
フォロワー10万人への道

とあるキャストさんから、私が書いた口コミは「参考になった」数が多いとのお褒めのお言葉をいただきました。
ただ思うのは、参考になっているかどうかは正直自信がないのです。ですから、最後まで読んでくれた人の一部の方が、ありがたいことに「みたよ」的な意味合いで「参考になった」ボタンをクリックしてくれているんだと思います。
ところで、いろいろな口コミの「参考になった数」をみてみると、ざっくりですが、10分の1のフォロワーが参考ボタンを押す仮説が浮かんできました。つまり、単純にフォロワーを増やせば、その一定割合の方々は「参考になった」ボタンを押してもらえそうです。10万人のフォロワーを得たなら、1万人の「参考になった」というわけです。
なので、とっかかりとして相互フォローを増やそうと思っていまして、なにも深く考えずマウスでポチポチやってみましたが、10万人フォローまで何日かかるのでしょう?1日100人増やしたとして1000日≒2年8ヶ月です。途中で飽きてやめてしまうでしょう。
そこで、ちょっとしたスクリプトを書いて、よく利用させていただいている大宮のお店、ラブアンドピース様、1Round様へ口コミを書いているユーザ全員フォローすることにしてみました。
現状のフォロー数・フォロワー数
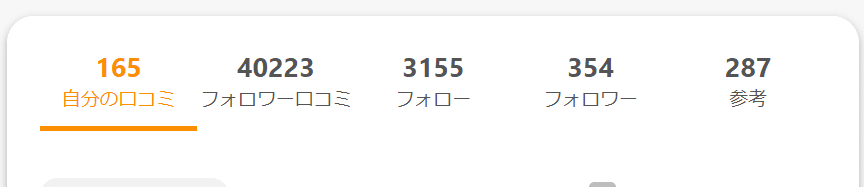
10月14日時点、それぞれ、225名、326名でした。

フォロワー数が300ぐらいですので、参考になったの数も多くて30程度でした。

フォロー実行後の結果
結果のスクショを貼っていきます。
ラブアンドピース口コミユーザ
ラブアンドピースの口コミユーザ全員フォローしました。フォロー225➔1802名になりました。

1Round口コミユーザ
1Round口コミユーザを全員フォローしました。フォロー数が3155名に増えました。
スクリプト
スクリプトは「URL抽出用」と「フォロー用」に段階を分けています。
URL抽出用
#####
# Create a text file including home urls for each heaven user
# 2024.10.15
from selenium import webdriver
# from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
shop_kuchikomi_top_url = "https://www.cityheaven.net/saitama/A1101/A110101/loveomiya/reviews/1/" # lovep
# shop_kuchikomi_top_url = "https://www.cityheaven.net/saitama/A1101/A110101/one-round/reviews/1/" # 1round
text_file = "lovep_user_urls.txt"
# text_file = "one_round_urls.txt"
userlinks = []
def main():
options = Options()
options.add_argument('--ignore-certificate-errors') # avoid ssl error
options.add_argument('--ignore-ssl-errors')
options.add_argument('--log-level=1') # avoid TensorFlow message
options.page_load_strategy = 'normal'
global driver
driver = webdriver.Chrome(options=options)
driver.get(shop_kuchikomi_top_url)
while True:
get_heaven_user_home_url()
last_page_check = detect_next_button()
if last_page_check == "next":
print("go to next page")
next_button_element = driver.find_element(By.CLASS_NAME,"next")
driver.execute_script("arguments[0].click();", next_button_element) # to click element out of view
else:
print("last page detected")
break
def get_heaven_user_home_url():
userlinks = []
print("retriving on " + driver.current_url)
try:
review_elements = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME,"review-item"))
)
for review_element in review_elements:
try:
usernameurl = review_element.find_element(By.XPATH,'.//div[1]/div[1]/div/div/p/a').get_attribute('href')
except:
usernameurl = "url deleted"
userlinks.append(usernameurl)
except TimeoutError:
print("Timeout while wating for review items.")
print(*userlinks, sep="\n")
with open(text_file, mode="a") as o: # write urls in a text file
print(*userlinks, sep="\n", file=o)
def detect_next_button():
try:
next_button_elements = driver.find_element(By.CLASS_NAME,"next")
print("detect next button")
return "next"
except NoSuchElementException:
print("No next button found")
return "last"
if __name__ == '__main__':
main()
参考:ユニークURL
ラブアンドピースの口コミ件数は6044件でした。ユーザの重複を排除したところ、1716件でした。重複排除はシェルでやっちゃいました。

フォロー用
URL抽出用で生成されたURL一覧を含むテキストファイルを読み込ませてひたすらフォローします。フォロー済みのユーザはスキップする処理にしています。
#####
# Follow users listed in a text file
# 2024.10.14
from selenium import webdriver
import config
import datetime
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
USERS_TO_FOLLOW = "lovep_user_urls_uniq.txt"
LOGIN_PAGE = 'https://www.cityheaven.net/mypage/login/'
def main():
options = Options()
# options.add_argument('--headless') # headless mode
options.add_argument('--blink-settings=imagesEnabled=false') # do not download images
options.add_argument('--ignore-certificate-errors') # avoid ssl error
options.add_argument('--ignore-ssl-errors')
options.add_argument('--log-level=1') # avoid TensorFlow message
options.page_load_strategy = 'normal'
global driver
driver = webdriver.Chrome(options=options)
heaven_login(LOGIN_PAGE) # login
now = datetime.datetime.now()
print(f"start at {now}")
with open(USERS_TO_FOLLOW) as f: # open text file
for userurl in f: # read each line
follow_user(userurl) # follow user
now = datetime.datetime.now()
print(f"finish at {now}")
def heaven_login(url):
driver.get(url)
email = driver.find_element(By.XPATH,'//*[@id="user"]')
email.send_keys(config.username)
password = driver.find_element(By.XPATH,'//*[@id="pass"]')
password.send_keys(config.password + '\n')
def follow_user(url):
driver.get(url)
try:
element = driver.find_element(By.CLASS_NAME,"button-outline._user.follow-btn:not(.is-follow)")
driver.execute_script("arguments[0].click();", element)
print(url.strip('\r\n') + " has been added for your follow memebers !")
except NoSuchElementException:
print(url.strip('\r\n') + " is existing as your following member.")
if __name__ == '__main__':
main()
これとは別にシティヘブンログイン用のIDとパスワードを書いたconfig.pyを作り、同一ディレクトリに置いてください。
# config.py
username = "youremailaddress@yourdomain.com"
password = "yourpassword"サーバ負荷によるアクセス拒否の懸念
実質、ブラウザ操作をエミュレートしているだけで、1ページ約3秒毎ぐらいのアクセスになっていました。アクセス拒否の懸念はないと考えています。
余談
最多の人で84件も!しかも同じ女の子に!口コミ拝見しました。すごいです!
