
Stable Diffusion webUIでcontrol netをやってみよう

この記事は Stable Diffusion WebUIを使用して、ControlNetをやってみたよ!という内容になります。
目標設定
レベル設定は以下
Level1 WebUIを構築できる(ネットで調べてやってみよう)
Level2 WebUIのtext to image で、画像を出してみる
Level3 WebUIのimage to imageで、画像を編集してみる
Level4 WebUIのcontrol netを使用して、画像を作成してみる。(この記事)
使うモデルは以下だけ
使うLoRAはなし。
ここからはControlnetの準備
stable-diffusion-webui-forgeは、Controlnetがビルトインされているので、インストールは不要である。だけどモデルは必要だ。
モデルのダウンロードは以下。
https://github.com/Mikubill/sd-webui-controlnet/wiki/Model-download.
google colabでwgetする場合、以下の場所にダウンロードしよう。
/content/stable-diffusion-webui-forge/models/ControlNet

では、いってみましょう!

Cannyを使ってみよう
Cannyの基本機能
線画抽出: Cannyを使用すると、元の画像からエッジを抽出し、線画を生成します。これにより、ユーザーは元の画像の構造を保持しつつ、新しいデザインを作成できます 。
自由な色塗り: 抽出した線画を基に、色を自由に変更することが可能です。これにより、アーティストは自分のスタイルに合わせた作品を簡単に作成できます 。
フムフム!
textToImageの画面でも大丈夫だろうか。
元の画像を準備して、線画を抽出してみよう。

Enableをチェックして、Cannyを選択
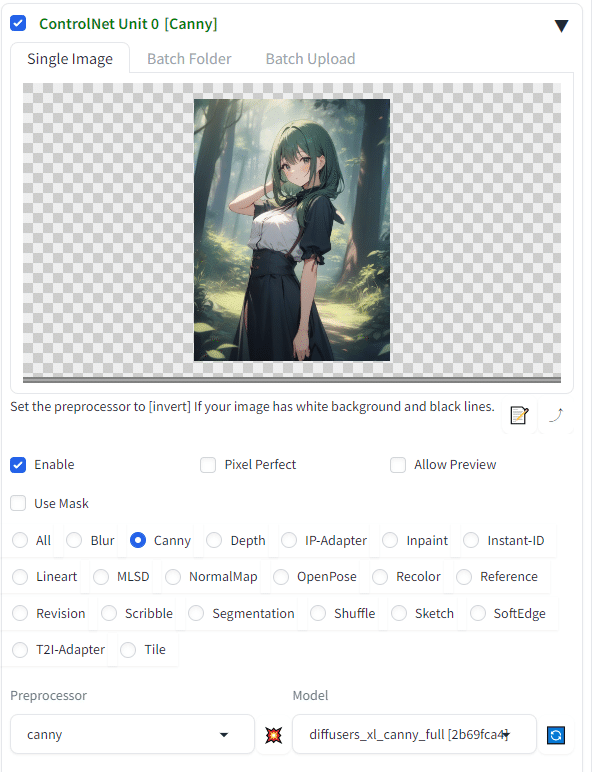
これだけでOK。あとは、森の中の緑髪の女の子。という情報だけをプロンプトに入れて、Generateしてみよう。

OpenPoseもやるべきでしょう
単純なフリーイラストでは、なかなかポーズ抽出ができなかった。
ので

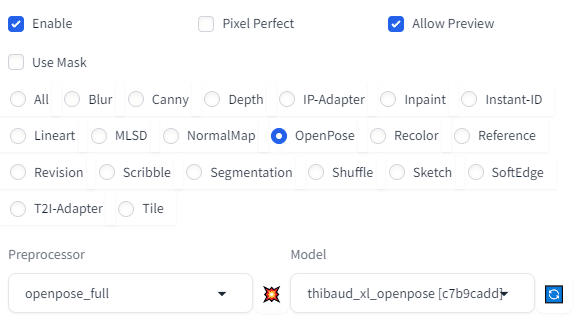
そして、ハジケマークをクリックすると


オープンポーズエディターを入れることで、自在に編集できます。

もっと自由に絵を出すには?
Stable DiffusionのControlNetにおいて、CannyやOpenPose以外にも多くのプリプロセッサが利用されています。これらのプリプロセッサは、画像生成の際に特定の情報を抽出し、生成プロセスを補助する役割を果たします。以下に、よく使われるプリプロセッサを列挙し、それぞれの特徴を説明します。
よく使われるプリプロセッサ一覧
Canny
概要: 画像のエッジを抽出するためのプリプロセッサ。輪郭を強調し、生成される画像のディテールを向上させます。Lineart
概要: 線画を抽出するためのプリプロセッサ。特にアニメスタイルのイラストや線画の生成に適しています。OpenPose
概要: 人体のポーズを抽出するためのプリプロセッサ。人物の姿勢や動きを正確に捉え、リアルなポーズを生成するのに役立ちます。Depth
概要: 画像の深度情報を抽出するプリプロセッサ。3D感を持たせた画像生成に利用され、奥行きのある表現が可能です。Segmentation
概要: 画像を異なるセグメントに分割するプリプロセッサ。オブジェクトの識別や背景の処理に役立ちます。Normal Map
概要: 法線マップを生成するプリプロセッサ。表面の凹凸を表現し、リアルな質感を持つ画像生成に寄与します。Colorization
概要: モノクロ画像に色を付けるためのプリプロセッサ。特に古い写真やアート作品の復元に利用されます。Inpaint
概要: 画像の特定の部分を修正または塗りつぶすためのプリプロセッサ。欠損部分を補完する際に使用され、画像の一貫性を保つのに役立ちます。Reference
概要: 参照画像を基にして、生成する画像のスタイルや内容を調整するプリプロセッサ。特定のアートスタイルを模倣する際に有効です。Scribble
概要: 手書きのスケッチや落書きを基にしたプリプロセッサ。簡単な線画から詳細な画像を生成するのに役立ちます。Text
概要: テキスト情報を基に画像を生成するプリプロセッサ。特定のテーマやコンセプトに基づいた画像を作成する際に使用されます。Pose
概要: 人物のポーズを指定するためのプリプロセッサ。OpenPoseと似ていますが、より簡易的なポーズ指定が可能です。Edge
概要: 画像のエッジを強調するプリプロセッサ。Cannyと似ていますが、異なるアルゴリズムを使用してエッジを抽出します。Super Resolution
概要: 低解像度の画像を高解像度に変換するプリプロセッサ。画像のディテールを向上させ、より鮮明な結果を得ることができます。
うーんなるほど。
お読みいただきありがとうございました。

これにて、レベル4は卒業。
いよいよ、ComfyUIに行ってみよう!
ではまた。