
Hugging Faceプラットフォームの紹介とアクセストークン活用法

Hugging Faceの概要

今やAI技術が私たちの日常に溶け込み、未来への「夢」が現実の形になりつつありますよね。その中でも「Hugging Face」というプラットフォームは、生成AIや機械学習を手軽に体験できる魅力的な場所として、多くの方が利用しています。Hugging Faceは、まるでAI界の「GitHub」のように、さまざまなAIモデルやデータセットが公開されていて、気軽に参照・共有できる環境を提供しています。
🐱GitHubについて🐱
基本的には無料で利用できるHugging Faceですが、商業利用や追加機能を使いたい場合には有料プランもあります。それでも無料版での機能は十分なので、初心者でも気軽に始められるのが魅力的です。現在、Hugging Faceには100万以上ものAIモデルが公開されていて、AIに興味を持つ方や、実務で活用したい方にとっても心強い存在です。
プラットフォームの主要機能
Hugging Faceには、「モデル」「データセット」「スペース」という三つの主要機能が備わっています。これらを使いこなすことで、初心者の方でも生成AIの世界をスムーズに体験し、自分なりのプロジェクトを進められるように工夫されていますよ。それぞれの機能について少しずつ見ていきましょうね。
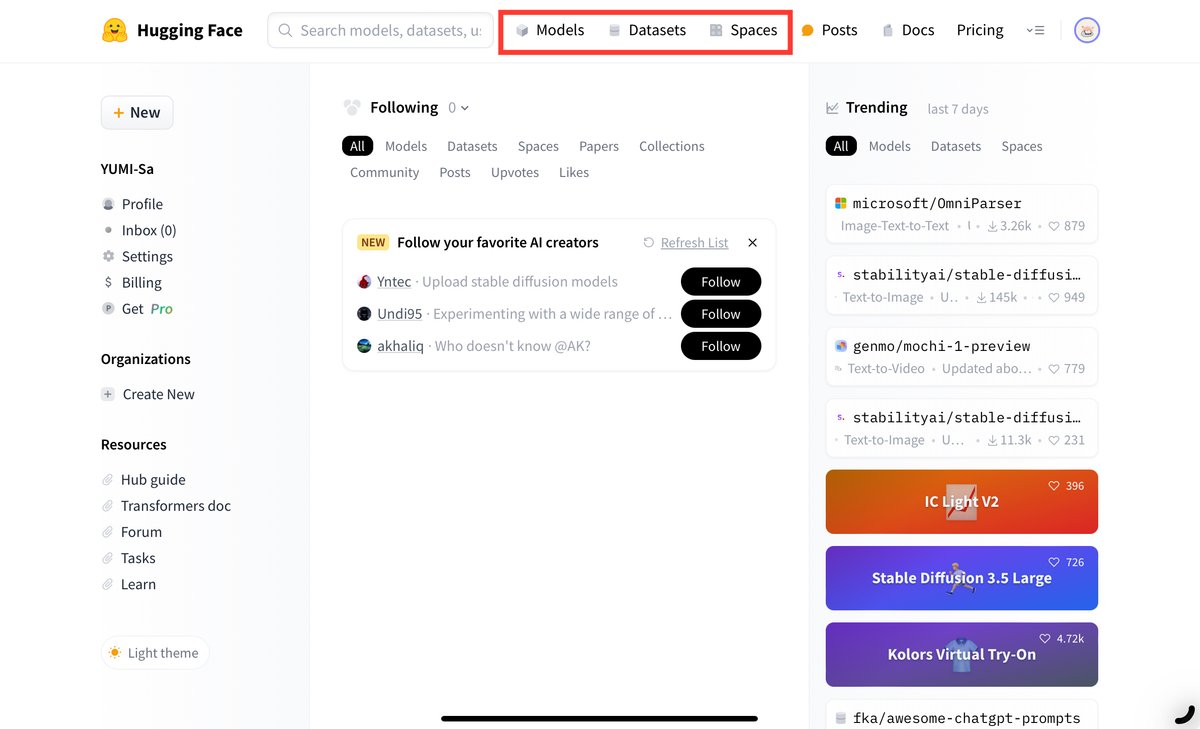
モデル:生成AIモデルの共有と参照
Hugging Faceの「モデル」セクションは、AIモデルが揃った場所で、テキスト生成や画像生成、音声処理など多岐にわたるタスクを支えるモデルが公開されています。各モデルには「モデル名」「バージョン」「パラメーター数」などの情報が記載されているため、自分の目的に合ったものを選びやすいのがうれしいポイントですね。特に、パラメーター数が多いモデルはより高精度な出力が期待できますが、その分処理に時間がかかることもありますので、モデルの選び方も工夫してみるといいかもしれません。
モデル選びも、プロジェクトに合わせて最適なものを探す「楽しみ」がありますよね。例えば、チャットボットのための言語モデルや、画像生成モデルなど、目的に応じたモデルを選んで試してみると、生成AIの力を実感できるはずです。
データセット:学習用データの共有と参照
次に、Hugging Faceの「データセット」セクションでは、学習用データを公開している場所です。AIモデルを育てるには大量のデータが必要ですが、こちらでは他のユーザーが提供するデータセットを利用できるため、データ収集の手間が省け、特に初めての方にとっては心強いですね。また、すでにあるデータを利用すれば、お金や時間をかけずに効率よく始められるのもHugging Faceの魅力の一つです。
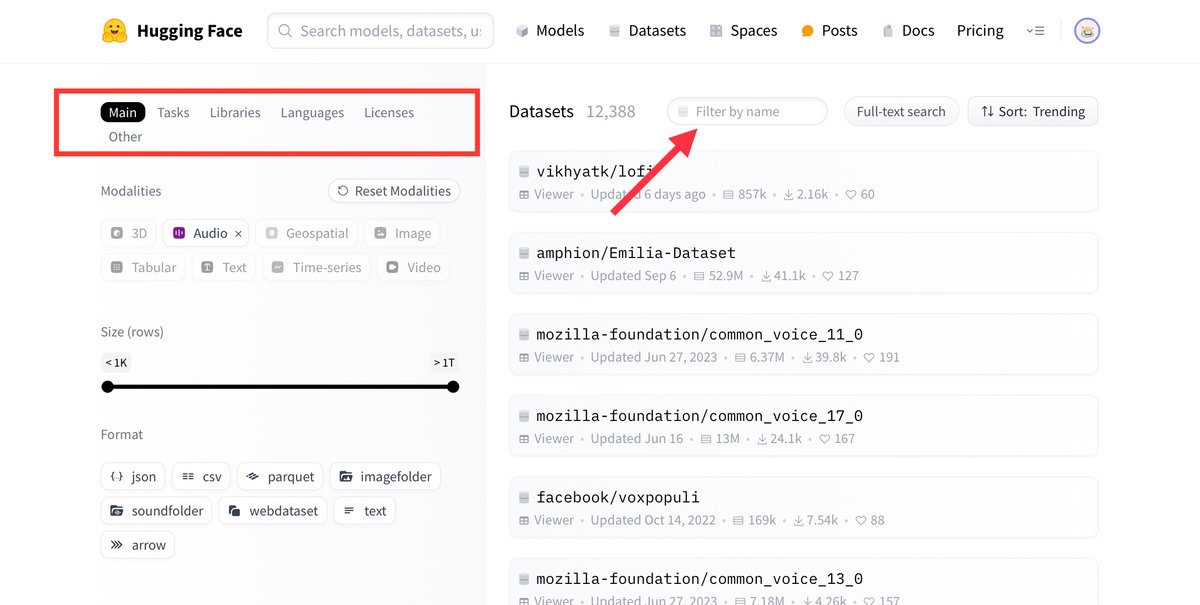
データセットにはさまざまな種類があり、自然言語データ、画像データ、音声データなど、それぞれのニーズに合わせて利用できます。このセクションを上手に活用することで、AI技術を自分の手で育て上げる体験がより身近なものになりますね。
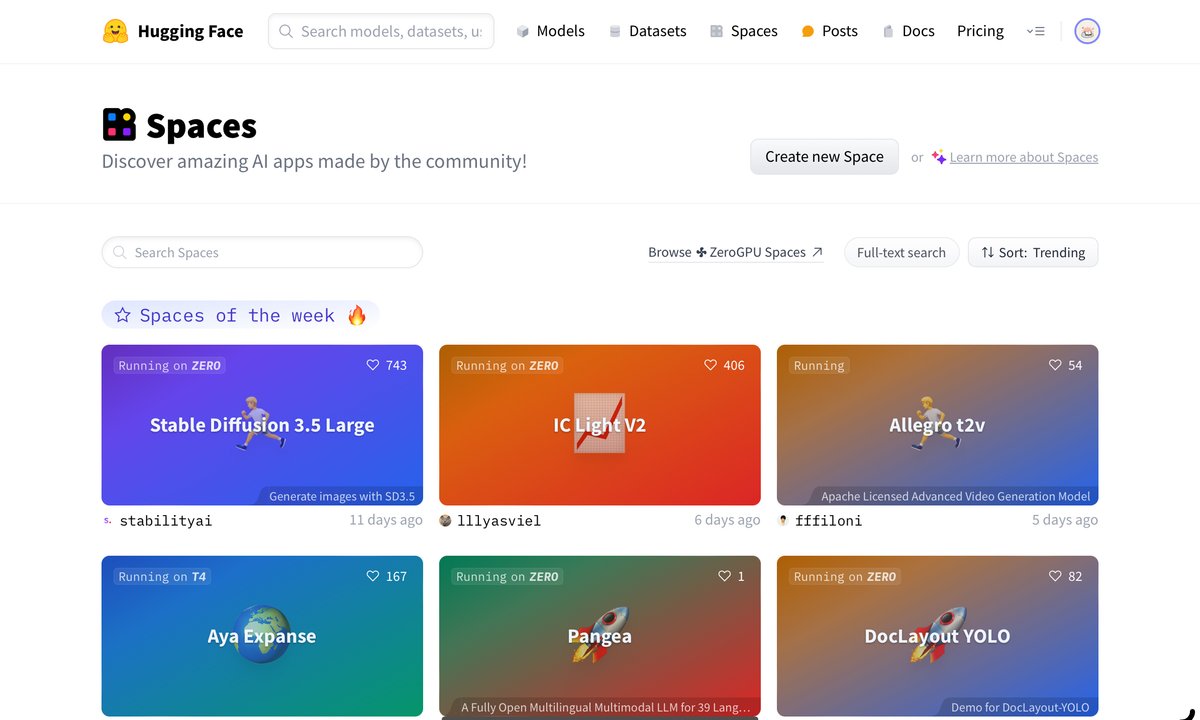
スペース:AIアプリケーションの共有プラットフォーム
「スペース」は、Hugging Faceのユーザーが作成したAIアプリケーションを自由に試すことができる場所です。Hugging Faceのスペースでは、画像生成やテキスト解析、さらには会話型のAIまで、たくさんのアプリケーションが公開されています。ここでは自分で作成したアプリケーションを他のユーザーと共有することもでき、フィードバックを通じて新たなアイデアをもらったり、人とのつながりから学びを深めたりすることもできるのです。こうして他の方々との「人間関係」を築きながら、生成AIの新たな可能性を見つけていくのも楽しみの一つですね。
モデルセクションの詳細
モデルの種類と特徴
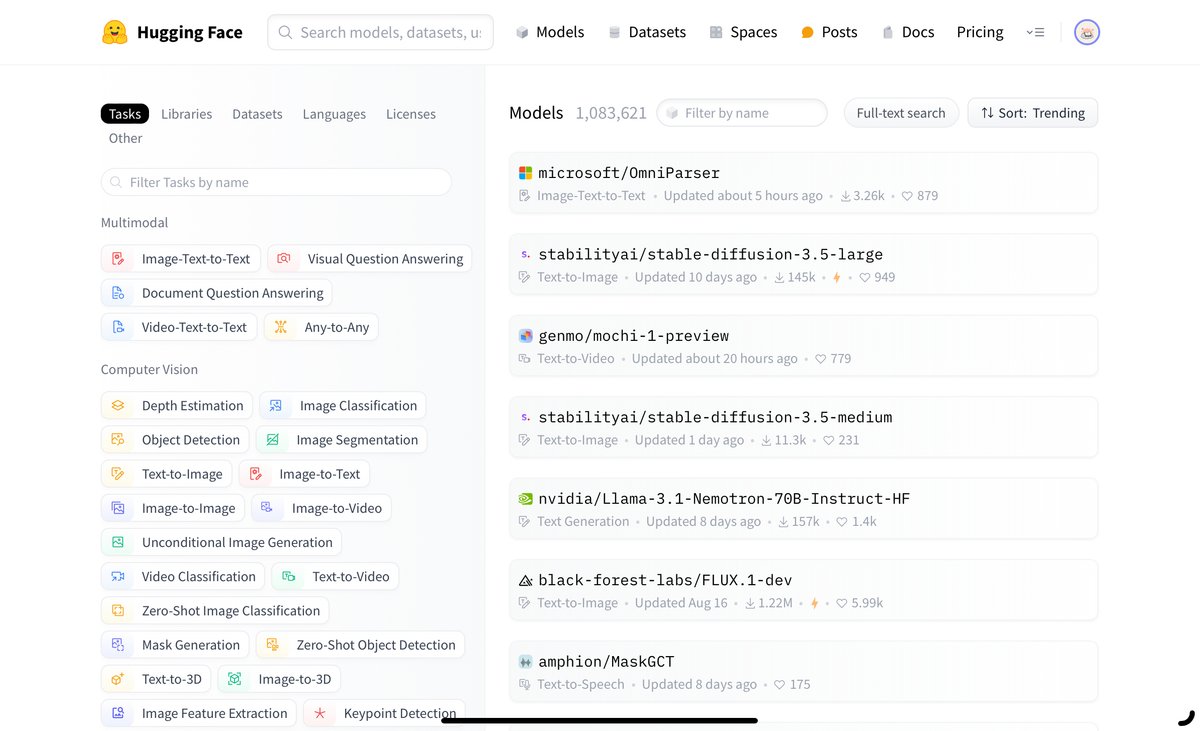
Hugging Faceでは、膨大な数のAIモデルが公開されており、特にテキスト生成、画像生成、音声処理など、いろいろなタスクに特化したものが多いです。慣れてきたら、各モデルには「モデル名」「バージョン」「パラメーター数」といった詳細情報が含まれており、それぞれの特徴をしっかり理解しながら選んでみるのも大事なプロセスですよ。
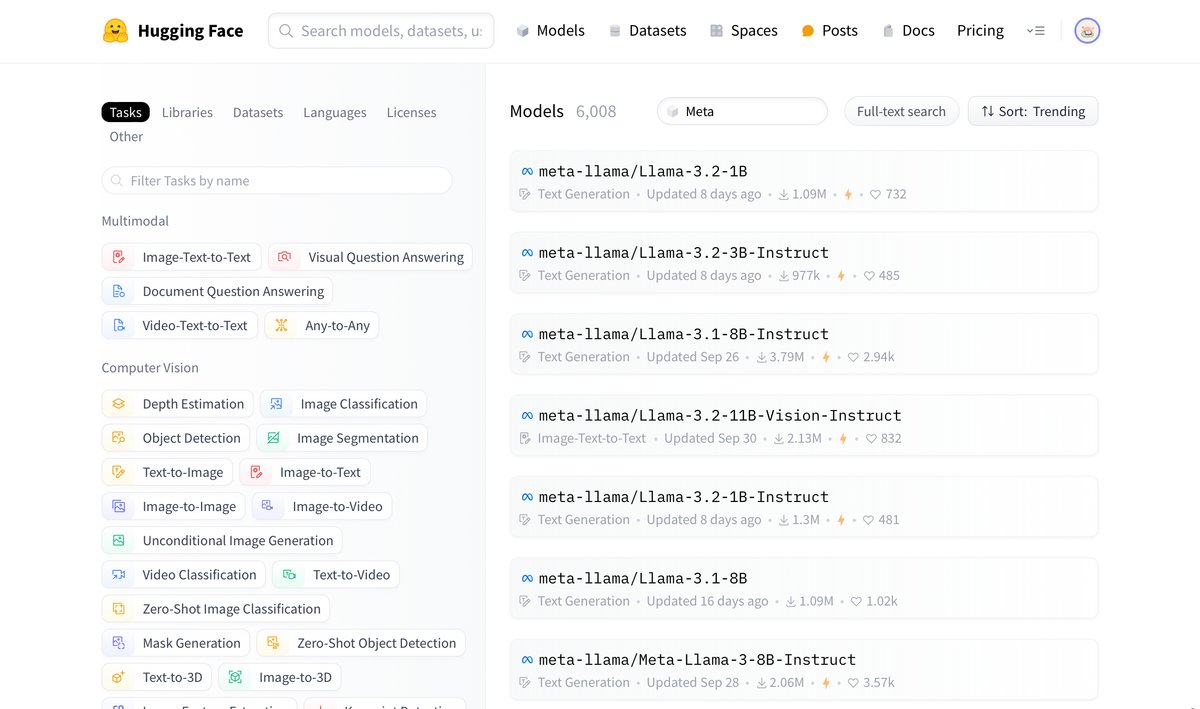
モデルの詳細ページ
各モデルの詳細ページには、利用条件やモデルの概要、アーキテクチャが記載されています。商業利用や学術研究における利用可否が明示されている場合も多く、他のプロジェクトに取り入れる際にも安心です。また、モデルの利用方法を示すサンプルコードが掲載されているため、初めての方でも実際にモデルを動かしてみることができますよ。
インフェレンスAPI
特定のモデルではインフェレンスAPIが提供されており、ウェブ上で動作を確認することができます。例えば「LLaMA 3.2 1B」などのモデルで、ブラウザから直接テストでき、モデルの実力を感じられるのが便利です。事前にインフェレンスAPIでモデルの精度やパフォーマンスを試すことができるので、アプリケーション開発の検討段階で役立ちますね。
データセットセクション(中級者向け)
データセットの共有と利用
Hugging Faceのデータセットセクションには、多くのユーザーが共有している自然言語データや画像データ、音声データなどが揃っています。特に、膨大なデータが必要となるAIの学習では、公開されているデータセットをうまく活用することで、プロジェクトがスムーズに進みます。また、データセットには詳細情報が記載されているため、安心して利用できるのも嬉しいですね。
スペースセクション
AIアプリケーションの共有プラットフォーム
「スペース」は、ユーザーが作成したAIアプリケーションを他の人々と共有し合える場です。画像生成アプリや、自然言語処理を使った会話アプリケーションなど、さまざまなジャンルのAIアプリケーションが公開されています。スペースを活用することで、他の開発者のアイデアを試してみたり、独自のアプリケーションを公開してフィードバックをもらえたりと、生成AIの技術を一人で学ぶのではなく、他の方々と一緒に育てる感覚が楽しめます。
Hugging Faceの活用方法
モデルの検索と絞り込み
Hugging Faceではモデル検索も簡単で、言語やタスクごとにフィルタリングができます。例えば、日本語対応モデルを探すときには言語フィルターを使うことで、すぐに該当するモデルが見つかります。数多くのモデルから目的に合ったものを選び出すのは、いわば宝探しのような楽しさがあるかもしれませんね。自分のプロジェクトに合うモデルを見つけ出すことで、生成AIの「魅力」を実感できるはずです。
アクセストークンの使用方法
Hugging Faceのサービス利用に必要なアクセストークンの取得方法と活用方法をご紹介しますね。
アクセストークンの発行手順
1. Hugging Faceのアカウントにログインします。
2. プロフィールメニューから「Settings」に移動し、「Access Tokens」セクションへ。
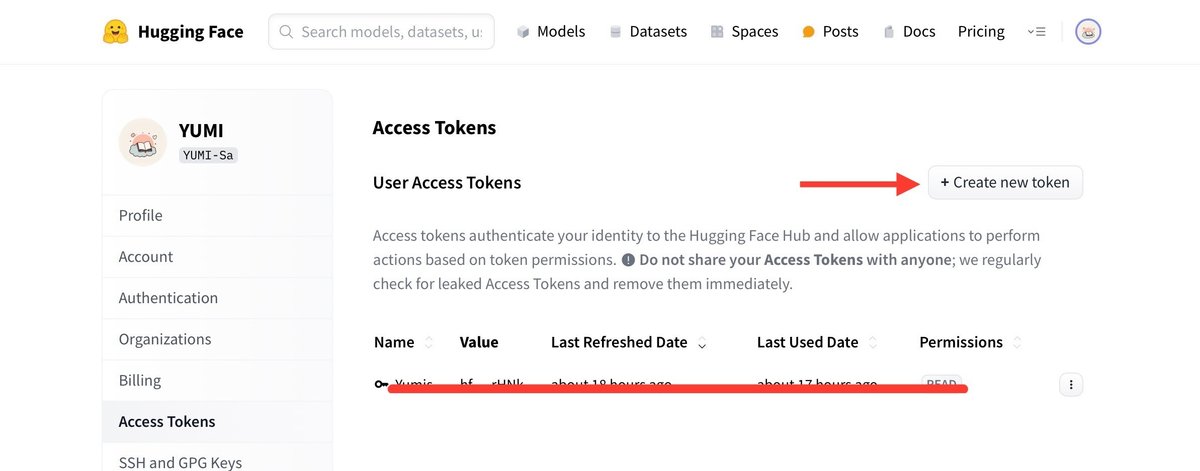
3. 「Crreate new token」をクリック
Fine-grained Read Writeを選び、必要事項を入力します。
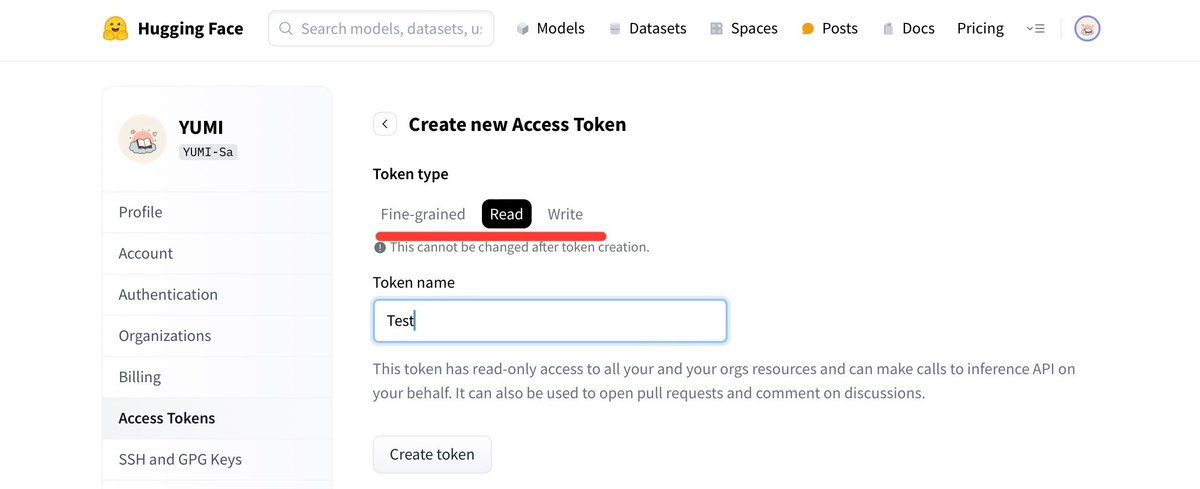
4. 作成されたトークンが表示されるのでコピーしてメモします。
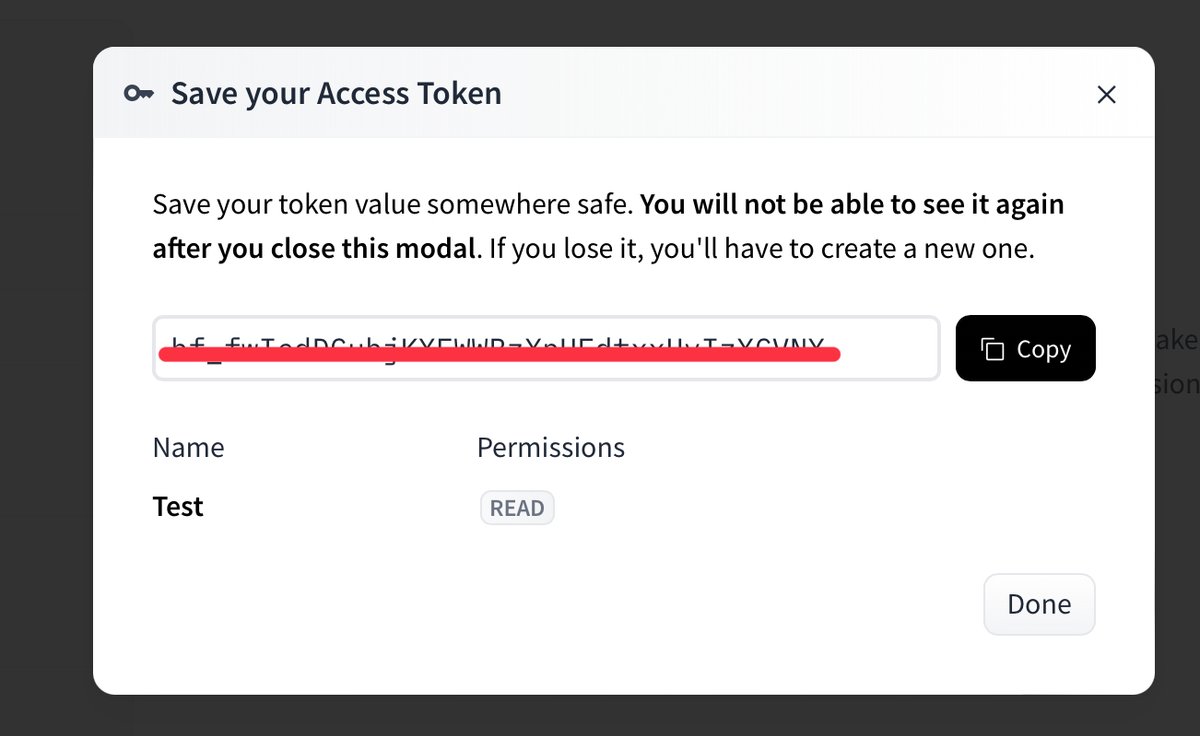
アクセストークンを用いた実装例
以下はPythonでのアクセストークン使用例です。
Hugging FaceのAPIを通じてモデルを呼び出しています。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# アクセストークンを設定
ACCESS_TOKEN = "your_access_token_here"
# モデルとトークナイザーをロード
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_auth_token=ACCESS_TOKEN)
model = AutoModelForCausalLM.from_pretrained(model_name, use_auth_token=ACCESS_TOKEN)
# テキスト生成の実行
inputs = tokenizer("Hello, how are you?", return_tensors="pt")
outputs = model.generate(inputs["input_ids"])
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
このように、アクセストークンを利用することで、商業利用や利用制限がかかっているモデルにも安心してアクセスできるようになります。
まとめ
🤗Hugging Faceの重要性
Hugging Faceは、AIモデルやデータセットを一元管理・共有するプラットフォームとして、研究から実務まで幅広く役立つ存在です。無料で多くの機能が利用できるため、初めてAIを触る方でも気軽に学べますし、プロとして実務で使いたい方にも頼りになる場所です。これからのAI技術の普及において、Hugging Faceは中心的な役割を担っていくでしょう。
次のステップ
Hugging Faceを使って気になるプロジェクトやモデルに触れて、生成AIの可能性をさらに体感してみましょう。また、アクセストークンを利用して、商業利用も視野に入れた実験を重ねていくことで、AIの力を活かした新しいチャレンジが始まるかもしれません。人とつながりながら、生成AIの夢を形にしていく道のりを、ぜひ楽しんでくださいね。
