Pytorchの最新機能を使ってFLUX.1でRegional Promptをする

PytorchのないとりぃではFlex Attentionとかいうのが導入されています。今回はそれを使ってFLUX.1のRegional Promptをします。といっても前回同様マスクを使うだけなので、別にいままでのバージョンでもできることなんですが。
SD3との違い
SD3と似たような実装ですが、FLUX.1ではDouble TransformerとSingle Transformerの二種類があります。to_q等を画像、テキストで異なるモジュールに分けるか、同じモジュールにするかの違いっぽいので、あまり関係ないです。またSD3では画像、テキストの順にベクトルを並べていましたが、FLUXは逆になっています。位置が違うだけで考え方は一緒です。
Flex Attention
マスクを使う場合は、Attentionのインデックスから計算に利用するかどうかを判定する論理式を返す関数をつくり、block_maskとかいうのをつくってflex_attention関数に渡します。中のわけわからん論理式は次に説明します。
from torch.nn.attention.flex_attention import flex_attention, create_block_mask
def mask_mod(b, h, q_idx, kv_idx):
return ((q_idx >= 256) & (kv_idx >= 256)) | ~(((q_idx < 128) | ((q_idx >= 256) & ((q_idx // 32) % 2 == 0))) ^ ((kv_idx < 128) | ((kv_idx >= 256) & ((kv_idx // 32) % 2 == 0))))
block_mask = create_block_mask(mask_mod, B=None, H=None, Q_LEN=4096 + 256, KV_LEN=4096 + 256)
# attn_processor内で...
hidden_states = flex_attention(query, key, value, block_mask=block_mask)あとのうんぬんは前回と同じような感じです。
論理式
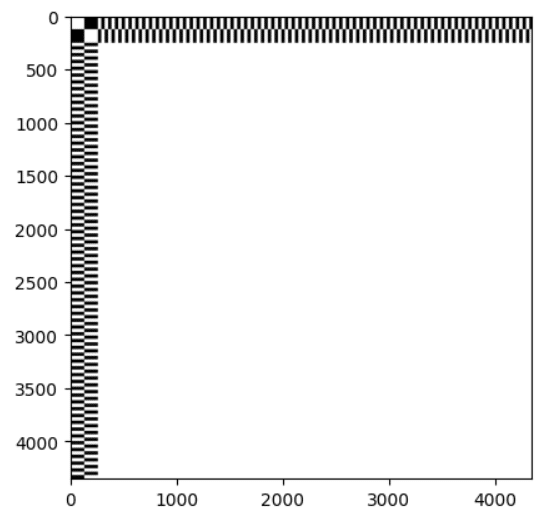
まずq>=256かつk>=256は画像同士の関係性を計算する場所なので、マスクしません。
ほかの場所は、左右を分割しなければいけません。
左側プロンプトの判定式はq<128になります。
また画像の左側の判定式はq>=256かつ(q//32)%2==0になります。左32ピクセル、右32ピクセル、1個下にいってまた左32ピクセル、右32ピクセル…という風に繰り返されるため、32で割って2で割った余りを見ています。
q, k両方左もしくはq, k両方右の部分のみ計算するので、
NOT (IS_LEFT(q) XOR IS_LEFT(k))が計算するか判定する式になります。
これをコードにしたのが
((q_idx >= 256) & (kv_idx >= 256)) | ~(((q_idx < 128) | ((q_idx >= 256) & ((q_idx // 32) % 2 == 0))) ^ ((kv_idx < 128) | ((kv_idx >= 256) & ((kv_idx // 32) % 2 == 0))))になります。もっと単純にできるかもしれませんが、よくわかりません。そもそもこの説明も何言ってるか分かりませんね。
結果

右:2girl are walking side by side on park, yuri, white hair, blue eyes, white school uniform, red bow, blue sailor collar, blue skirt, black thighhigh
前回と同じようなプロンプトでやってみました。ふつーにできてそうですね。ただしscaled_dot_product_attentionを使う場合に比べて計算時間が3倍くらいになっていますTqT。Pytorchのサイトには早くなるって書いてあるんですけお。コードが悪いのか、マスクが複雑すぎるのか、スパース性がないからとか?わかりません。
コード詳細
import torch
import torch.nn.functional as F
from torch.nn.attention.flex_attention import flex_attention, create_block_mask
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
def apply_rope(xq, xk, freqs_cis):
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
def mask_mod(b, h, q_idx, kv_idx):
return ((q_idx >= 256) & (kv_idx >= 256)) | ~(((q_idx < 128) | ((q_idx >= 256) & ((q_idx // 32) % 2 == 0))) ^ ((kv_idx < 128) | ((kv_idx >= 256) & ((kv_idx // 32) % 2 == 0))))
block_mask = create_block_mask(mask_mod, B=None, H=None, Q_LEN=4096 + 256, KV_LEN=4096 + 256)
class AttnCoupleProcessor:
"""Attention processor used typically in processing the SD3-like self-attention projections."""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError("FluxAttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
def __call__(
self,
attn,
hidden_states: torch.FloatTensor,
encoder_hidden_states: torch.FloatTensor = None,
attention_mask = None,
image_rotary_emb = None,
) -> torch.FloatTensor:
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
context_input_ndim = encoder_hidden_states.ndim
if context_input_ndim == 4:
batch_size, channel, height, width = encoder_hidden_states.shape
encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size = encoder_hidden_states.shape[0]
# `sample` projections.
query = attn.to_q(hidden_states)
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
if attn.norm_q is not None:
query = attn.norm_q(query)
if attn.norm_k is not None:
key = attn.norm_k(key)
# `context` projections.
encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
if attn.norm_added_q is not None:
encoder_hidden_states_query_proj = attn.norm_added_q(encoder_hidden_states_query_proj)
if attn.norm_added_k is not None:
encoder_hidden_states_key_proj = attn.norm_added_k(encoder_hidden_states_key_proj)
# attention
query = torch.cat([encoder_hidden_states_query_proj, query], dim=2)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=2)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=2)
if image_rotary_emb is not None:
# YiYi to-do: update uising apply_rotary_emb
# from ..embeddings import apply_rotary_emb
# query = apply_rotary_emb(query, image_rotary_emb)
# key = apply_rotary_emb(key, image_rotary_emb)
query, key = apply_rope(query, key, image_rotary_emb)
hidden_states = flex_attention(query, key, value, block_mask=block_mask)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
encoder_hidden_states, hidden_states = (
hidden_states[:, : encoder_hidden_states.shape[1]],
hidden_states[:, encoder_hidden_states.shape[1] :],
)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if context_input_ndim == 4:
encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
return hidden_states, encoder_hidden_states
class AttnCoupleProcessorSingle:
r"""
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
"""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
def __call__(
self,
attn,
hidden_states: torch.Tensor,
encoder_hidden_states = None,
attention_mask = None,
image_rotary_emb = None,
) -> torch.Tensor:
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, _, _ = hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
if attn.norm_q is not None:
query = attn.norm_q(query)
if attn.norm_k is not None:
key = attn.norm_k(key)
# Apply RoPE if needed
if image_rotary_emb is not None:
# YiYi to-do: update uising apply_rotary_emb
# from ..embeddings import apply_rotary_emb
# query = apply_rotary_emb(query, image_rotary_emb)
# key = apply_rotary_emb(key, image_rotary_emb)
query, key = apply_rope(query, key, image_rotary_emb)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = flex_attention(query, key, value, block_mask=block_mask)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
return hidden_states
for i, block in enumerate(pipe.transformer.transformer_blocks):
block.attn.processor = AttnCoupleProcessor()
for i, block in enumerate(pipe.transformer.single_transformer_blocks):
block.attn.processor = AttnCoupleProcessorSingle()
left = "2girl are walking side by side on park, yuri, black hair, red eyes, maid, maid apron, maid headdress, white thighhigh"
right = "2girl are walking side by side on park, yuri, white hair, blue eyes, white school uniform, red bow, blue sailor collar, blue skirt, black thighhigh"
left_emb = pipe.encode_prompt(left,left, max_sequence_length=128)
right_emb = pipe.encode_prompt(right,right, max_sequence_length=128)
prompt_embeds = torch.cat([left_emb[0], right_emb[0]], axis=1)
pooled_prompt_embeds = (left_emb[1] + right_emb[1]) / 2
generator = torch.Generator()
generator.manual_seed(4545)
image = pipe(
num_inference_steps=30,
guidance_scale=3.5,
prompt_embeds = prompt_embeds,
pooled_prompt_embeds = pooled_prompt_embeds,
generator = generator
).images[0]