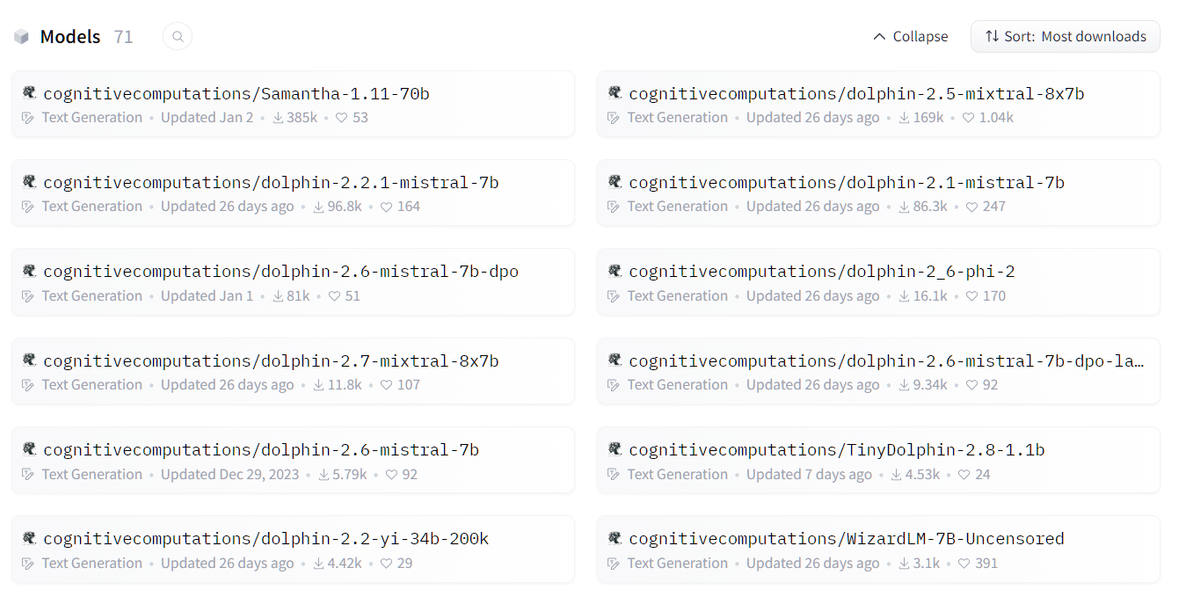
一番人気のやつを開いて、ファイルを確認してみます。
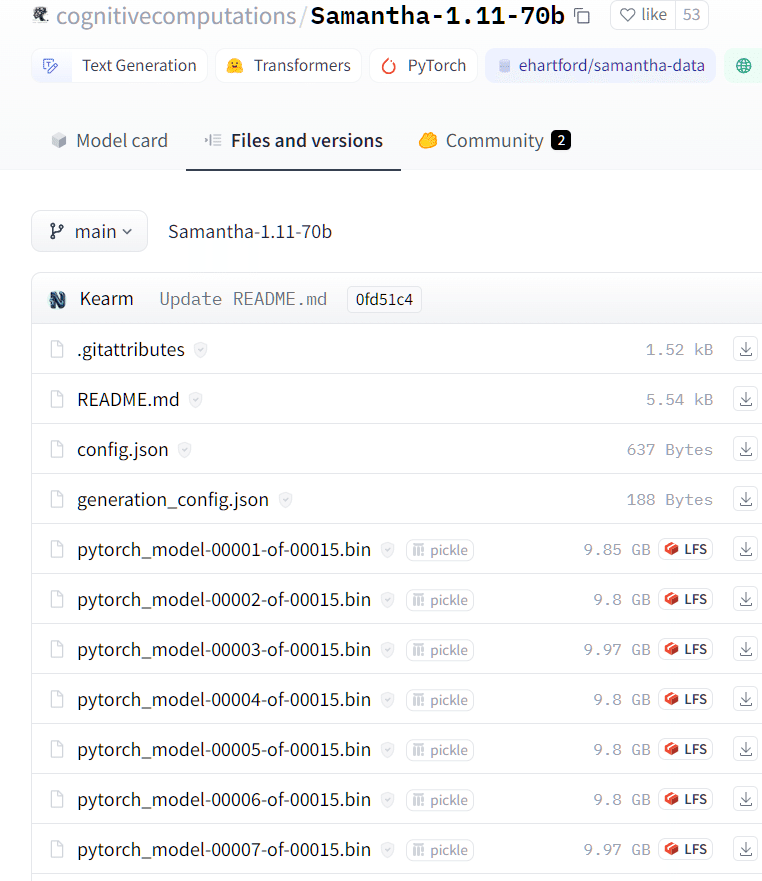
たくさんファイルが並んでいて、9GB越えがずらっとありますね。数えるとこれが14個ありました。Stable diffusionのイメージでいくと、この中の一つを選ぶのかなと思われるかもしれませんが、どうも全てのようです。
ということで、このモデルは140GBぐらい。
また、「GGUF」というモデルのパターンもあるようですが、その場合はStablediffusionのチェックポイントと同じように一つのファイルのみでOKのようです。※以下のサイトの方がGGUFのモデルを出しています。
※モデルについては以下の記事も参照してください。
ということで、最後のモデル選択はある程度軽量なやつから試していくというのが良い気がします。
例えば、3番人気のものを見てみます。
これだと合わせて15GBぐらいになりそうな感じです。先ほどの10分の1ですね。Stable diffusionのモデルとは規模感が違いますね。
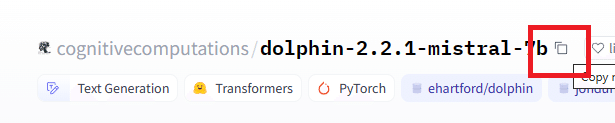
ここをコピーする。
モデルフォルダにペーストしてダウンロードを開始する。
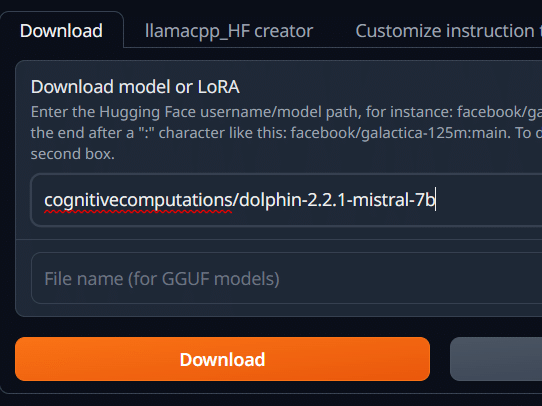
コマンドプロンプトを見るとダウンロードの経過を見ることが出来る
ダウンロードが終了したら「ロード」を押す。
他に設定が必要かもしれませんが、これで動いたので。

「Chat」に移動して会話してみます
※今回は初回のモデルのダウンロードが途中で止まっていたため、モデルのみ追加でダウンロードしました。
チャット開始前の設定について
そのまま会話しても良いですが、事前に設定しておくと想定した会話が成り立つ可能性が高まると思われます。
これは「パラメーター」タブの「キャラクター」というところにあります。
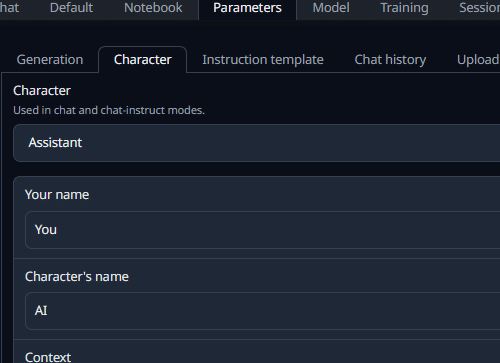
以下のサイトで、分かりやすく設定方法が記載されています。
本家サイトのwikiにも説明があります。
<以下訳>
キャラクター
「モード」の下で「チャット」または「チャット指示」が選択されたときに、チャットタブで使用されるキャラクターを定義するパラメータ。
キャラクター: 保存されたキャラクターから選択するためのドロップダウンメニュー、新しいキャラクターを保存するための(💾ボタン)、選択されたキャラクターを削除するための(🗑️)があります。
あなたの名前: プロンプトに表示されるあなたの名前。
キャラクターの名前: プロンプトに表示されるボットの名前。
コンテキスト: 常にプロンプトの最上部にある文字列。これは切り取られることがなく、通常はボットの性格や会話の重要な要素を定義します。
挨拶: ボットの開始メッセージ。設定されている場合、新しいチャットを開始するたびに表示されます。
キャラクター画像: ボットのプロフィール画像。適用するには、(💾)をクリックしてボットを保存する必要があります。
あなたの画像: あなたのプロフィール画像。すべての会話で使用されます。
ということで、例えば「ロールプレイ」の対話を希望する場合は、コンテキストのところにいろいろと設定を入れていくということになるようです。
<GPTさんの説明>
ロールプレイの対話を可能にするためのチャットのコンテキストを作成する際は、参加者(あなたとAI)のキャラクター設定、会話の背景、お互いの関係性、および会話が進行する環境について明確かつ詳細に記述することが重要です。これにより、AIが与えられた設定に基づいて適切な応答を生成し、リアルなロールプレイ体験を提供できるようになります。
コンテキストの要素
キャラクター設定:
あなたのキャラクター: あなたの役割、性格、特技、目的など。
AIのキャラクター: AIが演じるキャラクターの役割、性格、特技、目的など。
関係性:
あなたとAIキャラクターの関係(友人、ライバル、師弟関係など)。
背景設定:
物語が展開する世界や環境の詳細(歴史的時代、架空の世界、現代都市など)。
物語の現在地点や出来事に至るまでの経緯。
会話の目的:
このロールプレイ対話を通じて達成したいこと(情報を得る、問題を解決する、キャラクター間の関係を深めるなど)。
<GPTさんに作成してもらうと楽かも>
例としてこんなのを挙げてくれました。英語にして名前とか変えて貼りつけてみました。
コンテキスト:
あなたは、中世の魔法世界に住む若き魔法使いです。長年の研究の末、伝説の魔法書を探し出す手がかりをつかみました。しかし、その魔法書を手に入れるためには、禁断の森を旅し、古代の試練を乗り越えなければなりません。
AIのキャラクター:
AIは、あなたの旅の案内役である賢い狐、レナードです。レナードは森の秘密と古代の魔法に精通していますが、時には謎めいた言葉であなたを試すこともあります。
関係性:
あなたとレナードは、この危険な旅を共にする運命共同体です。レナードは、あなたが魔法書を見つける手助けをすることを約束しましたが、その代わりにあなたはレナードが探している失われた宝物を見つけ出すことに同意しました。
挨拶:
レナード: "さあ、若き魔法使いよ。禁断の森の入口に立つ君には、どんな試練が待ち受けているか、想像もつかないだろう。しかし心配するな、私が君の案内人だ。賢明な選択をし、時には心を強く持たねばならない。準備はいいか?"
チャットの仕方
英語で入力かな?と思っていましたが、日本語でも対応してくれているようです。
拡張機能のgoogle翻訳を入れているおかげかもしれません。相手の言葉は翻訳のため口調にそこそこゆらぎがありますが。。。。


ということで、少し触ってみた印象として、キャラクター設定みたいなのがこの対話のキモになると感じました。
今回の対話は、向こうがこちらを導く役割でしたので、こちらの頼みを聞いてくれなくてちょっとイラっとしました(笑)
GPTsを作成する過程に似ているので、その感覚が良いのかもしれません。
ただ、機能的にはGPTの方が良いので、求めるレベルを考慮に入れて使い分ける感じが良さそうです。