Stable Diffusionの画像条件付けまとめ

Stable Diffusionの画像生成を画像によって条件づける方法をまとめていきます。といっても実装とかを全部見たわけではないので、多少間違っている部分もあるかもしれませんが、まあイメージはあってるっしょ。

手法の分類
画像の情報をUNetのどこに与えるかによって手法を分類します。とりあえず5つに分けてみました
Cross Attentionに与える:Prompt Free Diffusion, PFG, IP-Adapter
Self Attentionに与える:Reference only, FABRIC
その他の場所に与える:ControlNet, GLIGEN, T2I-Adapter
LoRAの重みを学習する:HyperDreambooth
あれ・・?もしかしてこの時点でたいていの人は脱落ですか。この辺の話は詳しくはSDXLのモデル構造に関する私の記事とか、hosikatさんの記事に書いてあります。
Cross Attentionに入力する手法

Cross Attentionは主にUNetにテキスト情報を与えるためのモジュールです。テキスト情報には、本来テキストエンコーダの出力を使いますが、この部分を置き換えることで、画像情報を入力します。
この区分全体の特徴としては、入力が画像の形状を保っていないことです。これによって入力した画像の構図がそのまま生成されるということが無くなり、より意味的な部分のみを反映した画像が生成できます。
Prompt Free Diffusion
プロンプトフリーというか使えません。使えるように応用することはできるかもだけど。

この手法ではSeeCoderという新たに提案されたネットワークを用いてテキスト情報を画像情報に完全に置き換えます。テキストプロンプトを入力する余地はないです。名前の通りプロンプトフリーであるというのは確かにメリットではあるんですが、プロンプトを一切に使えないというのはそれはそれでtxt2Imageモデルを使う意味があるのかと思っちゃいますけどね。サンプル画像を見る限り入力した画像に対する生成画像の忠実度はすごそうだと思いますけどね(使ったことないので知らんけど)。
huggingfaceにanything系などグレーなモデルのコピーを置いていたりとプロジェクトに倫理観がないことも特徴です。
Prompt Free Generation

名前被っとるやん。私が考えた手法です、といっても大したことはやっていなくて、wdtaggerの特徴量をtext_embに結合できるよう一層の線形層で変換(+トークン数の拡張)して、結合しているだけです。wdtaggerを使ったのは、よりアニメイラストの意味的な情報を抽出できると思ったからです。 こちらはPrompt Free Diffusionと違ってプロンプトを一緒に使えるので、スタイル変換等にも使えます。ただしUNet側には一切手を付けない手法なので、UNetが生成できない画像はどうやったって生成できないという限界があります(これはPrompt Free Diffusionも同じかも)。
IP-Adapter
IPとはたぶんimage promptの略です。いっぱんぴーぽーではない。

IP-AdapterはPFGと似てますが、テキスト情報と結合するのではなく、別々のCross Attentionに分けて二つを足すという構造になっています。テキスト側のCross Attentionを凍結して、画像側のCross Attentionのto_k, to_vを学習します。PFGと違ってCross Attention自体も学習できるため、より強力です。しかもこの学習によってテキスト側は変化しないので、元のモデルもあまり傷つけずに済みます。Cross Attentionを二回計算すると、生成時間が増えるのではと思う方もいるでしょうが、実はCross Attentionの計算時間は全体の内わずかであり、ほとんど変わりません。
ちなみにSDv1.5のIP-Adapterでは、なぜかSDv1.5に使うCLIPではなくSDv2で使うCLIPを使っています。同じCLIPを使うのが自然な気がしますが、かなり謎です。
発表後少したってIP-Adapter-plusというのが出てきました。CLIP特徴量を変換するモジュールを1層の線形層から複数のTransformer層に変更されたところが、大きな変化で、入力画像への忠実度が大きくあがっています。またCLIP特徴量も同じものではなく、隠れ状態の最後から2番目を使っています。これは構図情報も含んでいるので、plusでは構図もかなり忠実になります(これは良いんだか悪いんだか)。
論文に夜見れなの画像がでてきたりと著者の趣味がうかがえるところも特徴です。
Self Attentionに入力する手法
Self Attentionはkeyとvalueに自分自身を入力します。
敵を知り(Cross Attention)己を知れば(Self Attention)百戦危うからず。

Reference only
ここより詳しい記事がありますよん。

Reference onlyでは、まずimg2imgのように入力画像にノイズを付与してノイズを予測します。次にこの予測時の中間出力を保持しておき、生成時のkey, valueへの入力に結合します。ノイズを付与した入力画像のノイズ予測が必要なので、生成時間が1.5倍になります。(ポジティブプロンプト・ネガティブプロンプト・入力画像の3回分のノイズ予測が必要)Self Attentionのトークン数も増えるのでもっと増えるのか?
学習が不要なのが特徴ですね。使ったことないですけど、かなり強力みたいで、img2imgのような怖さがあります。
FABRIC
この手法は、画像条件付けの手法ではなく、強化学習によってより良い画像を作るための手法なんですが、Reference onlyの発展型なのでちょっと触れます。この手法はポジティブ側に良い画像、ネガティブ側に悪い画像を入れるReference onlyを使って生成します。そして新たに作った画像を評価して、今度はその画像が良い画像だったらポジティブ側に、悪い画像だったらネガティブ側に入れるみたいな感じのことを繰り返すことで最終的にめっちゃ良い画像ができるっぽいです。
強化学習的な手法を使っていますが、モデルの重みを学習するわけではないです。
Time Embeddingに入力する手法
time embeddingとは時刻(ノイズの大きさ)をUNetに教えてあげる部分です。ResNetへベクトルの形で入力され、画像の形にbroadcastされて足されます。

UnCLIP

UnCLIPは、time_embにCLIP画像特徴量を入力します。単に入力するのではなく、特徴量にノイズを付与して、付与したノイズの大きさとともに入力することで、多様性を確保しているみたいです。UnCLIP用に新たにモデルを学習する必要があり、モデルの構造も少し変わるため既存のLoRA等が使えなくなりあまり流行っていないですね。
Revision
RevisionはSDXLの公式Controlnet-LoRAと一緒に発表された手法です。実はSDXLではTime embedding側にCLIPテキスト特徴量が入力されます。それをCLIP画像特徴量に変えるだけです。UnCLIPと似てますがノイズを付与する部分はないっぽいです。ただし新しく学習する必要がありません。
Cross Attentionに作用しないので、テキストを入れるとそれに結構引っ張られてしまうみたいですね。空文で生成するとそこそこ忠実になるらしい。
ControlNet

作ってみたが全然わかりやすくならんかったw
UNetのinput(+mid)ブロックをコピーして、元のUnetのスキップコネクション部分につなげたものです。UNetの記事にめっちゃ適当に説明が書いてあります。
この記事では最近新たに増えたバリエーションの違いについて説明していきます。バリエーションが増えた理由はSDXLの存在です。ControlNetの大きさは元のUNetの大きさに依存するため、同じ設計だとSDXLではとても大きなもの(float32で5GB)とかになってあほらしいから、何とか軽量化しようよというところで3つの手法がでてきました。
Control-lora
stabilityAIが直々に作ったモデルです。ControlNetの学習差分に対して特異値分解を行うことによって、ファイルサイズを削減しているようです。公式お墨付きでComfyUIにもすでに実装されているので、大本命ですがLoRAを使う分計算時間が増えるので、正直微妙じゃね・・・?
Transformerの省略
diffusersによるControlNetのサイズ削減です。Transformer層を省略するだけです。Control-loraより表現力は落ちると思いますが、ファイルサイズだけでなく計算時間も大幅削減できるので、こっちの方が好きです。
学習してみた感じかなりいい感じですね。ControlNetの出力はup_blockへのスキップコネクションに入力されるので、UNet側のdown_blockやmid_blockの逆伝搬が必要ないです。このことは論文にも書いてありましたが、その時は結局ControlNet側の逆伝搬が必要なのだから同じじゃんと思いましたけど、この手法だとControlNetは小さいので学習はかなり早いです。
diffusers的にはこの論文を参考にしているそうです。あんまり関係ない気がしますけど。
ControlNet-LLLite

Kohyaさんによる軽量版ControlNet・・・というかこれはもはやControlNetではないんですが、機能が同じなので分かりやすくそう呼んでいるのだと思います。手法は簡単に言っちゃうとSelf Attentionのq,k,vとCross Attentionのqの前に、いい感じのネットワークを挿入して画像情報を入力します。めちゃくちゃファイルサイズが小さいうえに、UNetに小さなモジュールを追加しているだけなので、生成時間もほとんど増えないです。Kohyaさん本人もおっしゃっていますが、下にあるT2i-Adapterの方が近いです。ただしこちらの方がノイズ除去ループごとに制御が変わるので賢いんじゃないかな。技術的にはResNetブロック等にも適用できるんですが、しないのはComfyUI的に実装しづらいからだったりする。構造もLoRAよりHyperNetworkに近いような。
実は本当の名前はControlNet-Loliです。
T2i-Adapter
T2i-Adapterは画像を入力して4つの出力を返すネットワークになります。そしてUNet内の4つの部分にそれぞれ足します。SDv1は3つのdownsample直前のCross Attention層出力+mid_block直前の出力に足されます。SDXLの場合は最初のdownsample直後の出力、640, 1280チャンネルの最後のCross Attention層の出力、mid_block直後の出力の4つになります。SDXLは最大解像度でもdownsampleを一回通した部分になるので、それでは精度が下がっちゃうのではと思うのですが(しかもおそらくdiffusersの実装で楽するためにそうしてる)。
シンプルな構造で、画像を入れるネットワークがノイズ除去ループから完全に独立しているため、T2i-Adapter自体は1回分の計算で済みます。その分ControlNetより弱いらしくあんまり使ってる人いないですね。私は使ったことないのでよくわかりません。
GLIGEN
めちゃ詳しい記事があるのでそっちに任せます。Self AttentionとCross Attentionの間に新しいAttentionを追加する方法です。バウンディングボックスを用いた配置コントロールなどControlNetでやっていない(やろうとしたらできそうだけど)ことをしていたりと面白そうですが、あんまり流行っていませんね。
HyperDreambooth
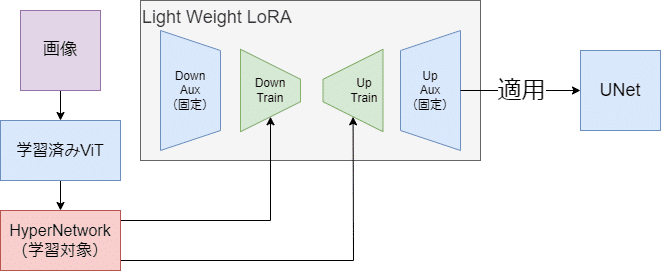
LyCORISで実装されている手法です。この手法は今まで説明してきた手法のように画像情報を直接UNetに入力するのではなく、画像1枚からLoRAを作り、そのLoRAを適用するという構成になっています。正直Dreamboothはあんまり関係ないです。HyperLoRAという方が正しい気がしますね。できたLoRAを初期値としてLoRAの学習することで、通常より早く学習できるという応用があるところがポイントです。