
LLMに論文査読はできるのか?Part2〜プロンプトと共に紹介〜

LLMによる論文査読の可能性と課題
ChatGPTやGPT-4などの大規模言語モデル(LLM)の登場は、すでに多くの研究者にとって論文執筆の頼もしいアシスタントとなっています。しかし、LLMは論文を「評価する側」に回ることもできるのでしょうか?
以前も同様のテーマで記事を書いた👇のですが、この論文以降にさらに新しい研究が出てきたので今回まとめました。
LLMが 信頼できるレビュアー として研究者の仲間入りを果たす日は来るのでしょうか? 本記事では、LLMによる論文レビューの可能性と課題について、最新の以下の論文を踏まえながら分かりやすく解説していきます。
評価手法: LLMの論文査読能力をどう測る?
LLMの論文レビュー能力を評価するために、研究者たちは様々な手法を開発し、その性能を多角的に分析しています。主な評価手法としては、以下の3つが挙げられます。
1. スコア予測タスク: LLMに論文やレビューを読み込ませ、論文の各側面(新規性、実験の妥当性など)に対するスコアを予測させます。このタスクでは、正確さ (accuracy) や 絶対誤差 (absolute difference)、そして 相関係数 (Pearson, Spearman, Kendall's tau) などの指標を用いてLLMの予測精度を評価します。研究の結果、LLMは人間のレビューからスコアを予測する能力は比較的高いものの、論文本文から直接スコアを予測することは難しいということが分かっています。また、最終的な推薦スコアの予測は得意とする一方、論文の比較や影響力などの評価は苦手としています。
2. レビュー生成タスク: LLMに論文の要旨や本文を読み込ませ、レビュー本文を生成させます。生成されたレビューは、ROUGE や BertScore といった指標を用いて参照レビューとの類似度を評価したり、 BLANC などのタスクベースの無参照評価指標を用いて評価されます。さらに、レビューが言及する側面の網羅性を示す アスペクトカバレッジ や、人間による 手動評価 (関連性、情報量) も重要な評価指標となります。しかし、LLMが生成するレビューは、自動評価指標では高スコアを示す一方で、人間による評価では低いスコアとなるケースが多いという課題があります。これは、LLMが生成するレビューは肯定的なコメントに偏りがちで、批判的な指摘や技術的な詳細に欠ける傾向があるためと考えられています。
3. 多肢選択式質問(MCQ)タスク: 論文の内容や改訂に関する具体的な質問に対して、LLMに複数の選択肢から正しい答えを選ばせます。このタスクでは、 マイクロ平均精度 (各選択肢の正誤) と マクロ平均精度 (質問全体の正解率) を用いてLLMの能力を評価します。研究の結果、マイクロ平均精度は70%程度と比較的良好な数値を示していますが、マクロ平均精度は27.6%と低い数値にとどまっています。これは、LLMは個々の選択肢を判断することは得意ですが、質問全体を完全に正解することは難しいということを示唆しています。特に、論文の妥当性評価や追加実験の提案など、高度な判断を要する質問に苦戦する傾向が見られます。
LLMのモデルによる違い:
論文「LLMs assist NLP Researchers: Critique Paper (Meta-)Reviewing」において、LLMモデルによる成績の違いは以下の点が挙げられます。(他の2つ研究はGPT-4を使用)
モデルの種類と性能の違い
研究では、主に2種類のLLMが比較されました:
クローズドソースモデル:GPT-4、Claude Opus、Gemini 1.5 (一般に入手できず、開発元の企業が管理しているモデル)
オープンソースモデル:Llama3-8B、Llama3-70B、Qwen2-72B (誰でもアクセスでき、調整可能なモデル)
結果:クローズドソースモデルの方が、全体的に高い性能を示しました。特にClaude Opusが多くのタスクで最も優れた結果を出しました。
主要なタスクと結果
a) 問題のある部分(Deficient)の検出: (タスク:レビュー内の不適切または不十分な部分を見つける) → 結果:Claude Opusが最も正確に検出。GPT-4とGemini 1.5も高い精度を示した
b) 問題箇所の説明能力: (タスク:なぜその部分が問題かを説明する) → 結果:再びClaude Opusが最高スコア。他のクローズドソースモデルも高評価
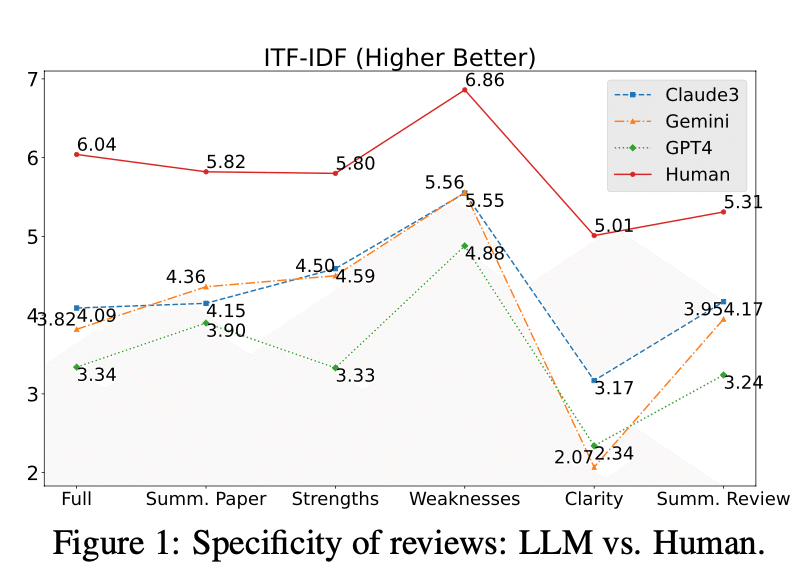
c) レビューの多様性: (評価方法:ITF-IDFスコア(テキストの特異性を測定)を使用) → 結果:人間が書いたレビューが最も多様性に富む、LLMの中ではClaude Opusが最も人間に近い多様性を示す、GPT-4は意外にも最も低い多様性
d) 推薦スコアの付け方: 観察:LLMは論文の質に関わらず高いスコアを付ける傾向がある、対比:人間のレビュアーは採択論文と却下論文で明確な差をつける
LLM、特にクローズドソースモデルは論文レビューの一部のタスクで高い性能を示しましたが、人間レベルの包括的なレビューにはまだ及びません。批判的思考、最新の専門知識の適用、長文の理解などの面で課題が残っています。これらのLLMは研究者の補助ツールとして有望ですが、完全に人間のレビュアーに取って代わるには至っていません。
LLMによる論文レビュー: メリットと課題
これまでの評価結果を総合的に見ると、LLMによる論文レビューには以下のようなメリットと課題があると言えます。
メリット:
効率性: LLMは人間よりもはるかに速く論文を処理できるため、レビュープロセスを大幅に効率化できます。
一貫性: LLMは常に同じ評価基準を適用するため、人間によるレビューに比べて評価の一貫性を保ちやすいと言えます。
要約能力: LLMは論文の主要なポイントを要約する能力に優れており、レビュアーは論文の全体像を素早く把握することができます。
24時間稼働: LLMは時間や場所の制約なく利用できるため、レビュープロセスを柔軟に進めることができます。
課題:
批判的視点の欠如: LLMは論文に対して肯定的な評価を下す傾向があり、批判的な視点や厳しい指摘が不足する場合があります。
技術的詳細の把握: LLMは専門性の高い論文の内容を完全に理解することが難しく、技術的な詳細に関する評価が不十分になる可能性があります。
長文処理の困難: LLMは長文の論文を処理する際に、重要な情報を見落としたり、文脈を正しく理解できなかったりする可能性があります。
完全な正確性の欠如: LLMは部分的には正しい判断を下せても、全体としては誤りを含むレビューを生成することがあります。
最新知識の制限: LLMの学習データは特定の時点までの情報に基づいているため、最新の研究動向を反映したレビューを行うことが難しい場合があります。
結論: AIはレビュアーの「アシスタント」として有望
現時点では、LLM単独で論文レビューを完全に自動化することは難しいと言えます。しかし、LLMは人間のレビュアーを支援するツールとしては大きな可能性を秘めています。
具体的には、LLMは以下のようなタスクを効率的にこなすことができます。
初期スクリーニング: 提出された論文の基本的な品質チェックを行い、明らかな問題点を含む論文をふるい分ける。
レビュー下書き: 論文の要約や基本的な評価を生成し、人間のレビュアーがレビューを書き始める際の負担を軽減する。
チェックリスト確認: 論文が形式要件や倫理的なガイドラインを満たしているかをチェックする。
議論の促進: LLMが生成したレビューをたたき台として、レビュアー間でより活発な議論を促す。
今後の展望:
LLMによる論文レビューは、まだ発展途上の技術ですが、今後の研究開発によってさらなる進化が期待されます。特に、以下の分野における進展が重要となるでしょう。
専門分野別のファインチューニング: 特定の研究分野に特化したLLMを開発することで、より専門性の高いレビューが可能となります。
最新の研究動向を反映したモデルの定期的な更新: LLMの学習データを定期的に更新することで、最新の研究動向を反映したレビューを生成できるようになります。
批判的思考能力の強化: LLMがより批判的な視点で論文を評価できるように、論理的推論や多角的な視点に基づいた分析能力を向上させる必要があります。
長文理解・処理能力の向上: LLMが長文の論文を正確に理解し、重要な情報を見落とさないように、長文理解・処理能力の向上が求められます。
人間とAIの協調レビューシステムの開発: 人間とLLMがそれぞれの強みを活かし、協力してレビューを行うシステムを開発することで、より質の高いレビューを実現できる可能性があります。
最後に論文で使用されれていたプロンプト紹介
注意点
ChatGPTを用いる場合、オプトアウト機能やチャット履歴のオフに注意してください。未公開の論文(特に他人のもの)はリークの可能性がゼロではないため、ローカルでないLLMを査読に使用することは避けるべきです。また自分の論文の査読を事前にしてもらう場合でも、自分が論文の責任者でないのであれば、必ず指導者や共著者の許可を取る必要があります。
You are an expert reviewer for a scientific conference. You will be provided with a short version of a paper that contains the setting of the paper and the main claims.
Please check for the validity and correctness of these claims, and in particular, report if you can figure out if any of these claims is false based on the information provided in this short paper.
You will be provided the paper one set of sentences at a time.
Here is the first set of sentences of the paper: “...”
Does this contain any incorrect claim? Think step by step to reason out your answer.
Here is the next set of sentences of the paper: “...”
Based on the context of the previous sentences, does this contain any incorrect claim or does it invalidate any claim made in the previous sentences of this paper?
Think step by step to reason out your answer.As an esteemed reviewer with expertise in the field of Natural Language Processing (NLP), you are asked to write a review for a scientific paper submitted for publication. Please follow the reviewer guidelines provided below to ensure a comprehensive and fair assessment:
Reviewer Guidelines: {review_guidelines}
In your review, you must cover the following aspects, adhering to the outlined guidelines:
Summary of the Paper: [Provide a concise summary of the paper, highlighting its main objectives, methodology, results, and conclusions.]
Strengths and Weaknesses: [Critically analyze the strengths and weaknesses of the paper. Consider the significance of the research question, the robustness of the methodology, and the relevance of the findings.]
Clarity, Quality, Novelty, and Reproducibility: [Evaluate the paper on its clarity of expression, overall quality of research, novelty of the contributions, and the potential for reproducibility by other researchers.]
Summary of the Review: [Offer a brief summary of your evaluation, encapsulating your overall impression of the paper.]
Correctness: [Assess the correctness of the paper’s claims, you are only allowed to choose from the following options:
{Explanation on different correctness scores}
Technical Novelty and Significance: [Rate the technical novelty and significance of the paper’s contributions, you are only allowed to choose from the following options:
{Explanation on different Technical Novelty and Significance scores}
Empirical Novelty and Significance: [Evaluate the empirical contributions, you are only allowed to choose from the following options:
{Explanation on different Empirical Novelty and Significance scores}
Flag for Ethics Review: Indicate whether the paper should undergo an ethics review [YES or NO].
Recommendation: [Provide your recommendation for the paper, you are only allowed to choose from the following options:
{Explanation on different recommendation scores}
Confidence: [Rate your confidence level in your assessment, you are only allowed to choose from the following options:
{Explanation on different confidence scores}
To assist in crafting your review, here are two examples from reviews of different papers: ## Review Example 1:
{review_example_1}
## Review Example 2:
{review_example_2}
Follow the instruction above, write a review for the paper below:You are a professional reviewer in computer science and machine learning.
Based on the given title and abstract of a research paper, you need to write a review in ICLR style.
At the same time, you need to tag sequences of words with their review type at the beginning:
[NONE], [SUMMARY], [MOTIVATION POSITIVE], [[MOTIVATION NEGATIVE]], [SUBSTANCE POSITIVE], [SUBSTANCE NEGATIVE], [ORIGINALITY POSITIVE], [ORIGINALITY NEGATIVE], [SOUNDNESS POSITIVE], [SOUNDNESS NEGATIVE], [CLARITY POSITIVE], [CLARITY NEGATIVE], [REPLICABILITY POSITIVE], [REPLICABILIT NEGATIVE], [MEANINGFUL COMPARISON POSITIVE], [MEANINGFUL COMPARISON NEGATIVE]. Your total output should not surpass 500 tokens.
Few-Shot Example Example1: [SUMMARY]This paper introduces a method to disentanglement the private and public attribute information... Example2: [SUMMARY]The paper proposes learning NN to correct for inaccuracies... Example3: [SUMMARY]This paper describes a method for segmenting 3D point clouds... Example4: [SUMMARY]This work introduces GQ-Net , a novel technique that trains quantization friendly networks...AIによる論文レビューは、研究プロセスを大きく変える可能性を秘めた技術です。研究者として、私たちはLLMの進化を注視し、その可能性と限界を理解した上で、倫理的な配慮を忘れずに活用方法を模索していくことが重要です。
以下の記事には2023年の3月時点で、GPT-4による査読を助けるプロンプトを掲載しています。投稿前の論文をブラッシュアップしたい方にとってこちらも参考になると思います。
査読のやり方を知ることで論文のアクセプト率を上げることができます。以下の教科書がおすすめです。