
Difyを試す

この記事はなに?
存在は知っていたけどずっと放置していたので色々触ってみて、その際のメモをここに記録します。
前提として筆者はOpenAIのAPI、Docker、Git周りの知識は最低限持っている開発者です。
参考にした記事
API でAPIキー取得
AnthropicでもOpenAIでも、AWS Bedrockで利用できるモデルでもなんでもよいが、まずはDifyでモデルを利用するためにAPIキーを取得する。
OpenAIのキーを使いたい場合は👇️から取得する。
※あらかじめOpenAIのアカウントを作成しておく必要あり。
※ChatGPTのアカウントではなくOpenAIのアカウントであることに注意。
https://platform.openai.com/api-keys
ローカルでDockerを使って環境構築
クラウド版も利用できるがローカルに環境を作ってみる。
モジュール取得、起動
# クローン
git clone https://github.com/langgenius/dify.git
cd dify/docker
# 設定ファイルを複製
cp .env.example .env
# dockerバージョンチェック
docker compose version
→ Docker Compose version v2.29.7
# 起動
docker compose up -d
# プロセスチェック
docker compose ps※GB単位でファイルがDLされるようなので容量注意

たくさんプロセスが立ち上がる

モジュール最新化、再起動
cd dify/docker
git pull origin main
docker compose down
docker compose pull
docker compose up -dDifyへアクセス
http://localhost/install にアクセスすると、ローカルのDifyに入れるはず。
管理者情報を入力してセットアップを完了すると、ログインできるようになる。
セットアップ

ログイン後

会話アプリ機能でHello World.
モデル指定
画面右上のユーザーアイコンから「設定 > モデルプロバイダー」でデフォルトモデルを選択

API Baseという項目は、独自APIを用いた拡張を行いたい際のURLっぽい?一旦空欄にする。

システムモデルを設定しろとアラートが出ているので追加で適当に設定。

アプリを作成する
アプリを作成する > 最初から作成 から、チャットボットをまず作る。

動いた

コンテキスト(ナレッジ)を追加
画像認識機能
どのモデルをどういったパラメータを用いて利用するかを比較検証(デバッグ)
作ったものを独立したAIアプリとして生成・公開
などが可能。👇️参考。
ナレッジ機能
基本
RAGを構築する際は、知識データベースを事前準備する必要がある。
Difyでは外部リソースをナレッジとして扱うこともできるが、Dify上にファイルをアップロードしてそれをナレッジとして扱うことも可能。

設定周り
結構細かく設定できるしオプションが充実してる。RAGはチャンキングや全文検索とのハイブリッド、ナレッジからの検索結果の評価方法など勘所が多いが、ある程度ケアされている感じ。

「自動」は将来的に廃止になるらしい
セグメンテーションとクリーニングは2つの設定方法をサポートしています。
・自動モード(近日廃止予定)
・カスタムモード
このように👇️ベクトル検索か全文検索か、ハイブリッド検索かを選択可能。

※ハマりどころ
現時点でDifyのバージョン0.11.1を使用しているが、デフォルト状態だといつまで経っても「キューイング(queueing)」のままアップロードしたドキュメントのナレッジ登録が完了しなかった。フロントエンド側のエラーをDevtoolで確認すると、何やら 404 file not found のエラーを吐いていた。
原因・解決方法
Github上にドンピシャのDiscussions があった。
.env 上の
# ------------------------------
# Server Configuration
# ------------------------------の欄の `LOG_FILE` の値を明示的に指定することで解決するらしい。
以下の通り変更し、
# ------------------------------
# Server Configuration
# ------------------------------
# The log level for the application.
# Supported values are `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`
LOG_LEVEL=INFO
# Log file path
LOG_FILE=/app/logs/server.log
# Log file max size, the unit is MB
LOG_FILE_MAX_SIZE=20
# Log file max backup count
LOG_FILE_BACKUP_COUNT=5
# Log dateformat
LOG_DATEFORMAT=%Y-%m-%d %H:%M:%S
# Debug mode, default is false.
# It is recommended to turn on this configuration for local development
# to prevent some problems caused by monkey patch.
DEBUG=false以下のコマンドで再起動したら、キューイング中のまま処理が完了しない事象が解決できた。
docker compose down
docker compose up -dエージェント機能
Difyでいう「エージェント」の定義
エージェントアシスタントは、大規模言語モデルの推論能力を活用し、複雑な人間のタスクを自律的に目標設定、タスク分解、ツールの呼び出し、プロセスのイテレーションを行い、人間の介入なしでタスクを完了することができます。
アプリを作成する
先程は「チャットボット」を新規作成したが、今回は「エージェント」を新規作成する。
「ツール」でウィキペディアを指定

動かしてみると、ちゃんと日本版Wikipediaに対して検索をかけて、情報を拾ってきた。

実際のWikipedia👇️。ちゃんと拾ってきている。

微妙なところ
Wikipediaの記事の中段に記載された記載された情報について質問してみても、情報が得られなかった。

👇️Wikipediaの記事中段二記載されている内容。

google_search を更に追加するとよい返答が得られるようになった。

※Googleサーチを使うには
初期状態では、google_searchは非活性化されており利用できない。
→SerpApi を活用してAPI経由でデータ取得するようなので、SERPのアカウント登録とAPIキー取得を行う必要あり。

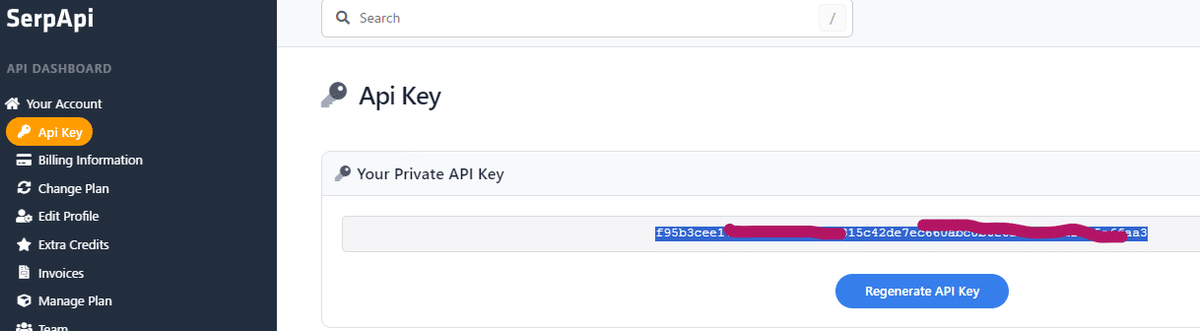
ツールとしてWikipediaとGoogle_Searchを追加したわけだが、チャット上での使い方はこれでいいのか?(WikipediaとGoogle_Searchの使い分けは質問に応じて良しなに行われる?)

DALLE-3をツールに追加したら絵も描いてくれた。

会話アプリとエージェントとワークフローの違い
おおよそ👇️のような感じ?
会話:いわゆるチャット機能。外部機能呼び出しはなし。
ただしRAG機能はあり(別途登録したナレッジを検索・参照可能)
エージェント:チャット機能+外部機能呼び出し。
ワークフロー機能も呼び出して使える
ワークフロー:処理のプロセスを定義したうえでタスクを実行させる。
もちろん外部機能も呼び出し可能
ワークフローほどではないが機能の埋め込みも可能
前述の内容では「ツール」にてエージェント内で活用したい機能を追加できたが、別途「機能」の追加が可能。

例えば「会話の開始」機能を有効にすると👇️のようにオープニングのAIアシスタント側からの切り出しを設定できるようになる。

すると👇️こうなる。ユーザー側はオープニングでAIアシスタントから提示された選択肢を選択しただけ。
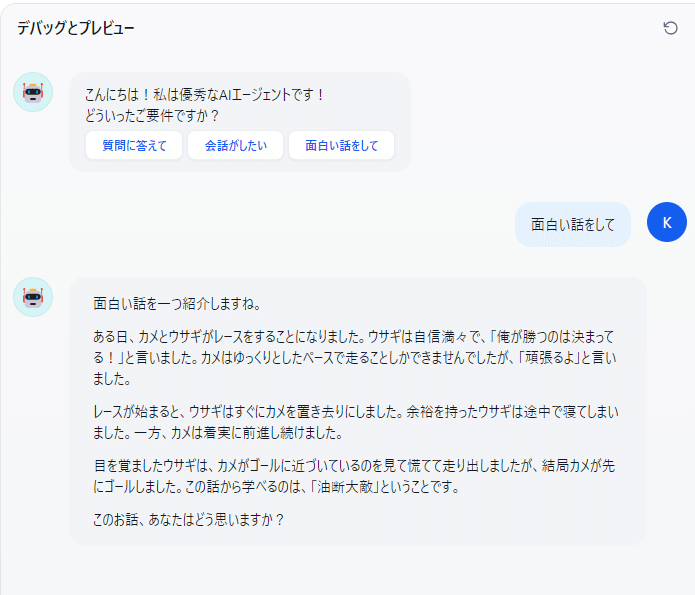
他にも、エージェントの返信内容を音声に変換する機能や、ユーザーがテキストを入力する際に音声からの入力にすることも可能
ワークフロー
ワークフローの基本
概要:
複雑なタスクを小さなステップ(ノード)に分解してそれを組み合わせて1つのシステムとして動作させるもの
単純な会話やエージェントよりもパファーマンス👇️の向上を期待
システムの解釈性
安定性
耐障害性
ワークフローには「チャットフロー」「ワークフロー」の2種類あり
一般的なケース:
カスタマーサービス
コンテンツ生成
タスク自動化
データ分析とレポート
メール自動化処理
アプリを作成する
続きは後日追記する