
Frosty Friday Week3 Basic

こんばんは。m.fujitaです。
2度目のFrosty Fridayチャレンジになります。
今日はWeek3を解いてみます。
できるときにできることを。
まずはBasicを自分のペースで解いていきます。
Frosty Fridayとは
Frosty Fridayは、Snowflakeユーザーによって作成された、Snowflakeのスキル向上を目的とした週次チャレンジシリーズです。2022年7月14日に開始され、毎週金曜日に新しい課題が公開されています。
各チャレンジは、Snowflakeの特定の機能に焦点を当てており、タイムトラベルやパイプ、データ変換、ストリームなど、多岐にわたります。課題は「基本」「中級」「上級」の3つのレベルに分類されており、主にSQLを使用しますが、希望に応じてJavaやPythonを使用するオプションも提供されています。
Frosty Friday Live Challenge Vol 1
解説のYoutubeはこちらにあります。
はじめは自分で
Youtubeで写経する前にまずは自分で考えてみます。
Week1と似た感じでs3のファイルをステージにロードして
Keywords.csvに出てくるキーワードが入っているものを抽出するとのこと・・・なるほど。
ということで、ここまではほぼWeek1と同じ。
use role accountadmin;
GRANT USAGE ON WAREHOUSE compute_wh TO ROLE sysadmin;
use role sysadmin;
use warehouse compute_wh;
--DB/スキーマの新規作成
create database if not exists frosty_friday;
use database frosty_friday;
create schema if not exists frosty;
use schema frosty_friday.frosty;
create or replace stage data_dumps_week3
url = 's3://frostyfridaychallenges/challenge_3/';
--外部ステージの中身を確認
list @data_dumps_week3;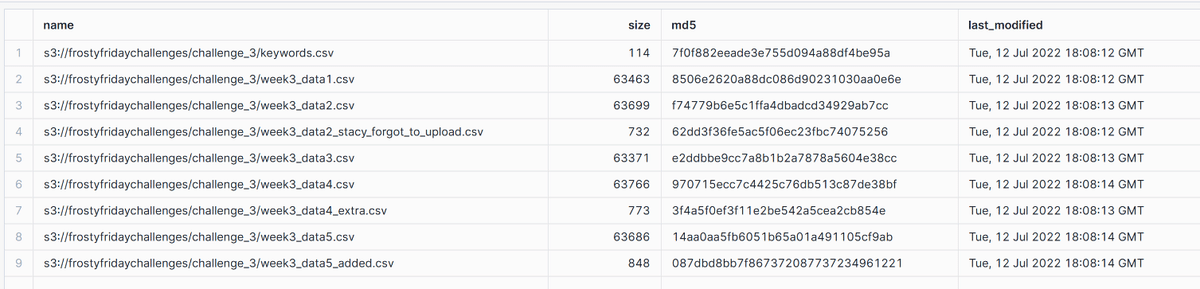
ここまでは理解。
あれ?で、どのようにしてKeywords.csvの中身を確認のか分からなくなりました。
ということで、Youtubeを再生。
Keywords.csvの内容
Youtubeを確認したところ、以下のSQLで確認できるそうです。
--keywords.csvの中のキーワード確認
--metadataを表示するときは、metadata$を使って記載できる
--https://docs.snowflake.com/ja/user-guide/querying-metadata
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1,$2,$3,$4
from @data_dumps_week3/keywords.csv;metadata$を使ってメタデータを取得できます。
こちらのページも覚えておきましょう。
【疑問】ファイルの内容を確認するときに$の数はどうやって分かるのでしょうか?下記だと$4が全部nullなので$3までで良さそうです。

ChatGPTさんに聞いてみたらこんな風に返ってきました。
Snowflakeでステージ(@stage_name)にあるデータを直接クエリする場合、*は利用できません。個々のカラムを$1, $2, $3と番号で指定する必要があります。
理由
ステージにあるデータは、Snowflakeのテーブル形式として構造化されていないため、カラム名を自動的に認識する仕組みがありません。そのため、$1, $2, $3といったプレースホルダ形式でしかカラムを参照できないのです。
なるほど、分かったような分からないような・・・
とにかくS3から取得したステージの内容を見るときは
metadata$~
$~
で確認できるよということを覚えておくことにします。
week3_data2_stacy_forgot_to_upload.csvの中身を確認
Keywords.csvの中にあった、week3_data2_stacy_forgot_to_upload.csvの内容を確認していきたいと思います。
--week3_data2_stacy_forgot_to_upload.csvの中身を確認
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1,$2,$3,$4,$5,$6,$7
from @data_dumps_week3/week3_data2_stacy_forgot_to_upload.csv;
このように、$5まで値が入っているようです。
1行目にはカラム名が入っているみたいなので、下記のように書き直します。
--上記の結果を見ながらフィールド名を記載していく
--week3_data2_stacy_forgot_to_upload.csvの中身を確認
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as id,
$2 as first_name,
$3 as last_name,
$4 as catch_phrase,
$5 as timestamp
from @data_dumps_week3/week3_data2_stacy_forgot_to_upload.csv;
このように1行目と同じタイトルが表示されました。
ファイルをSnowflakeテーブルに書き込むときはFile formatを作ってからCOPY INTO!
ローデータ
データを確認するときにフィールド名を指定しておくとcopy into fromの後のSelect文が書きやすい
とコード内に書いた意図は、下記のCOPY INTO FROM以下のSelect文について確認時のSQLをコピーできるので作りやすいと考えたからです。
--ファイルフォーマットの作成
create file format csv_week3_basic_skip_header
type ='CSV' //ファイルタイプ
field_delimiter = ',' //区切り文字の設定
skip_header = 1; //1行目をスキップする
--テーブルの作成
create or replace table week3_basic(
file_name varchar,
number_of_rows varchar,
id varchar,
first_name varchar,
last_name varchar,
catch_phrase varchar,
timestamp varchar
);
--ローデータをコピーする
--データを確認するときにフィールド名を指定しておくとcopy into fromの後のSelect文が書きやすい
copy into week3_basic
from (
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as id,
$2 as first_name,
$3 as last_name,
$4 as catch_phrase,
$5 as timestamp
from @data_dumps_week3
)
file_format = 'csv_week3_basic_skip_header';Keywords
--ファイルフォーマットの作成
create file format csv_week3_basic_skip_header
type ='CSV' //ファイルタイプ
field_delimiter = ',' //区切り文字の設定
skip_header = 1; //1行目をスキップする
--Keywordを入れるテーブルの作成
create or replace table week3_keywords_raw(
file_name varchar,
number_of_rows varchar,
keyword varchar,
added_by varchar,
nonsense varchar
);
--week3_keywords_rawにKeywords.csvのデータをコピーして挿入する
copy into week3_keywords_raw
from (
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as keyword,
$2 as added_by,
$3 as nonsense
from @data_dumps_week3/keywords.csv
)
file_format = 'csv_week3_basic_skip_header'
pattern = 'challenge_3/keywords.csv'; --パターンを固定で書くLike any?!?!
keywordsが含まれるファイル名ごとのデータ件数を調べる・・とのことで
tomoさんが紹介されていた、LIKE ANY
初めて知りました。
--containsの代わりにLike anyを使ってみる
select
file_name,
count(*) as number_of_rows,
from week3_basic
where file_name like any (select '%'|| $3 ||'%' from week3_keywords_raw)
group by file_name;tomoさんはYoutubeでこのように書かれていたのですが、$3ってなんだっけ?ってなりそうだな・・・と思い、フィールド名は使えるだろうか?と試しにやってみました。
--containsの代わりにLike anyを使ってみる
select
file_name,
count(*) as number_of_rows,
from week3_basic
where file_name like any (select '%'|| keyword ||'%' from week3_keywords_raw)
group by file_name;うごいたーーーー!!!!やったぜっ

最終的なコード
use role accountadmin;
GRANT USAGE ON WAREHOUSE compute_wh TO ROLE sysadmin;
use role sysadmin;
use warehouse compute_wh;
--DB/スキーマの新規作成
create database if not exists frosty_friday;
use database frosty_friday;
create schema if not exists frosty;
use schema frosty_friday.frosty;
create or replace stage data_dumps_week3
url = 's3://frostyfridaychallenges/challenge_3/';
--外部ステージの中身を確認
list @data_dumps_week3;
--keywords.csvの中のキーワード確認
--metadataを表示するときは、metadata$を使って記載できる
--https://docs.snowflake.com/ja/user-guide/querying-metadata
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1,$2,$3,$4
from @data_dumps_week3/keywords.csv;
--1行目を見ながらフィールド名を設定する
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as keyword,
$2 as added_by,
$3 as nonsense
from @data_dumps_week3/keywords.csv;
--week3_data2_stacy_forgot_to_upload.csvの中身を確認
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1,$2,$3,$4,$5,$6,$7
from @data_dumps_week3/week3_data2_stacy_forgot_to_upload.csv;
--上記の結果を見ながらフィールド名を記載していく
--week3_data2_stacy_forgot_to_upload.csvの中身を確認
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as id,
$2 as first_name,
$3 as last_name,
$4 as catch_phrase,
$5 as timestamp
from @data_dumps_week3/week3_data2_stacy_forgot_to_upload.csv;
--ファイルフォーマットの作成
create file format csv_week3_basic_skip_header
type ='CSV' //ファイルタイプ
field_delimiter = ',' //区切り文字の設定
skip_header = 1; //1行目をスキップする
--テーブルの作成
create or replace table week3_basic(
file_name varchar,
number_of_rows varchar,
id varchar,
first_name varchar,
last_name varchar,
catch_phrase varchar,
timestamp varchar
);
--Keywordを入れるテーブルの作成
create or replace table week3_keywords_raw(
file_name varchar,
number_of_rows varchar,
keyword varchar,
added_by varchar,
nonsense varchar
);
--week3_keywords_rawにKeywords.csvのデータをコピーして挿入する
--データを確認するときにフィールド名を指定しておくとcopy into fromの後のSelect文が書きやすい
copy into week3_keywords_raw
from (
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as keyword,
$2 as added_by,
$3 as nonsense
from @data_dumps_week3/keywords.csv
)
file_format = 'csv_week3_basic_skip_header'
pattern = 'challenge_3/keywords.csv'; --パターンを固定で書く
--コピーした中身の確認
select * from week3_keywords_raw;
--ローデータもコピーする
copy into week3_basic
from (
select
metadata$filename as file_name,
metadata$file_row_number as file_row_number,
$1 as id,
$2 as first_name,
$3 as last_name,
$4 as catch_phrase,
$5 as timestamp
from @data_dumps_week3
)
file_format = 'csv_week3_basic_skip_header';
--ローデータのコピー内容を確認
select * from week3_basic;
--ローデータからキーワードテーブルに入っているレコード数を確認
select
file_name,
count(*) as number_of_rows,
from week3_basic
where exists(
select keyword
from week3_keywords_raw
where contains (week3_basic.file_name ,week3_keywords_raw.keyword) --FilenameにKeywordが含まれている
)
group by file_name;
--containsの代わりにLike anyを使ってみる
select
file_name,
count(*) as number_of_rows,
from week3_basic
where file_name like any (select '%'|| keyword ||'%' from week3_keywords_raw)
group by file_name;まとめ
Week1は完全に写経でコーディングしていたので、あまり意味が理解できていなかったのですが、Week3では自分で「なぜ」を見つけて、それを検索して理解しながら進めたので、理解が深まりました。
やっぱりアウトプットしながら解くって大事ですね。
そして、1日坊主から抜け出せた!というのは自分で褒めたいと思います。
私今日も頑張ったぜ!