FireDucks性能評価

本記事はFireDucksユーザー記事シリーズの第5弾です.本記事はYoshiyuki Kofuji様に執筆して頂きました
はじめに
Pythonでデータ収集・加工処理に欠かせないpandasのAPI互換ソフトウェアであるFireDucksについて、
動作環境やデータ量を変化させたときの高速化性能を確認します。
検証は、データセット内の数値データをカテゴリ化する処理に対し、複数の実装について高速化性能を測定する形で行います。
1.DataFrameに新たな行を追加(数値→カテゴリ変換)
利用データセット
scikit-learnに含まれるカリフォルニア州の不動産価格に関するデータセット(california_hausing)を用います。
データ概要は以下の通りです。
データ数 : 20,640件
変数数 : 8個
データ項目概要
| Feature | Description |
| :--------: | :------------------------: |
| MedInc | median income in block |
| HouseAge | median house age in block |
| AveRooms | average number of rooms |
| AveBedrms | average number of bedrooms |
| Population | block population |
| AveOccup | average house occupancy |
| Latitude | house block latitude |
| Longitude | house block longitude |追加する行
HouseAge(数値)を10年刻みに分類する行を追加します。
データ基礎統計量
df_cfh['HouseAge'].describe()
count 20640.000000
mean 28.639486
std 12.585558
min 1.000000
25% 18.000000
50% 29.000000
75% 37.000000
max 52.000000
Name: HouseAge, dtype: float64最大値が52年なので、下記のように分類します。
| 期 間 | 分類 |
| :------: | :------: |
|~10年 | under10 |
|10~20年 | 10\_20 |
|20~30年 | 20\_30 |
|30~40年 | 30\_40 |
|40~50年 | 40\_50 |
|50年~ | over50 |1-1.実装方法1 -loc利用-
ソースコード
列スライスしつつ、Locで値を入力します。pandasの中では高速に処理してくれるので個人的にはこの実装することが多いです。
# 列スライス(loc利用)
def houseAge_Class_Loc(df):
_df = df.copy() # 差し当たりcopy
_df.loc[(_df['HouseAge'] < 10), 'HouseAgeClass'] = HAGE_UNDER10
_df.loc[(_df['HouseAge'] >= 10) & (_df['HouseAge'] < 20), 'HouseAgeClass'] = HAGE_10_20
_df.loc[(_df['HouseAge'] >= 20) & (_df['HouseAge'] < 30), 'HouseAgeClass'] = HAGE_20_30
_df.loc[(_df['HouseAge'] >= 30) & (_df['HouseAge'] < 40), 'HouseAgeClass'] = HAGE_30_40
_df.loc[(_df['HouseAge'] >= 40) & (_df['HouseAge'] < 50), 'HouseAgeClass'] = HAGE_40_50
_df.loc[(_df['HouseAge'] >= 50), 'HouseAgeClass'] = HAGE_OVER50
return _df1-2.実装方法2 ‐mask利用-
ソースコード
新たに追加する行に初期値を設定し、mask関数で値を上書きします。(mask処理は文字列型でも対応できますが
ここでは数値型で実装します。)
# mask利用
def houseAge_Class_mask(df):
_df = df.copy() # 差し当たりcopy
c1 = (_df["HouseAge"] < 10)
c2 = (_df["HouseAge"] >= 10) & (_df["HouseAge"] < 20)
c3 = (_df["HouseAge"] >= 20) & (_df["HouseAge"] < 30)
c4 = (_df["HouseAge"] >= 30) & (_df["HouseAge"] < 40)
c5 = (_df["HouseAge"] >= 40) & (_df["HouseAge"] < 50)
c6 = (_df["HouseAge"] >= 50)
_df['HouseAgeClass'] = np.nan
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c1,1000)
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c2,2000)
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c3,3000)
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c4,4000)
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c5,5000)
_df['HouseAgeClass'] = _df['HouseAgeClass'].mask(c6,6000)
return _df1-3.実装方法3 -map利用-
ソースコード
判定関数を定義しmapで各列に適応します。可毒性が高く判定関数の中身を変えるだけで分類方法が変更可能且つpandasの中では高速に処理してくれるので、データ加工処理としてメリットが多い実装です。
# map利用
def houseAge_Class_Map(df):
def houseAge_class(x):
if x < 10:
return HAGE_UNDER10
elif (10 <= x) and (x < 20):
return HAGE_10_20
elif (20 <= x) and (x < 30):
return HAGE_20_30
elif (30 <= x) and (x < 40):
return HAGE_30_40
elif (40 <= x) and (x < 50):
return HAGE_40_50
else:
return HAGE_OVER50
_df = df.copy()
_df['HousingAgeClass'] = _df['HouseAge'].map(houseAge_class)
return _df 2.性能検証結果‐データ量の影響-
データセットを水増し後、データサイズを100~10,000,000に振り分けて高速化性能を計測します。
動作環境
CPU :Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.60 GHz
メモリ :32GB
Linux :WSL
実装方法1 -loc利用-
pandas、FireDucksとも処理時間はデータ量に対して線形に増加する傾向があり、FireDucksのほうが 処理速度が遅い結果となりました。
これは、現状のFireDucksではLoc処理に対応しておらず、内部でpandasを呼び出して実行しているのが原因とのこと。 (fallbackと呼ぶそうです。)fallbackは順次解消されていくようなので今後に期待。※

※2024年2月14日(水)のリリースで対応頂いたようです。対応版での動作確認結果は以下です。
mask利用処理と同様にFireDucksのほうが高速化されることを確認しました。

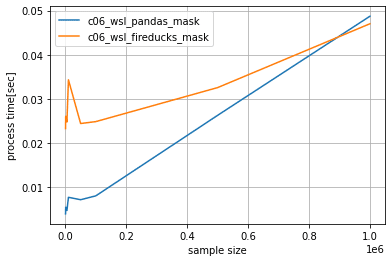
実装方法2 -mask利用-
pandas、FireDucksとも処理時間はデータ量に対して線形に増加する傾向があり、データ量が増加するほどFireDucksの高速化性能が際立つ
結果となりました。
※データ量が少ない時はpandasのほうが速いのは、データの処理時間が短すぎて並列化による高速化よりも、並列化する処理コストが上回るためです。
全体の処理が0.042秒を超える(データ量が90万件を超える)あたりからFireDucksのほうが速くなるようです。
データ量500~10,000,000

データ量500~1,000,000
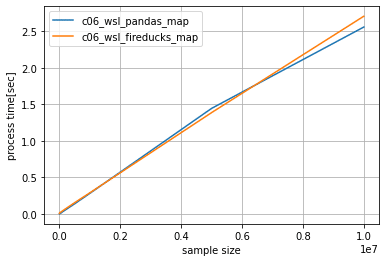
実装方法3 -map利用-
pandas、FireDucksとも処理時間はデータ量に対して線形に増加する傾向があり、若干ではありますがFireDucksを利用したほうが
処理速度が遅い結果となりました。(fallbackの影響のようです。)
3.性能検証結果‐動作環境の影響-
FireDucksでは並列化可能な処理をCPUのコアに割り当てて高速化を実現していることなので、手持ちの環境でCPUのコア数を変化させた場合の高速化性能について確認します。
また、FireDucks(現時点ではLinuxのみ対応)をWindows環境で利用するケースを考慮して、ネイティブLinuxとWSLの高速化性能についても比較します。
動作環境
1.ノートPC(WSL-ubuntu_22_04)
CPU : Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.60 GHz(6コア)
メモリ : 32GB
2.デスクトップPC(WSL -ubuntu_22_04)
CPU : Intel(R) Core(TM) i7-13700F CPU @ 2.10GHz 5.20 GHz(16コア)
メモリ :32GB
3.デスクトップPC(ubuntu22_04)
CPU : Intel(R) Core(TM) i7-13700F CPU @ 2.10GHz 5.20 GHz(16コア)
メモリ :32GB
評価対象
FireDucksで高速化が認められたmask処理について確認します。
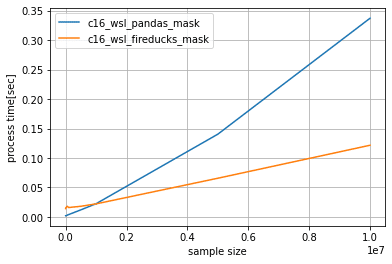
結果1. 動作環境別pandasとFireDucksの処理性能比較
評価環境全てにおいて、pandas、FireDucksともデータ量増加に伴い処理時間が線形的に増加し、データ量が多い程FireDucksの高速化性能が高くなる結果となりました。
また、サンプル数が10,000,000件の場合、コア数が大きいほうがpandasに対しての高速化性能が若干高い結果となりました。
コア数6 (WSL) : pandasより約2.6倍高速
pandas(0.59秒)/FireDucks(0.23秒)
コア数16 (WSL) : pandasより約2.8倍高速
pandas(0.34秒)/FireDucks(0.12秒)
※参考:ubuntu: pandas(0.29秒)/FireDucks(0.12秒)
コア数6 WSL

コア数16 WSL
コア数16 ubuntu

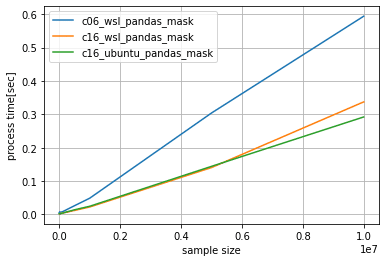
結果2. 動作環境の高速化性能への影響比較
WSLとubuntuの高速化性能はデータ数によらず一定でした。又、速度劣化もそこまで顕著ではないためWSLでも十分高速化
の恩恵が得られると思われます。
FireDucks

pandas
4.まとめ
pandasとAPI互換の高速化ソフトウェアFireDucksの高速化性能を検証しました。検証は、機械学習の前処理でよく用いられる数値からカテゴリへの変換処理を対象とし、データ数や環境を変えて行いました。
検証の結果、分かったことを下記にまとめます。
CPUコア数6と16の環境で検証した結果、コア数16のほうが高速化性能が若干高い結果となりました。又データ数増加に伴い高速化性能が高くなることも確認しました。
ネイティブLinuxとWSLの環境で検証した結果、ネイティブLinuxのほうが若干高速化性能が高い結果となりました。ただ、処理速度差はデータ量によらず0.002~0.009秒に収まっているようなのでWSLでも十分に高速化の恩恵が受けれることを確認しました。
pandasの一部メソッド(Loc等)についてはFireDucks内でpandasライブラリを実行している為高速化されないケース(fallback)がある。
FireDucksはデータ量が多い程高速化性能が高くなる点において、データ規模が大きくなるほど価値が上がるソフトウェアと言えそうです。(機械学習では大規模データの加工処理でカット&トライを繰り返す為絶大な効果が期待できます。)
又、今回は残念ながら非対応だったメソッドについても順次対応されていくとのことなので(この検証中にもLocに対応いただきました。)、ますます使い勝手が良くなっていく点からも大いに期待が持てると思います。
この記事が気に入ったらサポートをしてみませんか?