Pandasを高速化方法比較

本記事はFireDucksユーザー記事シリーズの第8弾です.本記事はアリス様に執筆して頂きました.
Pandasは非常に強力なデータ処理のツールであり、いくつかの便利なデータ操作機能を提供します。 ただし、Pandasはパフォーマンスのため特化のものではありません。中小規模のデータセットにはokですが、大規模なデータセットを扱う場合にはパフォーマンスの問題が発生する可能性があります。したがって、Pandasを高速化するための方法は数多く出ました。
今回の記事では、Pandasの高速化方法 (ライブラリ) をいくつか準備し、データの読み込み時間、メソッド実行時間、RAMメモリ使用状況、使いやすさの観点からベンチマークテストを設計してそれらを比較します。
ベンチマーク対象を明確にする
Pandas を高速化する人気のあるライブラリは以下のものです:
Fireducks
Polars
Dask
Modin
PySpark
PySparkの導入は非常に手間がかかり、今回の場合には適していません。 また、Modinには2つの高速モードがあります。
上記の情報を総合して、以下のベンチマーク対象を選択します。
fireducks.pandas (FireDucks)
polars (Polars)
dask.dataframe (Dask)
modin.pandas (ModinのDaskモード)
modin.pandas (ModinのRayモード)
ベンチマークケースになる Pandas のメソッドは以下の通りです:
read_csv
dropna
group_transform
stack
melt
filter_bracket
filter_query
replace
sort
データセットの準備
今回のデータセットはダミーデータで作成します。
出来る限り多くの数値を持たせるために、ゲーム内システムのアイテム (道具や武器など) データを模造します。
randomを使ってメインに乱数に基づいて生成します:
# 後でPandasのmeltやstackなどに利用可能のため、アイテムのランクも生成する
def _get_random_rank():
_RANKS = ['SSS', 'S', 'A+', 'A', 'B', 'C', 'D']
return _RANKS[random.randint(0, len(_RANKS) - 1)]
f.write("object_id,object_type,obj_rank,loc_x,loc_y,rareness_rank,prop_hp,prop_mp,prop_attack,prop_defense,prop_magic,flag_1,flag_2,flag_3,flag_4,flag_5\n")
# アイテムID
object_id = str(uuid.uuid4())
# アイテム種類
object_type = str(random.randint(0,6))
# 座標
loc_x = str(random.randint(1,1e6) / 100)
loc_y = str(random.randint(1,1e6) / 100)
# フラグ
flag_1 = str(random.randint(0, 1))
flag_2 = str(random.randint(0, 1))
flag_3 = str(random.randint(0, 1))
flag_4 = str(random.randint(0, 1))
flag_5 = str(random.randint(0, 1))
if object_type in ['3', '6']:
flag_5 = '1'
# ランク
obj_rank = _get_random_rank()
rareness_rank = _get_random_rank()
# 属性
prop_hp = str(random.randint(0, 100) * 100)
prop_mp = str(random.randint(10, 1000000))
prop_attack = ""
prop_defense = ""
prop_magic = ""
if flag_1 == '1':
prop_attack = str(random.randint(0, 100) * 17)
prop_defense = str(random.randint(0, 100) * 19)
prop_magic = str(random.randint(0, 100) * 27)
f.write(f"{object_id},{object_type},{obj_rank},{loc_x},{loc_y},{rareness_rank},{prop_hp},{prop_mp},{prop_attack},{prop_defense},{prop_magic},{flag_1},{flag_2},{flag_3},{flag_4},{flag_5}\n")
さまざまなデータ量のケースをテスト実験に反映させるため、調整変数scale_factorを追加して、データ量をコントロールできるようにする:
def generate_gameobj_csv_sample(target_file, scale_factor = 1, with_header = True):
with open(target_file, "a") as f:
if with_header:
f.write("object_id,object_type,obj_rank,loc_x,loc_y,rareness_rank,prop_hp,prop_mp,prop_attack,prop_defense,prop_magic,flag_1,flag_2,flag_3,flag_4,flag_5\n")
n = int(scale_factor * 12500000) # <--- 調整
for i in range(n):
object_id = str(uuid.uuid4())
# ...
scale_factor = 1は大体1GB相当、12500000に調整しました。
上記をまとめると、gen_dataset.py になります
次はバッチ make_dataset.sh で、今回テスト用のデータセット5段階を生成します。
t1.csv (100 MB, sf=0.1)
t2.csv (500 MB, sf=0.5)
t3.csv (1 GB, sf=1)
t4.csv (2 GB, sf=2)
t5.csv (4 GB, sf=4)
python3 gen_dataset.py t1.csv 0.1
python3 gen_dataset.py t2.csv 0.5
python3 gen_dataset.py t3.csv 1
python3 gen_dataset.py t4.csv 2
python3 gen_dataset.py t5.csv 4
上記を実行すると次のように出力されます:

生成したデータセットの様子はこちらです:
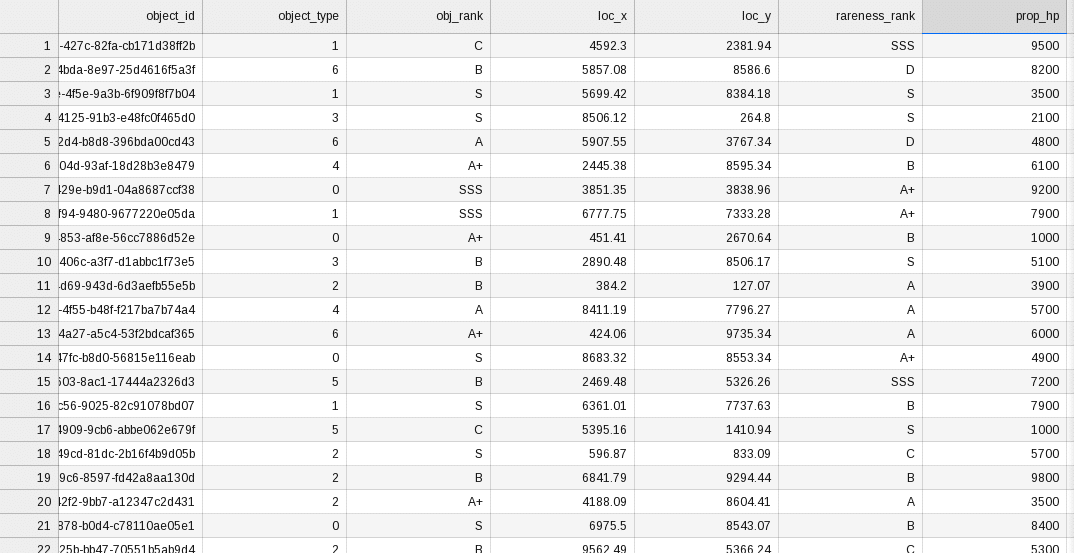
ベンチマークケースの準備
def invoke_group_transform(df):
return df.groupby("object_type")["prop_attack"].transform(lambda att: att.mean() / att.std())
def invoke_stack(df):
return df[['obj_rank', 'rareness_rank']].stack()
def invoke_melt(df):
return df[['object_id', 'object_type', 'loc_x', 'loc_y', 'obj_rank', 'rareness_rank']].melt(id_vars=['object_id', 'object_type', 'loc_x', 'loc_y'], var_name='rank_type', value_name='rank_value')
def invoke_filter_bracket(df):
return df[(df["loc_x"] > 1000) & (df["loc_x"] <= 2000) & (df["loc_y"] > 2000) & (df["loc_y"] <= 3000)]
def invoke_filter_query(df):
return df.query("loc_x > 1000 and loc_x <= 2000 and loc_y > 2000 and loc_y <= 3000")
def invoke_replace(df):
return df["obj_rank"].str.replace("SSS", "S+")
def invoke_sort(df):
return df.sort_values("prop_hp", ascending=False)
自動化ベンチマークのため、ここに少々トリックを:
def test_df(item, df):
if item not in TEST_ITEMS:
raise Exception("unknown test item: " + item)
_func = globals()["invoke_" + item]
return _func(df)
TEST_ITEMS = ['group_transform', 'stack', 'melt', 'filter_bracket', 'filter_query', 'replace', 'sort']
for test_item in TEST_ITEMS:
_t1 = time.time()
test_df(test_item, df)
_t2 = time.time()
print(_t2 - _t1)
測定した時間をオブジェクト bench_info に保存します。
例えば read_csv は:
# read_csv
_t1 = time.time()
_df = p.read_csv(target_dataset)
_t2 = time.time()
bench_info["time"] = {}
bench_info["time"]["read_csv"] = _t2 - _t1
最後にjsonを使ってオブジェクトをベンチマークレポートに保存します:
with open(output_json, 'w') as f:
json.dump(ret, f, ensure_ascii=False, indent=4)
ベンチマークレポートの様子は:
{
"id": "51793b6c-cd09-47c7-8057-4bbabd770cb1",
"lib_name": "pandas (2.2.0)", // ライブラリーとバージョン
"bench_time": "2024-02-20 18:49:46",
"dataset_name": "t1.csv",
"dataset_path": "/root/bench/t1.csv",
"_dataframe_class": "<class 'pandas.core.frame.DataFrame'>",
"time": { // 所要時間 (秒)
"read_csv": 2.019407033920288,
"dropna": 0.20914840698242188,
"group_transform": 0.05803394317626953,
"stack": 0.06781387329101562,
"melt": 0.2635030746459961,
"filter_bracket": 0.0037779808044433594,
"filter_query": 0.008503437042236328,
"replace": 0.12197589874267578,
"sort": 0.09974837303161621
},
"dataset_size": 111722152, // データセットサイズ (Bytes)
"ram_fin": 403559929, // テスト最後時点のRAMメモリ消費量 (Bytes)
"ram_peak": 671211248 // テスト中のRAMメモリ最大消費量 (Bytes)
}
上記をまとめると、bench.py になります。
ベンチマーク結果比較
ユーザビリティ (Pandasとの互換性)
ユーザビリティは Pandasユーザー視点 からの使いやすさです。 つまり、新しいライブラリに適応するために学ぶ必要はなく、Pandasを知っていればそのまま使いこなすことができます。
比較のためここには 4 つの基準を作ります:
ユーザビリティ(Pandasとの互換性) 高いライブラリでは、元々のPandasのメソッドを変更する必要はありませんです。その場合は ✅ 印を付けます。
同じ処理を可能ですが、メソッドを変更する必要がありますの場合は ✅(J) 印を付けます。
同じ処理を可能ですが、ライブラリからいくつかの Warning 出る場合は ✅(?) 印を付けます。
同じ処理不可能、互換性がありませんの時は ❌ で。
そして、今回の結果については:

✅ : 互換性は完璧です
✅(J) : 互換性はありますが、メソッドを変更する必要があります
✅(?) : 互換性はありますが、いくつかの警告があります
❌ : 互換性がありません
FireDucksの方は完璧の互換性ですね!
PolarsはDataFrameの使い方に大きな違いがありますね。Pandasのユーザーにとっては非常に使いにくいと思います。
一方、DaskとModin(2つのモード)はやや扱いやすいですが、Warningが表示されることで不安になることがあり、また一部のメソッドを使用しないため、仕事中は厄介です。
ユーザビリティの比較は FireDucks の勝利です。
汎用性
x86_64 以外のプラットフォームで実行してみました:
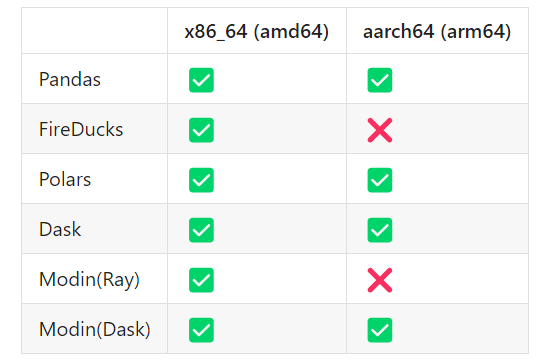
FireDucksとModinのRayモードはarm64の対応はないだけで、他のライブラリは問題なさそうね。FireDucksはまだBeta段階にあり、近い将来サポートされるでしょう (FireDucksの開発はとても活発で、毎週新しいバージョンがリリースされます)。
パフォーマンス比較
OOM (Out-Of-Memory) 条件比較
今回のテストPCは16GBのRAMメモリを搭載していますが、5段階のデータセットをすべてクリアできませんでした。
同じ残りの物理RAMメモリ容量の条件 (swapなし) で比較してみますと:
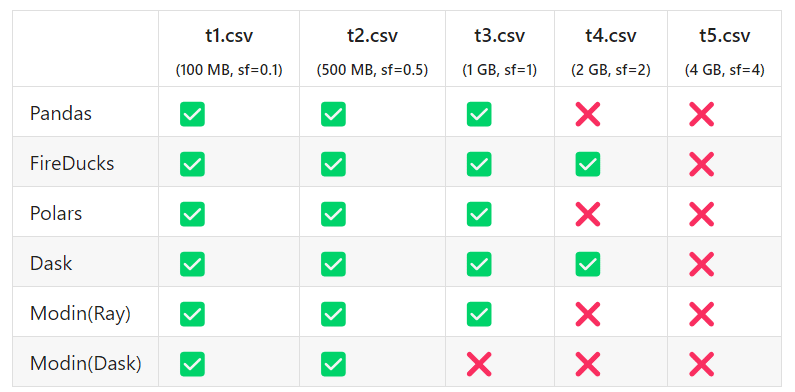
✅ : Pass
❌ : メモリ不足 (OOM 発生)。
FireDucksとDaskのみでsf=2に突入できました。
FireDucksとDaskは他のライブラリと比べて、同じ条件下でより大きなデータセットを処理できます、データ分析作業にとってこれは非常に重要ですので、凄いです。
各種メソッドの高速化率や所要時間の比較
メソッド dropna

メソッド filter_bracket

メソッド filter_query

※ Polars にはこちらのPandasメソッドと同様のメソッドがないため、評価できませんでした。
メソッド group_transform

※ Polars にはこちらのPandasメソッドと同様のメソッドがないため、評価できませんでした。
メソッド melt

メソッド read_csv

メソッド replace

メソッド sort
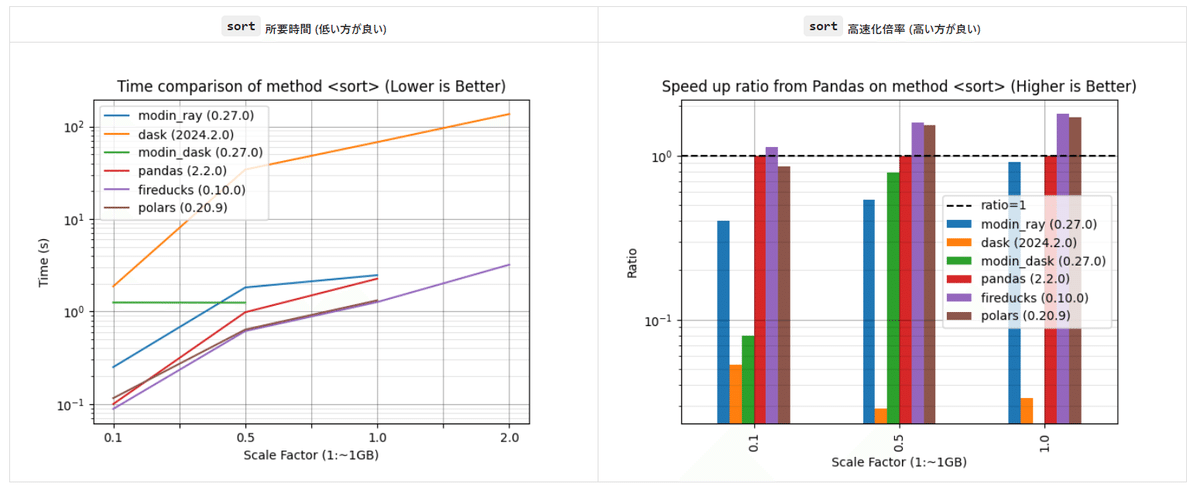
メソッド stack

※ PolarsとDask にはこちらのPandasメソッドと同様のメソッドがないため、評価できませんでした。
ほとんどのケースでは、FireDucksが優位です。 驚くべきことに、FireDucks が大勝利です!
結論
使いやすさや性能パフォーマンスはともかく、どの面から見てもFireDucksが明らかにPandas高速化ライブラリの中の勝者です。
普段使いにどれを選べばよいか迷った場合、個人的には最も軽量で互換性が高く、かつ一番高速な FireDucks をお勧めします。
今回ベンチマークに使用するのハードウェアスペックは:
CPU: AMD Ryzen 7 3700X 8-Core Processor (8コア16スレッド)
RAM: 16GB (No SWAP)
OS: Ubuntu 22.04 (x86_64)
各個対象ライブラリのバージョンは:
Pandas (2.2.0)
Fireducks (0.10.0)
Polars (0.20.9)
Dask (2024.2.0)
Modin (0.27.0)
※ 記事内で使用されているソースコードはここのGithub Repo dataframes_bench からダウンロードできます。 ※ ベンチマークは多くの要因の影響を受けるため、間違いがある可能性がありますので、ご注意ください。また、結論の利用は自己責任や判断でご参考までお願いします。
この記事が気に入ったらサポートをしてみませんか?