爆サイのレス投稿時刻のヒストグラム




とりあえず。これで。
import requests
from bs4 import BeautifulSoup
import datetime
from urllib.parse import urljoin
from datetime import datetime
from collections import Counter
# BASE_URL = "https://bakusai.com/thr_res/acode=3/ctgid=103/bid=416/tid=12316263/tp=1/rw=1/" # 最新
BASE_URL = "https://bakusai.com/thr_res/acode=3/ctgid=103/bid=416/tid=12301117/tp=1/rw=1/" # 前のスレ
# https://bakusai.com/thr_res/acode=3/ctgid=103/bid=416/tid=12316263/p=2/tp=1/rw=1/
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
def main():
all_hour_list = []
for i in range(1,21):
url = f"{BASE_URL}p={i}/"
# print(f"retriving on {url}")
# all_hour_list.append(get_post_times(url))
all_hour_list = all_hour_list + get_post_times(url)
print("final result")
print(all_hour_list)
counter = Counter(all_hour_list)
for num, count in sorted(counter.items()):
print(f'{num} : {"." * count}')
def get_post_times(url):
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.text, 'html.parser')
elements = soup.select('dt > div > span[itemprop="commentTime"]')
page_hour_list = []
for element in elements:
time_obj = datetime.strptime(element.text, '%Y/%m/%d %H:%M')
hour = time_obj.hour
page_hour_list.append(hour)
print(page_hour_list)
return page_hour_list
if __name__ == "__main__":
main()
1Round前スレ

Cute前スレ
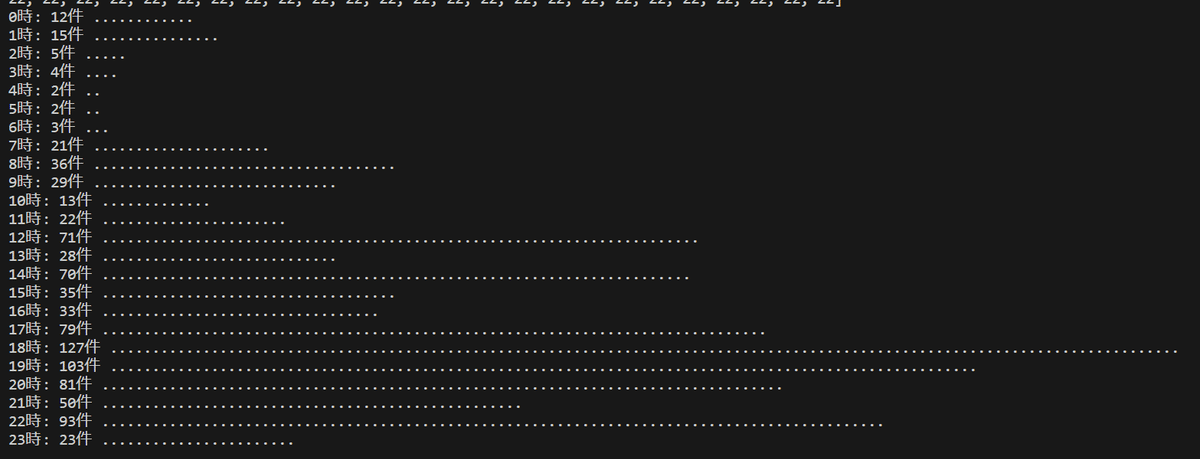
cute前スレ分との相関係数。
hour 1r cute
0 26 12
1 13 15
2 9 5
3 6 4
4 6 2
5 10 2
6 27 3
7 30 21
8 104 36
9 83 29
10 44 13
11 38 22
12 55 71
13 29 28
14 33 70
15 47 35
16 38 33
17 21 79
18 45 127
19 50 103
20 60 81
21 98 50
22 67 93
23 45 23
1rとcuteの相関係数rは、r=0.408でした。