pandasを用いた大規模データの前処理をfireducksに置き換えてみる

本記事はFireDucksユーザー記事シリーズの第10弾です.本記事はYoshiyuki Kofuji様に執筆して頂きました
はじめに
pandasを用いた大規模データの前処理を、高速化性能が高いAPI互換ソフトウェアであるFireDucksに置き換えて高速化性能を検証します。
検証は、時系列データセットの数値データの移動平均を算出する処理について、複数の実装を行い、各々の実装について高速化性能を測定する形で行います。
1.移動平均算出処理
利用データセット
時系列データとして、気象庁でダウンロード可能な気象データ(平均気温、降水量)を用います。 データ概要は以下の通りです。
データ数 : 32,898件 (期間:2019年3月1日~2024年3月1日,サンプリング間隔:1日毎,都市数:18)
変数数 : 4個
データ項目概要

データサンプル
同一観測年月日に18都市のデータが並ぶので、移動平均を算出するには都市ごとのデータを抽出する必要があります。

移動平均算出イメージ
処理としては下記のように、都市毎の時系列データを抽出後平均気温、降水量の合計の値の移動平均を算出します。

1-1.実装方法1 -where利用-
ソースコード
都市毎のデータを抽出して移動平均を算出後、元のDataFrameに移動平均列を追加してwhereを用いて該当都市のデータのみ値を上書きします。
※過去にこの前処理を実装した際には、pandasの実装経験が浅かった為この方式で実装していました。
# whereを利用した都市毎の移動平均算出関数(3日移動平均、7日移動平均を算出)
# df_data:移動平均を追加するDataFrame
# rel_list:移動平均算出対象列(rel_list=['平均気温(℃)','降水量の合計(mm)'])
def moving_average2(df_data,rel_list):
city_list = df_data['都市名'].unique()
cnt_len = len(city_list)
i = 0
add_col_list_1 = []
add_col_list_2 = []
for c in rel_list:
add_col_list_1.append(c+'_rel3')
add_col_list_2.append(c+'_rel7')
df_data[add_col_list_1]=0
df_data[add_col_list_2]=0
for city in city_list:
i+=1
df_tmp = df_data[df_data['都市名']==city]
df_tmp[add_col_list_1] = df_tmp[rel_list].rolling(3).mean()
df_tmp[add_col_list_2] = df_tmp[rel_list].rolling(7).mean()
df_data[add_col_list_1] = df_data[add_col_list_1].where(df_data['都市名']!=city,df_tmp[add_col_list_1])
df_data[add_col_list_2] = df_data[add_col_list_2].where(df_data['都市名']!=city,df_tmp[add_col_list_2])
return df_data
1-2.実装方法2 -sort利用-
ソースコード
都市毎のデータを抽出して移動平均を算出後、都市毎に抽出したデータを結合して最後index値でソートします。今回の性能測定に際して改めてpandas処理を見直した時にこの実装を思いつきました。
# sort(index値)を利用した都市毎の移動平均算出関数(3日移動平均、7日移動平均を算出)
# df_data:移動平均を追加するDataFrame
# rel_list:移動平均算出対象列(rel_list=['平均気温(℃)','降水量の合計(mm)'])
def moving_average3(df_data,rel_list):
city_list = df_data['都市名'].unique()
cnt_len = len(city_list)
i = 0
add_col_list_1 = []
add_col_list_2 = []
for c in rel_list:
add_col_list_1.append(c+'_rel3')
add_col_list_2.append(c+'_rel7')
df_result = pd.DataFrame()
for city in city_list:
i+=1
df_tmp = df_data[df_data['都市名']==city]
df_tmp[add_col_list_1] = df_tmp[rel_list].rolling(3).mean()
df_tmp[add_col_list_2] = df_tmp[rel_list].rolling(7).mean()
df_result = pd.concat([df_result,df_tmp])
return df_result.sort_index()
2.性能検証結果―データ量の影響-
データセットを水増し(都市数を水増し)後、データサイズ(都市数)を20~180に20都市間隔で振り分けて高速化性能を計測します。
動作環境
CPU: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.60 GHz
メモリ: 32GB
Linux: WSL
実装方法1 -where利用-
pandas、FireDucksとも処理時間はデータ量に対して線形に増加する傾向があり、FireDucksのほうが 処理速度が遅い結果となりました。(処理速度差はデータ量によらずほぼ一定)
これは、現状のFireDucksではwhere処理に対応しておらず、内部でpandasを呼び出して実行している(fallback)のが原因と思われます。

実装方法2 -sort利用-
pandas、FireDucksとも処理時間はデータ量に対して線形に増加する傾向があり、データ量が増加するほどFireDucksの高速化性能が際立つ結果
となりました。
移動平均は都市数分算出するので、都市数が増加すればするほど処理速度差が累積されてくるように思います。

※データ量(都市数)が少ない時はpandasのほうが速いのは、データの処理時間が短すぎて並列化による高速化よりも、並列化する処理コストが上回るためです。
全体の処理が0.027秒を超える(都市数が35(約6万4千件)を超える)あたりからFireDucksのほうが速くなるようです。

3.性能検証結果‐動作環境の影響-
FireDucksでは並列化可能な処理をCPUのコアに割り当てて高速化を実現していることなので、手持ちの環境でCPUのコア数を変化させた場合の高速化性能について確認します。
また、FireDucks(現時点ではLinuxのみ対応)をWindows環境で利用するケースを考慮して、ネイティブLinuxとWSLの高速化性能についても比較します。
動作環境
1.ノートPC(WSL-ubuntu_22_04)
CPU : Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz 2.60 GHz(6コア)
メモリ : 32GB
2.デスクトップPC(WSL -ubuntu_22_04)
CPU : Intel(R) Core(TM) i7-13700F CPU @ 2.10GHz 5.20 GHz(16コア)
メモリ :32GB
3.デスクトップPC(ubuntu22_04)
CPU : Intel(R) Core(TM) i7-13700F CPU @ 2.10GHz 5.20 GHz(16コア)
メモリ :32GB
評価対象
FireDucksで高速化が認められたsort処理について確認します。
結果1. 動作環境別pandasとFireDucksの処理性能比較
評価環境全てにおいて、pandas、FireDucksともデータ量増加に伴い処理時間が線形的に増加し、データ量が多い程FireDucksの高速化性能が高くなる結果となりました。
また、都市数が180の場合、コア数が大きいほうがpandasに対しての高速化性能が高い結果となりました。
コア数6 (WSL) : pandasより約2.00倍高速
pandas(3.74秒)/FireDucks(1.88秒)
コア数16 (WSL) : pandasより約2.17倍高速
pandas(2.02秒)/FireDucks(0.93秒)
コア数16(ubuntu): pandasより約2.88倍高速
※pandas(1.87秒)/FireDucks(0.65秒)
コア数6 WSL
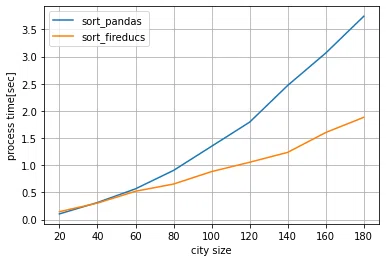
コア数16 WSL

コア数16 ubuntu

結果2. 動作環境の高速化性能への影響比較
WSLとubuntuの高速化性能は都市数(ループ回数)が増えると若干速度性能差が開く結果となりました。ただ、速度劣化はそこまで顕著ではないためWSLでも十分高速化 の恩恵が得られると思われます。
FireDucks

pandas

4.まとめ
時系列データ(天候データ)の移動平均算出処理について、pandasとAPI互換の高速化ソフトウェアFireDucksの高速化性能を検証しました。検証は、データ量(都市数)や実装方法を変更して行いました。 検証の結果、分かったことを下記にまとめます。
都市毎にデータを抽出後(列スライス)に移動平均を算出したDataFrameを縦結合し、インデックスでソートするというような複雑な処理においても、FireDucksの高速化性能が有効であることを確認しました。
都市数回ループ処理する場合では、都市数(ループ回数)が増えるほどFireDucksの高速化性能が際立つことも確認しました。pandasを含むpythonではループさせないのが基本ですが、今回のようにループせざる得ない状況において高速化性能が際立つのは非常に心強いと感じました。
CPUのコア数の影響についても確認しました。結果としては都市数(ループ回数)が増えるほど、高速化性能さが顕著になりました。
pandasの一部メソッド(where等)についてはFireDucks内でpandasライブラリを実行している為高速化されないケース(fallback)があります。ただ、pandasとの処理速度差は一定なのでpandasの利便性をそこまで損なうことは無いと感じました。
FireDucksはループ処理を伴う前処理においても、ループ回数が多い程高速化性能が高くなる点において価値が高いソフトウェアと言えそうです。(機械学習では大規模データの加工処理でカット&トライを繰り返す為絶大な効果が期待できます。)
又、今回は残念ながら非対応だったwhere処理等についてもpandasからの速度性能の劣化は微小かつデータ数増加(ループ回数増加)に対して一定なので、実装方法による速度低下リスクは低く実装の置き換えができると感じました。