
[論文紹介コード付] 時系列Transformerを自然言語処理のお作法で鍛えたらゼロショットで未来の系列を予測することができました

タイトル:Chronos: Learning the Language of Time Series
著者:Abdul Fatir Ansari1∗ , Lorenzo Stella1∗ , Caner Turkmen1 , Xiyuan Zhang2† , Pedro Mercado1 , Huibin Shen1 , Oleksandr Shchur1 , Syama Sundar Rangapuram1 , Sebastian Pineda Arango3‡ , Shubham Kapoor1 , Jasper Zschiegner, Danielle C. Maddix1 , Michael W. Mahoney4 , Kari Torkkola4 , Andrew Gordon Wilson1 , Michael Bohlke-Schneider1 , Yuyang Wang1
機関:1Amazon Web Services, 2UC San Diego, 3University of Freiburg, 4Amazon Supply Chain Optimization Technologies
投稿日時:12 Mar 2024
リンク:https://arxiv.org/pdf/2403.07815.pdf
一言でまとめると:時系列Transformerを自然言語処理のお作法で鍛えたら,ゼロショットで未来の系列を予測することができました

アブストラクト
まずは翻訳にかけて,ポイントとなりそうなところを太字にします.
本論文では、事前学習された確率的時系列モデルのための、シンプルかつ効果的なフレームワークであるChronosを紹介する。Chronosは、スケーリングと量子化を用いて時系列値を固定語彙にトークン化し、これらのトークン化された時系列に対して、既存のtransformerベースの言語モデルアーキテクチャをクロスエントロピー損失によって学習する。我々は、T5ファミリーに基づくChronosモデル(20Mから710Mのパラメータ)を、一般に利用可能な大規模なデータセットで事前訓練し、汎化性を向上させるためにガウス過程を用いて生成した合成データセットで補完した。42のデータセットから構成され、古典的なローカルモデルとディープラーニング手法の両方からなる包括的なベンチマークにおいて、我々は、Chronosモデルが、(a)トレーニングコーパスの一部であったデータセットにおいて、他の手法を有意に上回ること、(b)新しいデータセットにおいて、そのデータセットに特化してトレーニングされた手法と比較して、同等の、時には優れたゼロショット性能を有することを示す。我々の結果は、Chronosモデルが多様なドメインの時系列データを活用して、未知の予測タスクのゼロショット精度を向上させることができることを示しており、事前学習済みモデルを予測パイプラインを大幅に簡素化する実行可能なツールとして位置付けている。
最も重要な点としては,自然言語処理の分野で提案された,既存のtransformerベースのモデルを時系列予測に用いている点です.一般的な利用可能な大規模なデータセットで学習されている点は普通ですが,その後に続く,「ガウス過程を用いて生成した合成データセットで補完」というところは本手法特有の工夫になりそうです.さらに結果を見ると,データセット特化型のモデルと同等あるいは優れたゼロショット性能を持つとのことなので,これは大量かつ多種多様なデータを与えれば未知の予測タスクが行える,言い換えると一つの大きなモデルを学習すれば他は何もする必要がない(推論するだけなのだから)と言っています.
イントロダクション
後半部分が参考になりそうなので抜き出して翻訳します.
次のトークンを予測する言語モデルと、次の値を予測する時系列予測モデルの根本的な違いは何か?有限な辞書からのトークンか、束縛のない、通常は連続的な領域からの値か、という見かけ上の違いはあるものの、どちらの試みも基本的には、将来のパターンを予測するために、データのシーケンシャルな構造をモデル化することを目的としている。優れた言語モデルは、時系列に対して「単に機能」すべきではないのだろうか?この素朴な疑問が、時系列に特化した修正の必要性に挑戦することを促し、それに答えることが、時系列予測に最小限の適応をした言語モデリングフレームワークであるChronosを開発することにつながった。Chronosは、実数値の単純なスケーリングと量子化によって、時系列を離散的なビンにトークン化する。このようにして、モデル・アーキテクチャに変更を加えることなく、既製の言語モデルをこの「時系列の言語」に対して学習させることができる(Chronosのハイレベルな描写は図1を参照)。驚くべきことに、この単純なアプローチが効果的かつ効率的であることが証明され、言語モデル・アーキテクチャが最小限の変更で幅広い時系列問題に対応できる可能性が強調された。
この箇所より,彼らの疑問は「次のトークンを予測する言語モデルと,次の値を予測する時系列予測モデルの根本的な違いは何か?」であることが分かります.そして,言語処理向けに提案されたモデルをほとんど変更することなく,最小限の変更で時系列タスクに適用できる可能性がある,つまりstraightforwardなやり方だと書いてあります.
提案モデルの名前はChronosで,概要図がFigure 1にあるので見ていきます.
左の図はスケールかつ量子化(Quantization)された入力時系列データを示していて,中央がencoder-decoderかdecoder onlyの言語モデルに入力されるトークンを表しています.さらに右の図は推論時の動作を示しており,モデルからのトークンを数値(時系列)データに戻す手順が示されています.さらに最後の文には「予測分布を得るために,複数の軌道がサンプリングされる」と書いてあります.おそらく,右下の赤で示される時系列データの周りの薄くピンクがかったエリアのことを指しているのではないかと思います.複数の軌道を予測することにより,予測の幅(上界や下界)を可視化しています.
Figure 1を見ると,Chronosは,GPTなどで行われている次に現れる単語の予測タスクをほぼそのままの形で時系列データに適用していることが分かります.
Chronos: A Language Modeling Framework for Time Series
3章にChronosのフレームワークの説明が書いてあります.3.1のScalingというパラグラフを見ると,一般的な機械学習のように説明変数を正規化していることがわかります.Quantizationのパラグラフを見ると,量子化のやり方が記載されています.正規化された時系列データは,まだリアルな値(連続値)であるため,直接言語モデルに与えることができません.そこで,連続値の時系列データを離散化して言語モデルで扱えるようにする量子化の方法を説明しています.
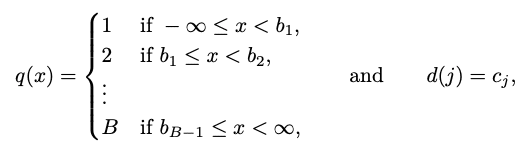
ここで説明されている量子化は,以下のステップで処理が行われています.
実数線上にB個のビン中心c1 < … < c_Bを選び,B-1個のビン端b1 < … < b_B-1を決める.ただしc_i < b_i < c_i+1となるようにする.
量子化関数 q:R→{1, 2, …, B}と,復元関数 d: {1, 2, …, B}→Rを定義する(変換された値を元に戻して使えるようにするために)
上記式でq(x)を定義し,実数xをビン番号を割り当てます.具体的には,x < b_1なら1,b_1 < x < b_2なら2,b_B-1 < xならBを割り当てます.そして右に書いてあるd(j)はビン番号jを実数値に戻すための関数になります.
さらに本研究では時系列トークン{1, 2, . . B}とは別に,言語モデルでよく使われる2つの特別なトークンPADとEOSを時系列語彙(vocabulary)に含めています.
PADトークン:バッチ処理のために異なる長さの時系列を一定の長さにパディングし,欠損値を置換するために使用されます
EOSトークン:自然言語処理では,文の終わりを示す役割(EOS = End Of Sequence).文の始まりを示すBOS = Beginning Of Sequenceもある.これらの使用は必須ではないが,一般的な言語モデルライブラリに合わせるために使用しています
また,一般的に時系列モデリングでは,曜日や週などの特徴を通して,時間や頻度の情報を組み込みますが,Chronosでは (直感に反するかもしれないが)時間や周波数の情報は無視し,「時系列」を単にシーケンスとして扱っています(論文ではこのことをlanguage of time seriesと言っています).
ちなみにオリジナルのT5のトークン数32,128に対し,Chronos-T5のトークン数は4,096です.かなりvocabraryのサイズが抑えられています.
3.2章では,ロス関数について書いてあります.著者らはカテゴリカル分布をボキャブラリVtsにわたって使っており,この分布はp(zC+h+1|z1:C+h)として示され,z1:C+hはトークナイズされた時系列データを示しています.Chronosは量子化された真の系列(正解データ)の分布と推定された分布の間のクロスエントロピーロスを最小化する学習を行なっています.ロス関数は次のように表されます.
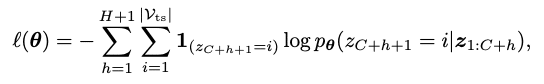
pθ(zC+h+1 = i|z1:C+h)は,θによってパラメタライズされるモデルのカテゴリカルな分布を予測することを示しています.
ここで,カテゴリカルクロスエントロピーロスは,距離を考慮した目的関数ではないことに注意してください.言い換えると,これはビンiがビンi+1と近く,ビンi+2と遠いことは認識できないモデルであると言えます.その代わり,モデルは訓練データセットの中のビン・インデックスの分布に基づいて,近くのビンを一緒に関連付けることが期待されます(つまり,データから勝手に距離を学んでくれるだろうという期待のことです).
Data Augmentation
この論文で図を2つも割いて説明されているのがデータ増強の章です.
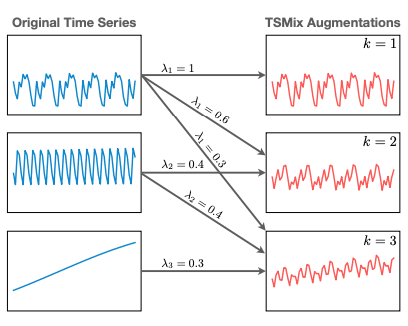
4.1では,Time Series Mixupに関する説明があります,mixupはデータ増強のスキームで画像分類で提案された手法です.これは,ランダムな画像ペアの合体を生成する手法であり,そのラベルは訓練データから来ています.
やっていることは単純で,オリジナルの時系列データをさまざまな割合で混ぜて合成データを作っています.下記の図のようなイメージです.このように画像のmixupを時系列データ向けに応用している先行研究は2つあり,著者らもこれに倣っています.
4.2で紹介されているのが,KernelSynthという手法で,これはガウス過程(GP)を用いて合成時系列を生成する手法です.おそらくこの論文オリジナルの手法です.
具体的には、以下のようなプロセスを経て合成データを生成します:
基本的な時系列パターン(トレンド,局所的な変動,季節性など)を表現するベースカーネルの集合Kを用意する
複数のベースカーネルをランダムに選び,加算または乗算で組み合わせて最終的なGPカーネルκ̃を作成する
平均関数m(t)=0,カーネルκ̃を持つガウス過程GP(m(t)=0, κ̃(t,t')) から所望の長さの時系列サンプルを生成する
このようにして作られる合成データは,単純なベースカーネルの組み合わせによって複雑なパターンを持つ時系列になります

詳細なアルゴリズムは付録についてます.

実験とその結果
5章以降の内容をかいつまんでまとめていきます.
Benchmark I (訓練データを含むデータセット)において,Chronosモデルは従来の統計的手法や他の深層学習モデルを大きく上回る性能を示しました

Benchmark II(訓練データに含まれないデータセット=ゼロショット)においても,Chronosは統計的手法を大きく上回り,他の深層学習モデルとほぼ同等の性能を示しました

データセット統計とベースラインモデルは以下です.Benchmark Ⅱの方が多く,ゼロショット評価の方を重視する傾向があります.

ハイパーパラメータ調整を行うと,Chronos-T5 (Small)がBenchmark IIで最高性能となり,全ベースラインを大きく上回りました
Chronosは様々なパターン(トレンド,季節性,自己回帰など)を適切に捉えられることが確認されました

Chronosの予測分布は柔軟で,単峰性や多峰性の分布を出力できます

一方で,トークン化の方法に起因する値の範囲制限や精度低下の問題が挙げられています

まとめ
この研究では,時系列予測のための汎用的な事前学習モデルの開発を,ミニマリストの観点から考えています.既存の言語モデルのアーキテクチャと学習手順を時系列予測に適用し,時系列固有の機能やアーキテクチャが予測には必要ないと主張しています.そして,時間に無関係な言語モデルフレームワークである「Chronos」を提案しました.Chronosの特徴は,スケーリングと量子化によるトークン化以外は,どの言語モデルアーキテクチャでも適用可能な点にあります.
事前学習済みのChronosモデルは,従来のローカルモデルやタスク特化型の深層学習ベースラインよりも,学習データに対する性能が大幅に優れています.さらに注目すべきは,Chronosモデルが未知のデータセット(ゼロショット)に対しても優れた結果を示し,そのデータセットで学習された最良の深層学習ベースラインと同等の性能を発揮したことです.さらに微調整によってさらなる性能向上が期待できます.
この研究の2つの主な貢献は以下の通りです.
時系列固有の調整をせずに,既存の言語モデルアーキテクチャでも予測が可能であることを示した.これにより,大規模言語モデルの発展やより良いデータ戦略を活用した急速な進歩が期待できます.
実用的な観点から,Chronosモデルの優れた性能は,予測精度を犠牲にすることなく,大規模な事前学習言語モデルを使うことで予測パイプラインを大幅に簡素化できることを示唆しています.これにより,従来の個別タスクでモデルを訓練・調整する手法に代わる,推論のみのアプローチが可能になります.
コード
Chronosはgithubで学習済のモデルが公開されており,簡単に試すことができます
まずはインストールから.CUDAを使っているので,GPUのマシンが必要です
!pip install git+https://github.com/amazon-science/chronos-forecasting.git次に著者らが示すサンプルを動かします
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from chronos import ChronosPipeline
pipeline = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-small",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
df = pd.read_csv("https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv")
# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
context = torch.tensor(df["#Passengers"])
prediction_length = 12
forecast = pipeline.predict(context, prediction_length) # shape [num_series, num_samples, prediction_length]
# visualize the forecast
forecast_index = range(len(df), len(df) + prediction_length)
low, median, high = np.quantile(forecast[0].numpy(), [0.1, 0.5, 0.9], axis=0)
plt.figure(figsize=(8, 4))
plt.plot(df["#Passengers"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
plt.show()結果は次のとおりです.飛行機の乗客数はきちんと予測できているように見えます

次に,日経平均株価に対する予測性能を確認しましょう.
データをkaggleからダウンロードします
https://www.kaggle.com/datasets/mattiuzc/stock-exchange-data
データを読み込んで,日経平均を示すdf.Index == “N225”のデータのみを抽出しましょう.今回は最新の日付の512点を検証に使います.
df = pd.read_csv("./stock_exchange_data/indexProcessed.csv")
df_n225 = df[df.Index == "N225"]
df_n225 = df_n225.sort_values(by='Date', ascending=False)
df_n225 = df_n225.head(512)
df_n225 = df_n225.reset_index(drop=True)加工後のデータは以下です.512サンプルに削減されてます.
Index Date Open High Low Close Adj Close Volume CloseUSD
0 N225 2021-06-03 28890.39063 29157.16016 28879.15039 29058.10938 29058.10938 0.0 290.581094
1 N225 2021-06-02 28730.81055 29003.55078 28565.83008 28946.14063 28946.14063 71000000.0 289.461406
2 N225 2021-06-01 28998.65039 29075.47070 28611.25000 28814.33984 28814.33984 47400000.0 288.143398
3 N225 2021-05-31 29019.44922 29147.71094 28791.59961 28860.08008 28860.08008 53800000.0 288.600801
4 N225 2021-05-28 28912.53906 29194.10938 28899.66016 29149.41016 29149.41016 80600000.0 291.494102
... ... ... ... ... ... ... ... ... ...
507 N225 2019-04-26 22167.48047 22270.28906 22073.09961 22258.73047 22258.73047 71900000.0 222.587305
508 N225 2019-04-25 22183.32031 22334.68945 22155.23047 22307.58008 22307.58008 63300000.0 223.075801
509 N225 2019-04-24 22356.83008 22362.91992 22125.48047 22200.00000 22200.00000 67900000.0 222.000000
510 N225 2019-04-23 22241.74023 22268.36914 22119.93945 22259.74023 22259.74023 52000000.0 222.597402
511 N225 2019-04-22 22188.61914 22280.18945 22099.38086 22217.90039 22217.90039 42900000.0 222.179004
512 rows × 9 columns予測のコードは以下です.ところでこのデータには株価を示す列が複数あります.今回はHighの株価を使っています.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from chronos import ChronosPipeline
pipeline = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-small", device_map="cuda", torch_dtype=torch.bfloat16,
)
# 予測する点数を指定(推奨は64点以下)
prediction_length = 64
# 入力ののうち,(input-prediction_length)点をモデル入力にする
context = torch.tensor(df_n225["High"].values[:(-1 * prediction_length)])
forecast = pipeline.predict(context, prediction_length)
# 残りの64点は真値と予測を重ねて表示
forecast_index = range(len(context), len(context) + prediction_length)
low, median, high = np.quantile(forecast[0].numpy(), [0.1, 0.5, 0.9], axis=0)
# y軸の範囲を設定
y_min = min(df_n225["High"].min(), low.min()) - 100
y_max = max(df_n225["High"].max(), high.max()) + 100
# x軸の範囲を設定
x_min = df_n225.index.min()
x_max = max(df_n225.index.max(), forecast_index[-1])
plt.figure(figsize=(8, 4))
plt.plot(df_n225["High"], color="royalblue", label="historical data")
plt.plot(df_n225.index[(-1 * prediction_length):], df_n225["High"].values[(-1 * prediction_length):], color="green", label="ground truth") # 真値を緑色で表示
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
# y軸とx軸の範囲を設定
plt.ylim(y_min, y_max)
plt.xlim(x_min, x_max)
plt.show()結果
今回はいくつかの株価を入力し,その先をどのくらい予測できるかを確認します
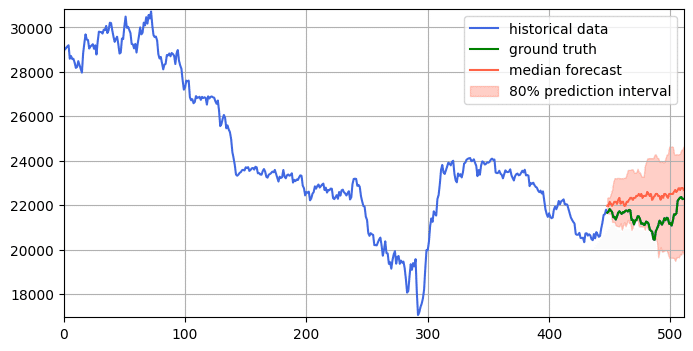
chronos-t5-smallの予測結果は,当たっているとも外れているとも言えない,微妙な結果です

一方,chronos-t5-largeはchronos-t5-smallと比べて大外れです.しかし,smallの時は,直前の値を追従するような無難な予想をしにいっているのに対し,largeでは直前の上昇を織り込んでこれからもっと上がるだろうと強気に予想して外しているように見え,何かの直感を信じ,自分の意見を持って考えてはいるように感じます.


上のchronos-t5-smallと比べて,ground truthに寄ってる感じがします.さらに,prediction intervalもsmallに比べて幅が狭くなっており,なんらかの確信を持って予測していっている様子が見て取れます.



モデルをchronos-t5-largeに変更すると,少し遅れていますが,上昇と下落の傾向は捉えられているように見えます.さらにprediction intervalを観察すると,x=500辺りでピンクの上振れが激しくなっており,急上昇の予兆を捉えられているようにも見えます.

まとめると,本論文は,時系列transformerを自然言語処理のお作法で鍛えるという内容でした.いくつかの株価への適用を行った結果,小さなモデル(chronos-t5-small)より大きなモデル(chronos-t5-large)の方が予測性能が改善されているように見えるため,大量の時系列データでモデルを学習する意味は確かにあるのではないかと思いました.