
DeepEvalとLangfuseをつかってみた

数多くのLLMが公開されていますが、それらのLLMをカスタマイズして高い品質で提供するためにはLLMが生成したテキストが人が期待した結果かどうかを評価する必要があります。
クローズドなLLMならば場合によってはほとんど評価せずに機能を提供することも可能かもしれません。
しかし、ローカルLLMのようなモデルだと評価を行い期待した結果が生成が行われることを保証した上で機能を提供することが必要になるでしょう。
そこで、Langfuseのようなツールによって実行ログを収集して、DeepEval をLangfuseに統合してLLMの評価を行う方法を簡単に確認してみます。
Langfuseの起動
WSL2でローカルホストに簡単にLangfuseをホストすることができます。今回はDockerComposeを使ってLangfuseを起動してみます。
git clone https://github.com/langfuse/langfuse.git
cd langfuse
docker compose up -dほぼ公式サイトのコマンドそのままですね。
これによって、http://localhost:3000でLangfuseがホストされました。
また、Windows側からはhttp://localhost:3000/auth/sign-inをブラウザで開くことができます。SignUpしてログインします。
その後、下記キャプチャーのように組織とプロジェクトを作成します。ここではnoteという組織の配下にdeepevalというプロジェクトを作成しました。

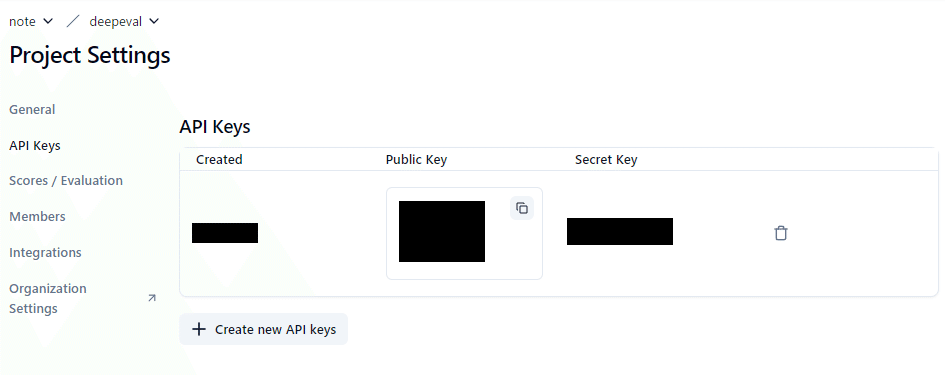
さらに、Langfuseのプロジェクトにアクセスするためのキーを発行します。
SecretKeyとPublicKeyを使うので下記の画面からコピペできるようにしておきましょう。
Ollamaの準備
ローカルLLMの評価を行いたいので、OllamaでLLMを使う準備をしておきます。日本語のLLMを使うので、今回は以下のモデルを使ってみます。
ollama run dsasai/llama3-elyza-jp-8b:latest評価実行用のコード
DeepEval とLangfuseを統合して、ローカルLLMの評価用コードを書いていきます。
準備
使用するライブラリをインポートして、ここまでに起動したLangfuseとOllamaのURLを記載しています。ここでは、評価用のライブラリDeepEval もインポートしています。
from ollama import Client
from deepeval.test_case import LLMTestCase
from deepeval.metrics import BaseMetric
from deepeval.models.base_model import DeepEvalBaseLLM
from langfuse.decorators import langfuse_context, observe
langfuse_url = 'http://xx.xx.xx.xx:3000'
ollama_url = 'http://yy.yy.yy.yy:11434/'
model_id = 'dsasai/llama3-elyza-jp-8b:latest'
langfuse_context.configure(
secret_key="sk-lf-xxxxxxxx",
public_key="pk-lf-xxxxxxxx",
host=langfuse_url
)
client = Client(host=ollama_url)テキスト生成関数と評価用モデルクラスの作成
テキスト生成関数をシステムプロンプトと合わせて定義します。この関数の入出力をLangfuseで記録したいので、observeデコレーターを付与します。
また、DeepEval でローカルLLMを評価用モデルとして使用するためのクラスを定義しています。
system = '''
あなたは数値に厳密で優秀な日本人のアシスタントです。
特に指示が無い場合は、常に日本語で回答してください。
'''
@observe(as_type="generation")
def generate(prompt, model_id=model_id, mode=None, system=system):
response = client.generate(model=model_id, prompt=prompt, format=mode, system=system)
return response['response']
class OllamaModel(DeepEvalBaseLLM):
def __init__(self, model):
self.model = model
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
return generate(prompt, model_id=self.model)
async def a_generate(self, prompt: str) -> str:
res = await generate(prompt, model_id=self.model)
return res.content
def get_model_name(self):
return "Custom Ollama Model"
eval_model = OllamaModel(model_id)ここで注意としては「評価用モデル」と「テキスト生成モデル」の2種類のLLMの役割があること。上記コードでは、「評価用モデル」を定義しています。
「テキスト生成モデル」は通常、RAGのロジックのようなカスタマイズ処理を含むことが想定されますが、今回は簡単のためにカスタマイズ処理なしとします。
カスタム評価プロンプト
DeepEval の評価は英語を標準として評価用のプロンプトが書かれています。評価用モデルが日本語チューニングされたモデルなので、評価用のプロンプトも日本語で書くことにします。
scoring_template = '''
AIによって生成されたテキストが期待するテキストと同じ意味の場合には1、異なる場合には0を返却してください。
ただし、回答は以下のJSON形式で回答してください。
{{"score": "0 or 1"}}
### AIによって生成されたテキスト
{output}
### 期待するテキスト
{expected}
### 回答
'''
reason_template = '''
AIによって生成されたテキストが期待するテキストと意味が異なると判断された理由を考えてください。
ただし、回答は以下のJSON形式で回答してください。
{{"reason": "関連がないと判断された理由"}}
### AIによって生成されたテキスト
{output}
### 期待するテキスト
{expected}
### 回答
'''
def generate_score(test_case, count=5):
prompt = scoring_template.format(
output=test_case.actual_output,
expected=test_case.expected_output,
)
scores = []
for _ in range(count):
scores.append(generate(prompt))
return scores
def generate_reason(test_case):
prompt = reason_template.format(
output=test_case.actual_output,
expected=test_case.expected_output,
)
reason = generate(prompt)
return reason
async def a_generate_score(test_case, count=5):
return generate_score(test_case, count=count)
async def a_generate_reason(test_case):
return generate_reason(test_case)カスタムメトリック
先の評価用プロンプトを使った評価はカスタムメトリックとしてクラス化して使用する。DeepEval のBaseMetricのインターフェースに合うようにCustomMetricクラスを実装する。
import json
class CustomMetric(BaseMetric):
def __init__(self, threshold: float=0.5):
self.threshold = threshold
def measure(self, test_case: LLMTestCase) -> float:
try:
count, score = 5, 0
res = generate_score(test_case, count=count)
for r in res:
r = json.loads(r)
score += int(r['score'])
self.score = score / count
if self.score < self.threshold:
res = generate_reason(test_case)
res = json.loads(res)
self.reason = res['reason']
self.success = self.score >= self.threshold
return self.score
except Exception as e:
self.error = str(e)
raise
async def a_measure(self, test_case: LLMTestCase) -> float:
try:
count, score = 5, 0
res = a_generate_score(test_case, count=count)
for r in res:
r = json.loads(r)
score += int(r['score'])
self.score = score / count
if self.score < self.threshold:
res = await a_generate_reason(test_case)
res = json.loads(res)
self.reason = int(res['score'])
self.success = self.score >= self.threshold
return self.score
except Exception as e:
self.error = str(e)
raise
def is_successful(self) -> bool:
if self.error is not None:
self.success = False
else:
return self.success
@property
def __name__(self):
return "My Custom Metric"評価用データ
評価用のデータは以下1パターンのみを今回は使用する。
data = [{
'input': 'バレーボールのネットの規格について教えて',
'expected': '''
家庭バレーボールの競技規則ではネットについて、以下のように記載されています。
- 規格は、幅1メートル、網目10㎝四角で両サイドラインの外側25cm以上張れる長さのもの。
- 高さは、2m20cmで主催者の決定によりネットの高さは適宜変更できる。
''',
}]評価の実行
評価処理を実装したevaluate関数には、Langfuseのobserveデコレーターを付与する。これによりevaluate関数の呼び出しはLangfuseに記録されることになります。
def test_correctness(input, response, expected):
test_case = LLMTestCase(
input=input,
actual_output=response,
expected_output=expected
)
correctness_metric = CustomMetric()
correctness_metric.measure(test_case)
print(f'Score: {correctness_metric.score}')
print(f'Reason: {correctness_metric.reason}')
return correctness_metric.score, correctness_metric.reason
@observe()
def evaluate(dataset):
for d in dataset:
p, e = d['input'], d['expected']
r = generate(p)
score, reason = test_correctness(p, r, e)
langfuse_context.score_current_observation(
name="correctness",
value=score,
comment=reason,
)
evaluate(data)evalute関数の実行結果は以下。
Score: 0.0
Reason: AIによって生成されたテキストが国際バレーボール連盟(FIVB)の規格を基にした内容であるのに対し、期待するテキストが家庭バレーボールの競技規則で記載されている内容が異なるため。「テキスト生成モデル」が生成したテキストが、期待するテキスト(expected)と同じ意味かどうかを判定するような評価を行いました。
その結果のスコアは0.0で、意味が異なるという判定で理由も出力されました。
Langfuseでの確認
では、Langfuseで評価の実行ログがどのように見えるかを確認してみます。
Trace
Trace画面にはevaluateが記録されています。UserやSessionは設定していないので空になっていますが、実行のタイムスタンプや実行時間は記録されています。

Traceの詳細
Traceの詳細画面でevaluteを開くと、入力されたデータと出力が確認できます。ここでは出力をNoneにしているので、nullとなっています。
画面の右側には、evaluateの処理の中で呼び出されたgenerateが記録されています。各呼び出しの実行時間が記録されており、どの関数呼び出しに時間がかかったかを確認することができます。

Traceの詳細:Scores
Traceの詳細画面画面でScoresタブを開くと実行されたDeepEval のメトリックが記載されています。メトリックの名前は算出されたスコアを確認することができます。
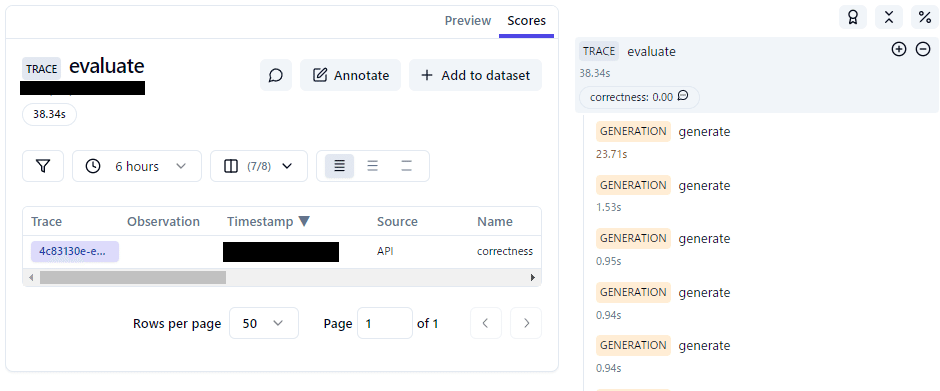
Observationは空になっているので、ここにもデータが入るようにカスタムメトリッククラスの実装を再調査する必要がありそうです。
Generateのログ
Generateのログは3種類あります。
「テキスト生成モデル」の生成ログ
「評価用モデル」のスコア算出ログ
「評価用モデル」のスコア理由付けログ
まず、「テキスト生成モデル」の生成ログです。
LLMが生成したテキストがoutputで確認できます。

次に、「評価用モデル」のスコア算出ログです。
スコア算出はJSON形式で出力されており、使用されたプロンプトも確認することができます。

そして「評価用モデル」のスコア理由付けログです。
期待するテキストとは異なるテキストが生成された理由が出力されています。

まとめ
DeepEvalとLangfuseを統合したLLMの評価を試してみました。LLMの評価を行い、プロダクトとしてリリースした後もLangfuseでログ監視を行うという運用ができそうな機能が確認できました。
他にもLLMの評価を行う方法として、他にもpromptfooというツールが存在しているようです。LLMのカスタマイズを実験して改善するサイクルを回すのにはpromptfooの方が向いていそうなので、これも試してみたい。。。