
Stable Diffusion WebUI を使ってみよう(Level2)

Stable Diffusion WebUIを、Google Colabで使用してみています。
npaka様の下記記事を参考に。
目標は、いろんな上級者さんがやっているような、nodeで様々なツールを利用できそうなComfyUIなのですが、ちょっとね、レベル高いネ。
まずtext to imageと、image to imageをさわって、その後control netをさわって、その後Comfy UIに進みましょう。
と、思っています。ので、この記事はLevel2としてみました。
目標設定
暫定的に、やってみる目標を考えると
Level1 WebUIを構築できる(ネットで調べてやってみよう)
Level2 WebUIのtext to image で、画像を出してみる(この記事)
Level3 WebUIのimage to imageで、画像を編集してみる①(未作成)
Level4 WebUIのcontrol netを使用して、画像を作成してみる。(未作成)
こんな感じになるのではないだろうか。と思っています。
Comfy UIがやりたければもうすぐにComfy UIをやるべきでないか。
という意見もありそうですが……ある程度、Level4までできたらConfy UIにいこうと思っています。機能を知ってれば戦えるだろう。
hugging faceやcivitaiでモデルを探して、モデルをダウンロードしよう!という学習も、飛ばしていきます。
今回は、モデルの選定に時間をかけず、AnimagineX3.1で、VAEも同ページからダウンロードします。
SDXL1.0のモデルだそうです。
ちょっとわけがわからなくて面白そうだったのでmidjourney Manga Art StyleというLoRAを使ってみましょう。StableDiffusionなのにMidjourneyですって?初心者のひとに説明するとき、イライラされますね。
くっきりLoRAの効き具合をチェックするために、線画も出せるようにしてみたいですね。
ではいってみましょう。
ここでは、XLのUIだけに言及します。
Diffusion in Low Bitsは、量子化ビットを低ビットで実行させることで、メモリ効率や処理速度を向上させる手法です。
低ビットで質の向上が見込めますが、時間がかかるというトレードオフです。
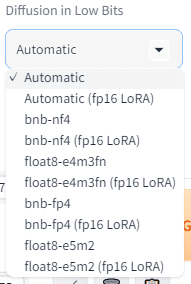
GPU Weightsとは、GPU上で処理されるディープラーニングモデルの重みを指し、計算リソースやメモリ効率を最大限に活用するために最適化されています。

プロンプトとネガティブプロンプトを入れてGenerateを押下するだけでも絵はでる。

プロンプトは世の中に豊富に出回っているので、
モデル、CheckPointによってキーワードとなる単語が違うので、あまり覚える意味があるとは思えないなあ・・・
Generateボタンの下には、

Generate下のメモボタンで、それらをプロンプトに反映させることもできる。
便利に使おう。
さて、この時点でもうLoRAはいらないじゃないという気分になってくる。



Generate中に、中断かスキップかというボタンが出る。
非活性に見えるが、どちらも効く。

次にいきましょう。
Generationタブ
Sampling Stepsは、ノイズ除去回数。多ければキレイ、だけどこれ以上やっても変わらないという数値が出てくる。
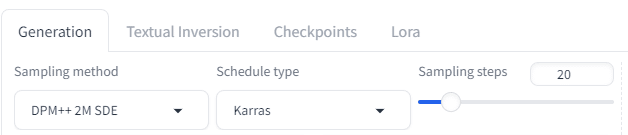
Sampling methodとSchedule typeは、ノイズ除去アルゴリズムのメソッドとタイプということ。これ以上は追々知って行こう。
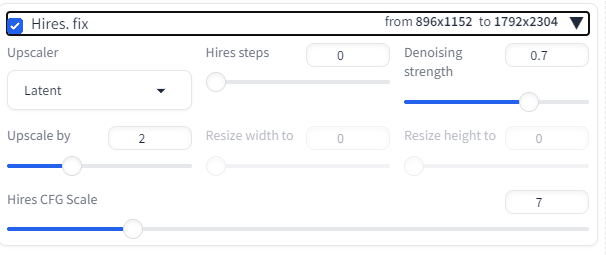
Hires.fixは高解像度化するのだが。。。
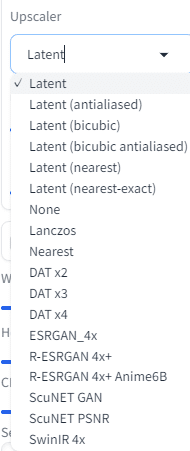
Upscalerにもいろいろある。
Latent: 画像の潜在空間を利用して、解像度を向上させる手法。
None: 特に処理を行わないオプション。
ESRGAN_4x: 高度な超解像技術を用いて、4倍の解像度に拡大する手法
など。
事前にどの画像を高解像度にしたいか、選びたいのでためしにSeed値を入れよう。

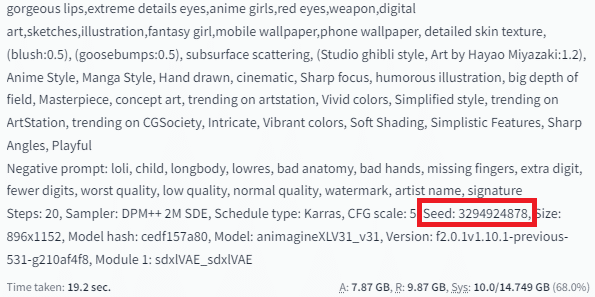
Hiresチェックいれたら
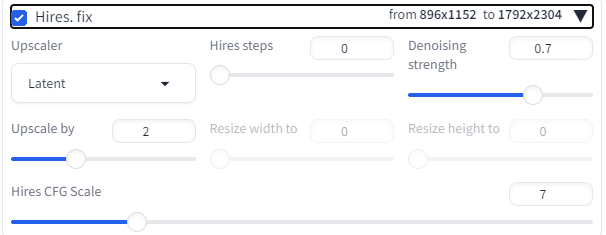
1792*2304のサイズになる。が、顔は崩れる。

何度かパラメータ変えてやってみましたが、単純なアップスケールはこの機能ではダメぽいですね。ただ高画質を出力させるために使いましょう。


じゃあ、LoRAをあててみよう。
[ロ/ラ]という発音なのか[ロ\ラ]という発音なのか、それはその人が関西に住んでいるか関東に住んでいるかで変わる。(たぶんね)


では、線画のLoRAをあててみる。
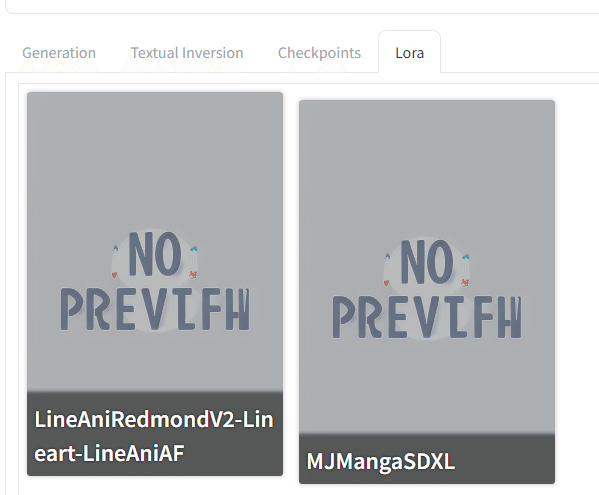


LoRAそれぞれの「トリガーワード」が必要なのである。
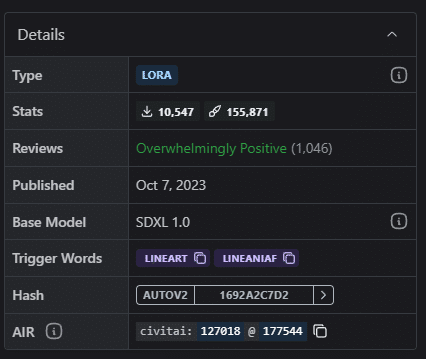
つまり今回の線画については、lineartとLineAniAFがトリガーである。いれてみましょう。



白黒に、なったと、いえますね!
では、もうひとつ用意したLoRA,MJ_MANGAのトリガーワードは
[mj manga]ですね。

いってみましょう!

これにて、LoRAはもう大丈夫。
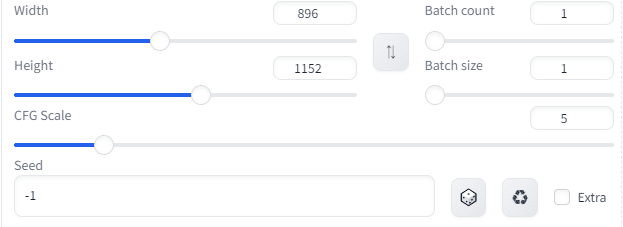
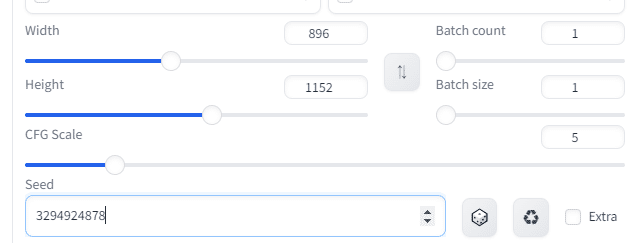
ちなみに、画像のサイズはWidthとHeightで行う。
Batch countで、同時に何枚出すかを選ぶ。
Batch sizeでも同時に何枚出すか選ぶ。
バッチサイズを2、バッチカウントを3に設定すると、合計で6枚の画像が生成される



しかし、どちらがどう崩れるか、というのは環境によるらしい。
CFG Scaleは、テキストがどれくらい影響を与えるかという具合。
大きいほど忠実。とはいえ、崩れるバランスもある。
先ほどまでのデフォルトが5


これにてtext to imageの概要はおわり。
これ以降、これらの機能をみてみよう。

読むだけなのはつらいので、挿絵もどうぞ。
ControlNet Integratedの概要

定義: ControlNetは、Stable Diffusionにおける条件付き生成を強化するための拡張機能で、特定のポーズや構図を指定することができます。
目的: より精密なイラストや画像を生成するために、ユーザーが指定した条件に基づいて生成プロセスを調整します。
これは、別途ControlNetのモデルが必要そうなのであとまわしです。

Dynamic Thresholdingの主な機能
CFGスケールの調整: 通常、CFGスケールを高く設定すると、生成される画像が不自然になることがありますが、Dynamic Thresholdingを使用することで、これを防ぎます。
柔軟な設定: ユーザーは、スケールを20や25などの高い値に設定しても、画像の整合性を保つことができます。
チェックボックスをオンにすると使えます。とのこと。やってみましょうか。
しかし、「最適なパラメータを探しましょう」とのこと。
テキスト通りになっているか、という判定も難しい。初心者のうちは、CFGはデフォルトのままでかまわない。という場合が多そうだ。

FreeU Integratedの概要
定義: FreeUは、Stable Diffusionの生成プロセスにおいて、B1、B2、S1、S2の4つのパラメータを設定することで、画像の画質を簡単に向上させる機能です2。
目的: 画像生成の品質を向上させることを目的としており、特に細部のディテールや色合いの改善に寄与します。
SelfAttentionGuidance Integratedの概要
定義: SelfAttentionGuidanceは、Stable Diffusionの生成プロセスにおいて、自己注意メカニズムを活用して画像の品質を向上させる技術です。
目的: 画像生成時に、特に細部のディテールや色合いを強調し、よりリアルで魅力的な画像を生成することを目指しています。

PerturbedAttentionGuidance Integratedの概要
定義: PerturbedAttentionGuidanceは、画像生成時に注意メカニズムを調整し、生成される画像の多様性を高める技術です。
目的: 画像生成プロセスにおいて、特定の特徴やスタイルを強調しつつ、全体的な品質を向上させることを目指しています。
Kohya HRFix Integratedの概要
定義: Kohya HRFixは、Deep Shrink Hires.fixとも呼ばれ、高解像度の画像を生成する際に使用される技術です。
目的: 画像生成時に、解像度を高めつつ、生成過程での破綻を最小限に抑えることを目指しています。

LatentModifier Integratedの概要
定義: LatentModifier Integratedは、画像生成の潜在空間を操作することで、生成される画像の特性を調整する機能です。
目的: より細かい生成が可能で、ユーザーが求める特定のスタイルやテーマに合わせた画像を作成することを目指しています。
MultiDiffusion Integratedの概要
定義: MultiDiffusion Integratedは、画像を細かく分割し、それぞれの領域を個別に描画することで、高解像度の画像を生成する機能です。
目的: 低VRAM環境でも高解像度の画像を生成できるようにし、ユーザーのクリエイティブな表現をサポートします。

StyleAlign Integratedの概要
定義: StyleAlign Integratedは、ユーザーが求めるスタイルに基づいて生成された画像を調整・微調整する機能を提供します。
目的: 特定のアーティストのスタイルやテーマに沿った画像を一貫して生成し、視覚的な整合性を保つことを目指します。
Stable Diffusionのスクリプトの概要
定義: Stable Diffusionのスクリプトは、画像生成プロセスを制御するためのコードや命令の集まりです。これにより、ユーザーは特定のスタイルやテーマに基づいた画像を生成できます1。
機能:
変数の設定: スクリプトを使用することで、生成する画像のスタイルや内容を変数として指定できます。
パラメータの調整: 画像の解像度、色合い、スタイルなど、さまざまなパラメータを自由に設定できます。
スクリプトの使用方法
スクリプトのインストール:
ダウンロードしたスクリプトをStable Diffusionのスクリプトフォルダに移動します。このフォルダは通常、プログラムのインストールディレクトリ内にあります。
これらも使いたくなった時に使いましょう。

お読みいただきありがとうございました!
明日は、Imge To Imageの現状やってみた記事を書きます。
なんか、覚えようとするとムズカシイネ。
絵を出そう!とすると簡単に感じるかもしれない。
なんでもやってみないといけませんね。