
Minio + DuckDB + dbt + Airflowでローカルにデータ基盤を立ててみる

かなり久しぶりの投稿になりました
ここ3年ちょっとほどデータ系の分野が楽しく、データエンジニアをやっています
何年データエンジニアとしてやっていくかはまだ未知数ですがしばらくはこちらの道でやっていきたいと思っています
今日はミニデータ基盤としてMinio + DuckDB + dbt + Airflowでかなり楽にローカルにデータ基盤を立てられるよという紹介をしたいと思います
リポジトリ
こちらとなります
(まだ足りていない部分が割とありますが…)
使用するツールのざっくりとした紹介
Minio
オブジェクトストレージサーバーで、Amazon S3と互換性がある
ローカル環境でも簡単にセットアップできる
DuckDB
組み込み型SQLデータベースエンジン
ポータブルでインストールが簡単
クエリ処理性能が高速
分析用途に適している
dbt (Data Build Tool)
データ変換ツール
SQLとJinjaテンプレートを利用してデータモデルを構築
テスト、ドキュメント生成、実行ログ機能など付加価値の高い機能を提供
Airflow
データ処理フローを管理するワークフローマネジメントシステム
タスクの並列実行、モニタリング、スケジューリングが可能
Python製なので拡張性が高い
環境構築手順
環境のセットアップは全てdocker composeで行います
手順はREADMEに書いた通りとなりますが、単純にdocker compose up -dを行うだけです
docker-compose.yamlはAirflowの公式で取得できる雛形を少しいじったものとなります
取得した雛形に追加したサービスは以下の二つです
minio: minioのサーバーを立ち上げるサービスとなります
mc: 起動したminioのサーバーに対してバケットを作成したり、動作確認用のオブジェクトを格納したりしています
サンプルデータの取り込みとデータ変換
データの流れ
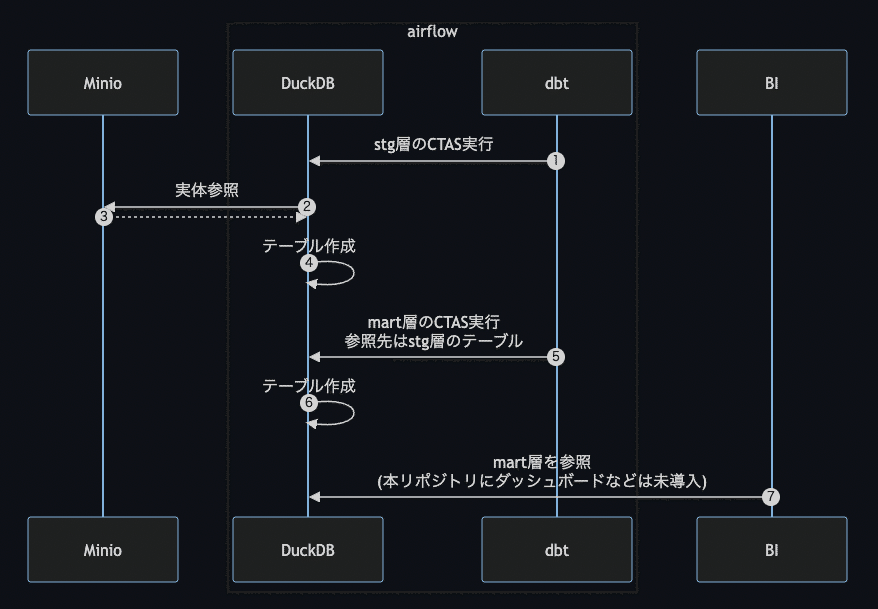
サンプルデータはdocker compose up時にすでにMinioのバケットに投入されていることを前提とする
dbtに作成したモデル(データを変換するためのSQL)により、DuckDB上にテーブルが作成される(staging層)
DuckDB上にテーブルが作成されるとき、参照するデータの実態はMinioに存在している
※今回のリポジトリではcsvファイルとしていますが、ここはtsvでもjsonlでもparquetでもOK(ファイルによってread関数が変わる)2で作成したテーブルを加工、集計してさらに新しいテーブルを作成する(mart層)
(このリポジトリで実装はしていないが)BIツールなどからmart層のテーブルへ参照が発生し、可視化が行われる
という流れになります
dbtによるデータ変換について
まず、dbt関連の資材は`{root}/workflow/dbt`に格納しています
dbtディレクトリ配下の構成は以下のようになっています
# ディレクトリ構成
dbt/
models/
dbt/
staging/
mart/
dbt_project.yml(深い考えがないまま作成してしまいましたが、modelsの配下のdbtは要らなかったかも)
staging層となるSQLはstagingディレクトリに、mart層となるSQLはmartディレクトリに格納しています
stagingの一例としてstg_orders.sqlについて少し説明します
{{ config(materialized='incremental', unique_key='order_id') }}
WITH renamed AS (
SELECT
CAST(id AS VARCHAR) AS order_id,
CAST(user_id AS VARCHAR) AS customer_id,
CAST(order_date AS DATE) AS order_date,
CAST(status AS VARCHAR) AS status,
CAST(year AS VARCHAR) AS order_year,
CAST(month AS VARCHAR) AS order_month
FROM
{{ source('external_source', 'stg_orders') }}
{% if var('target_year', '') != '' and var('target_month', '') != '' %}
WHERE
year = '{{ var('target_year') }}'
AND month = '{{ var('target_month') }}'
{% endif %}
)
SELECT * FROM renamedSQLのスタイルについては基本的にdbtの提唱するstyle guideに乗っかっています
上記のSQLは
{{ config(materialized='incremental', unique_key='order_id') }}
このモデルはフルリフレッシュでなく、インクリメンタルに構築することを指定
order_idが一意キーとして使用される
WITH renamed AS (...)
ソースデータから列名を変更し、適切なデータ型にキャストするための一時テーブル
CAST(...)関数
元のデータ型を目的の型に変換する
{{ source('external_source', 'stg_orders') }}
external_sourceソースからstg_ordersテーブルを参照
external_sourceは同階層に置いているorders.ymlを参照
{% if var('target_year', '') != '' and var('target_month', '') != '' %}
dbtの変数target_year、target_monthが設定されている場合のみ実行
WHERE年 = '{{ var('target_year') }}' AND 月 = '{{ var('target_month') }}'
変数の値に基づいてフィルタリング条件を動的に設定
MinioへデータをHIve形式のパーティションで分割して置いているので、パーティションプルーニング効果=不要なデータを読み込まないことによるクエリの高速化を期待している
SELECT * FROM renamed
変換された列を含む一時テーブルからすべての列を選択
という意味となります
staging層なのであくまでも最低限の加工を意識したものとなります
TIPS: staging層とmart層について
何の説明もなくstagingとmartという言葉を出しましたが、以下のような意味合いで使用しています
staging層
ソースデータを取り込んだ生データを、最低限の加工だけを施したデータ
例えばCSVデータをロードしてカラム名を適切に変更する、データ型を合わせるなど
複雑な集計や加工は行わない
mart層
staging層のデータから、さらに集計や加工を施して分析用のデータセットを作成
factテーブルやdimensionテーブルなどが含まれる(参考:スタースキーマ)
データマートを構築するイメージ
データ分析の目的に合わせて、フラットでクエリしやすい形式に変換される
データ処理フローの自動化
ここまでで、DuckDBにサンプルデータを取り込み、dbtを使ってデータモデルを構築し、クエリ可能な形で分析用データセットを作成できます
しかし、これらの一連の処理を手動で実行するのは効率が悪くデータパイプラインとして自動化する必要があります
この「データパイプラインの自動化」にAirflowを使用しています
Airflow関連の資材は`{root}/workflow/airflow`に格納しています
airflowディレクトリ配下は以下のような構成になっています
airflow/
config/
airflow.cfg
dags/
run_dbt.py
plugins/
Dockerfileairflow.cfgの中身は
[core]
# The folder where your airflow pipelines live, most likely a
# subfolder in a code repository. This path must be absolute.
dags_folder = /opt/airflow/dagsだけとなっています
ここでは/opt/airflow/dagsをDAGファイルの格納ディレクトリと指定していて、この配下に新しいDAGファイルを追加、あるいは既存DAGファイルの更新を行うとworkflowにもそれらの変更が反映される仕組みとなります
よって、dagsディレクトリは/opt/airflow/dagsと共有され(docker composeのvolume設定により、ホストとコンテナ間で共有しています)配下のrun_dbt.pyを更新するとその設定が数秒でworkflowに反映されます
run_dbt.pyの中身は割と簡単なことしか行っていないので解説は避けますが、やっていることは
workflowの実行パラメータとして対象日付が渡されるためそれを年月に整形
1で整形した対象年月をdbtのvarsとして渡しながらdbt runを実行
データの確認としてselect * from tableを行い、結果をログに出力
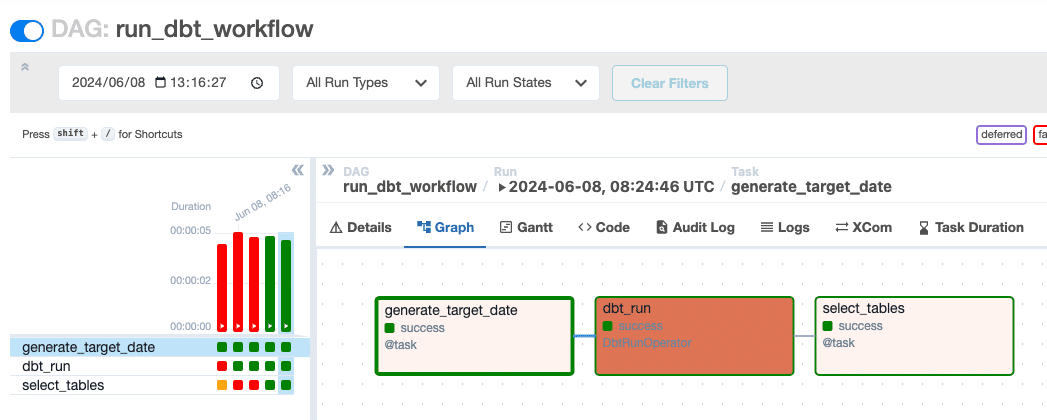
となります
まとめ
簡単にはなりますが、以上がMinio + DuckDB + dbt + Airflowでローカルにデータ基盤を立てる解説となります
Minio、DuckDB、dbt、Airflowを使ったローカル環境でのデータ基盤を構築
Minioでオブジェクトストレージを実現し、DuckDBにデータを取り込み
dbtでデータモデルを宣言的に定義し、SQLによるデータ加工を実施
Airflowを導入してデータパイプラインを自動化、スケジューリング・モニタリング機能を実現
ここら辺がサクッと実現できてしまうのに加えて数十GBレベルのデータであっても簡単に処理できてしまうらしいので、DWH製品を導入するほどでもないけどデータ分析基盤が欲しいなという時にかなり便利な構成なのかなと思いました
また、今回はやっていませんが
dbt testの追加
データ型やNULL制約など、データ品質を確保するためのテストを実装
dbt-osmosisによるメタデータ生成の自動化
データモデル、データソース、データ検証結果などのメタデータをドキュメント化
データガバナンスと理解促進を目的に活用
という要素を追加すると本格的なデータ基盤になりうるのでここら辺も時間ができたら紹介したいなと思っております