
Stable Diffusion WebUI を使ってみよう(image to image)

この記事では Stable Diffusion WebUIを使用したimage to imageについて、やってみたよという内容になります。
目標設定
レベル設定は以下
Level1 WebUIを構築できる(ネットで調べてやってみよう)
Level2 WebUIのtext to image で、画像を出してみる
Level3 WebUIのimage to imageで、画像を編集してみる(この記事)
Level4 WebUIのcontrol netを使用して、画像を作成してみる。(未作成)
という具合ですね。
使うモデルは以下だけ
使うLoRAは以下だけ
Trigger Wordsは lineart,LineAniAF

では、いってみましょう。
前回の学習から線画を出してます。

img 2 imgのタブに移動すると、Txt2imgのプロンプトは共有されていません。
txt2imgで使用したプロンプトをコピーして、アミカケ部分にもととなる画像をドラッグしてみましょう。
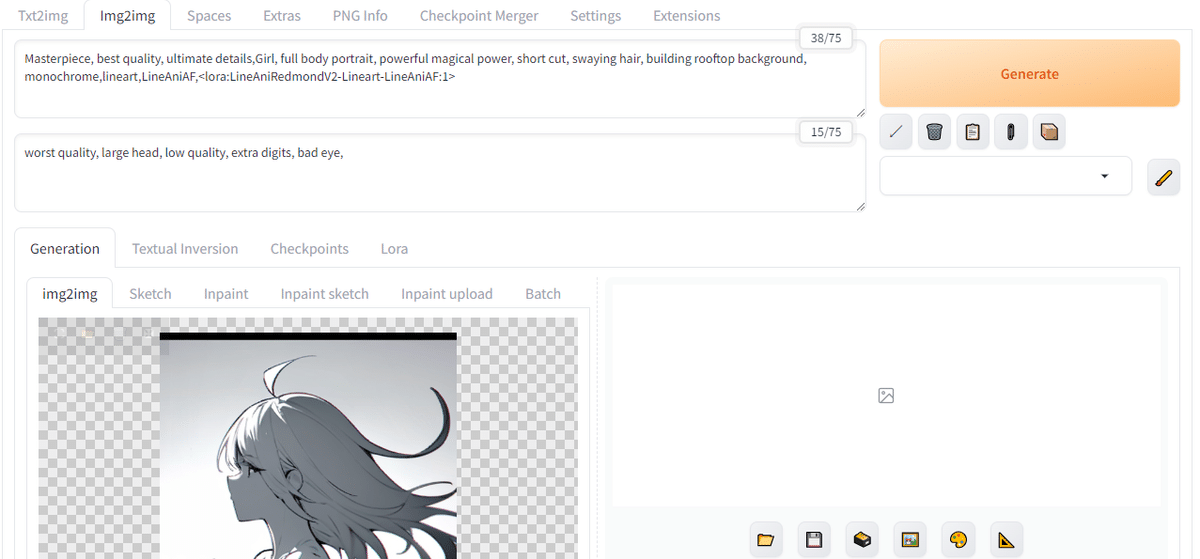
しかし何をさせたいですか?
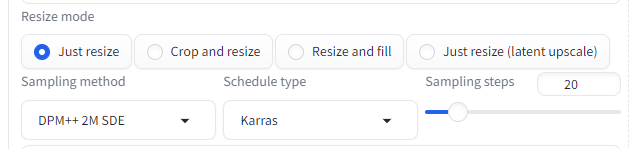
イメージをもとに・・・こんなことができます。
Just Resize
説明: 元画像をそのまま引き伸ばして新しいサイズにします。元の画像の比率を保たず、単純にサイズを変更します。
使用例: 画像のサイズを単純に変更したい場合に適しています。
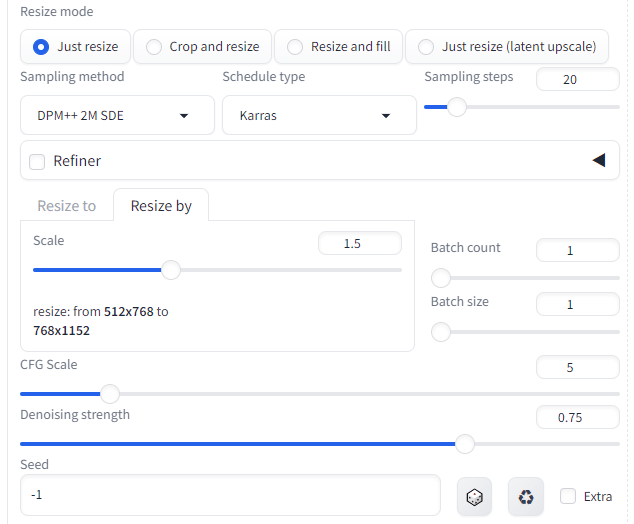


悪くないですね!
しかし、縦横比を1:1で依頼したいなあ。とサイズ指定すると

Crop and Resize
説明: 縦横比を保ちながら、元画像の一部を切り取り、拡大します。これにより、重要な部分を強調することができます。
使用例: 特定の部分を強調したい場合に有効です。
ただラジオボタンを移動しただけでは。JustResizeとやっていることがかわらない。

しかし、少女の腰まで写したい。
Resize and Fill
説明: 元画像のサイズを変更し、足りない部分をAIが生成して補完します。これにより、全体のバランスを保ちながら新しい要素を追加できます。
使用例: 新しい要素を追加したい場合や、特定のデザインを維持したい場合に適しています。

もっとこだわりたい。
Just Resize (Latent Upscaler)
説明: 異なるアップスケーラーを使用して、元画像をサイズ変更します。これにより、異なるスタイルや質感を持つ画像を生成できます。
使用例: 高品質な画像を生成したい場合に利用されます

[デフォルトのJust Resizeは単純にサイズを変更するだけで、解像度が低下する可能性があります。]
と、ChatGPTは言うが、デフォルトのJust ResizeもそれなりにAIによる変化があったようです。なので、ハルシネーション(AIの嘘)かもしれないし、仕様が変わっているかもしれない。好みの問題かもしれない。
Denoising strength
デフォルトでは0.75であるが、
少ないほど元画像に近い。大きいほど、元画像から離れる。

0.3にしてcrop and resizeすると
元画像が保たれる。

resize and fillもしてみる

0.95なんかにすると……


Sketch
別タブにいきます。
画像をドラッグしてみましょう。
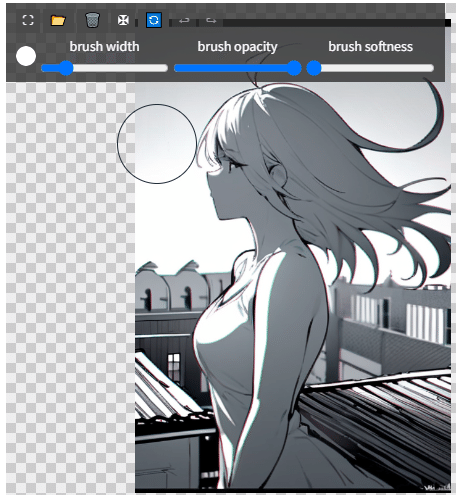




AIの恐ろしさを感じますね。


そんなのはプロンプトで変えるのでしょう。
ゼロから絵を描いてみましょう。Sketchで。
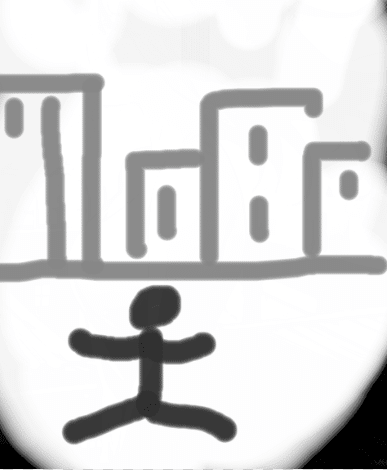

なるほどねえ、じゃあインペイントもみてみましょう。

Inpaint
別タブにいきます。
すでにできている画像の一部を消して再生成させる。
ような説明をどこかで見ました。そいつは良い。
ドラゴンライダーを用意しました。

右手が崩れているので修正してもらいたいですね。



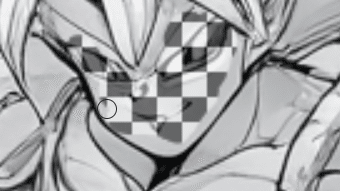
プロンプトに表情指定を追加する。


画像を拡張したいな。街を襲うというプロンプトを追加して、街を襲わせたい。
inpaintのタブのままで
Poor man's outpainting
を選んでみましょう。
Scriptから
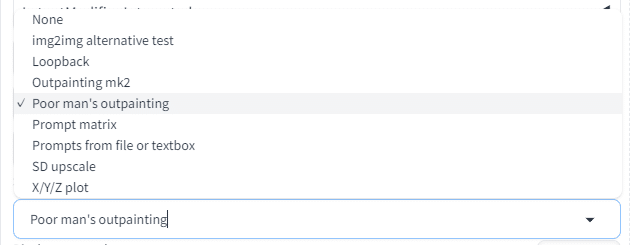
256ピクセル下方向に、拡張しよう!
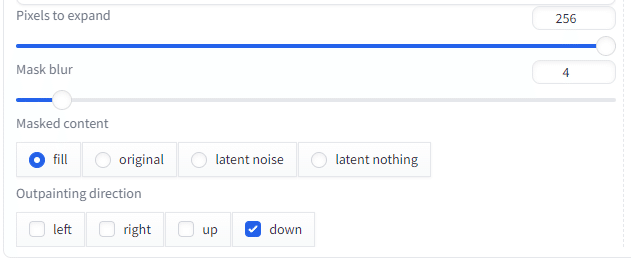
そして、プロンプトに「眼下の街を襲う」という英語文字列を追加しましょう。

解像度を上げたりするのも、img2imgでやりやすそうですね。
結局プロンプトを入れる必要はありますので、メモを残しておきましょう。
今回はここまで、
お読みいただきありがとうございました。
いよいよ次回はControlNetです。
