
[趣味研究][R18]男の娘とショタの扱われ方#1:スクレイピング

注意
スクレイピングの対象としてアダルトサイトを選んでいることから、本記事には過激な性的表現が含まれているので、未成年の方や、そうした表現が苦手な方は閲覧を控えてください。ご了承いただける方のみスクロールして本記事をお読みください。
*なお本来であれば自主的にR18指定をかけたいのですが、noteにはその機能がなく、公式からR18と指定されるのを待つしかないようです。
背景
みなさんは「ショタ」や「男の娘」という言葉をご存知でしょうか?実はこれらの言葉を定義すること自体困難なのですが、両者を巡る歴史や学術的な議論は今後に回すとして、ここではこのnoteで何を調査しているのかイメージしやすくするために、具体例とともに非常におおざっぱな感覚で両者を説明したいと思います。
(*このような説明の仕方は、非常に暴力的かつ権力が介在する気がするので、あくまでここでの説明は私のイメージという風にとらえてください)
・ショタ:おおざっぱに言えば、少年といった意味です。「ショタ」という言葉より先に「ショタコン」という言葉が存在し、その「ショタコン」という言葉は、マンガ・アニメの『鉄人28号』の主人公・金田正太郎に代表されるような少年のことが好きな人を指す言葉として生まれました。

https://king-cr.jp/special/tetsujin/chara_mecha.html
文脈的には、「ロリコン」に対置される形で作られた言葉です。当初は、「半ズボンをはいた少年」ぐらいのイメージだったらしいが、現在はより広範な対象を指していると思われ、場合によっては大人のキャラクターに対しても用いられることもあります。私のイメージする典型的な例いくつか載せておきます。

https://x.com/inazuma_project/status/1470955522576760842?s=20

出典:https://ensemble-stars.jp/units/rabits/
・男の娘:おおむね「女の子に見える少年」といったぐらいにとらえておけばいいと思います。「女装をしている」や「ジェンダー・アイデンティティは男性である」といった条件を加えた定義で使っている場合もある気がしますが、近年では女装*していない場合もあり、またノンバイナリーも含め男の娘のジェンダーアイデンティティも多様(画像1枚目のブリジットのジェンダーアイデンティティは女性)になってきている気がします。近年、男の娘はポピュラーになってきていて、FANZAの同人誌を対象とした統計では、男の娘は全ジャンルのなかで3位になっています。(2018年4位→2023年3位)
おそらくR18なのでリンクを踏む際は気を付けて
https://t.co/oYXk1m3aR5
*そもそも何をもって「女装」とするかや女装という表現がジェンダー学の中でどう扱われているかは存じ上げないです。昔から疑問。

https://www.guiltygear.com/ggst/jp/character/bgt/

https://hackadoll-anime.com/character/
違い:感覚的な説明しかできませんが、ショタはあくまでそのキャラクターの男性的*な部分が魅力となっている一方で、男の娘は女性的*な部分が魅力となっているのかなと思います。そのような違いからか、前者は性行為において交渉相手が女性の場合もそれなりにありますが、後者は基本的に相手は男性がほとんどです。ただ実際は、この後の分析でもわかるように、かなりオーバーラップしています。今回の分析はこれを定量的にみることにあります。
*ここでの「女(男)性的な」の感覚は、その読者(作者)がもつ「ジェンダーバイアス」に依存すると思います(私が女らしさみたいな規範をもっているというわけではありません)。そもそもショタの語源に「半ズボンをはいているような」という説明から、半ズボン=少年っぽさ という感覚が潜在的にあることが窺えます。ショタにはいわゆる「少年っぽさ(例:日焼け、活発、反抗期、無邪気さなど)」が期待され、男の娘には「(少)女っぽさ(例:繊細、大人しさ、長髪、柔らかさなど)」が期待されていると思われ、ここに読者(作者)のジェンダーバイアスが反映されているところだと思います。
データ
DLsite(https://www.dlsite.com/touch.html)という同人作品販売サイトを対象としました。なぜこのサイトを選んだかというと、Pixivなどで無料公開されている作品を購入しようとリンクを踏むと大体このサイトにつながるイメージがあったからです。なので、特に妥当性はありません(そのうちFANZAも対象にしようと思います)
分析の際に特に補正は加えていませんが、一応、利用者のデモグラフィーがあったので載せておきます。

出典:https://info.eisys.co.jp/dlsite/9d4a7f9ca0ea2850
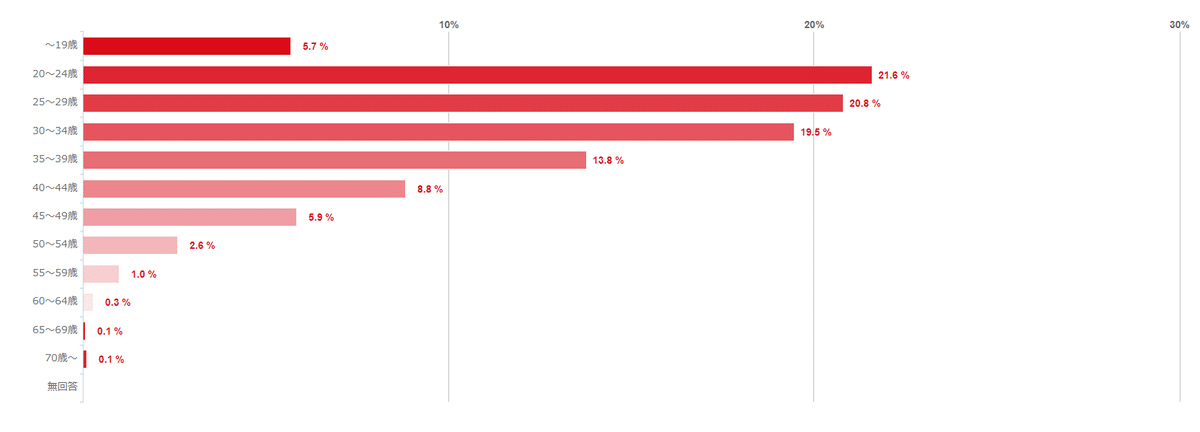
出典:同上
今回は以下のジャンルの作品データを集めました。()内は作品数
・全年齢対象+ショタ(552)
・R18対象+ショタ(11703)
・全年齢対象+男の娘(219)
・R18対象+男の娘(6434)
この時点で少し面白いですね。全年齢R18を問わず、ショタの作品数
が男の娘にほぼダブルスコアをつけています。
収拾したデータは以下のものになっています。
・タイトル
・URL
・値段
・紹介文
・カテゴリ(漫画か動画かASMRかなど)
・ジャンル(NTRや催眠など)
・発売日
・販売数
本当は評価★の数も入手したかったのですがうまくいきませんでした。
メソッド
見る人が見れば素人感満載だと思いますが、一応、全年齢_ショタを集めたときのサンプルコードも載せておきます。
いくつか大変だったところと注意すべきところを書きます
①time.sleep(5)を忘れない:DLsiteさんはスクレイピングを禁止していませんが、過度にサーバーに負担をかける行為を禁止しています。これを忘れるといわゆるDdos攻撃になって訴えられても仕方ありません。5秒でなくてもいい気がしますし、今回はそこまでリクエストする機会も多くないですが絶対に入れましょう
② soup_object_maker(url):これは自作関数としてもっとくと便利です
③ 次のページのurlをどう入手するか:いろいろ小難しいことを考えていましたが、よく考えたらurlの文字列にページを指定する箇所があったので、そこを繰り返し処理で変えてまとめて入手しました。ここが一番苦労した。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
import json
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
def soup_object_maker(url):
# URLからHTML documentを取得
headers = dict([('User-agent', '自分のPCのものをいれてください')])
res = requests.get(url, headers=headers)
HTML_document = res.text
if res.status_code != 200:
print(f"Error: {res.status_code}")
return None
# documentをBeautifulSoup()コンストラクタにぶち込んで 'soup'オブジェクトにする
# 第2引数の"html.parser"は構文解析の指定
soup = BeautifulSoup(HTML_document, "html.parser")
return soup
def extract_numbers(text):
# 数字を抜き出す正規表現パターン
pattern = r'\d+'
# 正規表現パターンにマッチする部分を抜き出す
numbers = re.findall(pattern, text)
# 抜き出した数字をつなげる
concatenated_numbers = ''.join(numbers)
return concatenated_numbers
def inf_scraper(url):
titles = []
urls = []
prices = []
exp_txts = []
categories = []
tags = []
dates = []
nums = []
count = 1
soup = soup_object_maker(url)
table = soup.find("table", {"class" : "work_1col_table n_worklist"})
works = table.find_all("tr") #個々の作品情報がリストで入っている
for work in works:
base_inf0 = work.find("td",{"class":"work_1col_thumb"} )
base_inf = work.find("dl",{"class":"work_1col"} )
base_inf2 = work.find("td",{"class":"work_1col_right"} )
title_inf = base_inf.find("dt",{"class": "work_name"}).find("a")
#タイトル
title = title_inf["title"]
titles.append(title)
#url
work_url = title_inf["href"]
urls.append(work_url)
#値段
price = base_inf.find('span',{"class":"work_price"}).get_text()
prices.append(price)
#紹介文
exp_txt = base_inf.find('dd',{"class":"work_text"}).get_text()
exp_txts.append(exp_txt)
#種類
category = base_inf0.find("div", {"class":"work_thumb"}).find_all("div")
if 1 < len(category):
categories.append(category[1].get_text())
else:
categories.append(category[0].get_text())
#ジャンル_タグ
tag_list = base_inf.find("dd", {"class":"search_tag"})
if tag_list:
tag = [tag.get_text() for tag in tag_list.find_all("a")]
else:
tag = [float("nan")]
tags.append(tag)
#発売日
date = base_inf2.find("li",{"class":"sales_date"}).get_text()
dates.append(extract_numbers(date))
#販売数
pre_num = base_inf2.find("li",{"class":"work_dl clear"})
if pre_num:
num = extract_numbers(pre_num.get_text())
else:
num = float("nan")
nums.append(num)
print(count)
count += 1
df = pd.DataFrame({
"title" : titles,
"url" : urls,
"price" : prices,
"exp_txt" : exp_txts,
"categorie" : categories,
"tag" : tags,
"date" : dates,
"nums" : nums
})
return df
#全年齢のショタのページのurlを入手
rankurls = []
for page in range(1,4):
url = f"https://www.dlsite.com/home/fsr/=/language/jp/age_category%5B0%5D/general/work_category%5B0%5D/doujin/work_category%5B1%5D/pc/work_category%5B2%5D/app/order%5B0%5D/trend/genre%5B0%5D/303/genre_name%5B0%5D/%E7%94%B7%E3%81%AE%E5%A8%98/options_and_or/and/options%5B0%5D/JPN/options%5B1%5D/NM/options_name%5B0%5D/%E6%97%A5%E6%9C%AC%E8%AA%9E%E4%BD%9C%E5%93%81/options_name%5B1%5D/%E8%A8%80%E8%AA%9E%E4%B8%8D%E5%95%8F%E4%BD%9C%E5%93%81/per_page/100/page/{page}/show_type/1"
rankurls.append(url)
count = 100
for rankurl in rankurls:
time.sleep(5)
df = inf_scraper(rankurl)
df.to_json(f"fem_boy_{count}.json", orient='records', lines=True)
print(count)
count+=100
こうして得られた表のスクショを載せておきます。まだナイーブにスクレイピングしただけなので少しクリーニングが必要ですね。

結果
次にショタ・男の娘、それぞれの作品にどのようなタグがつけられているのかを見ます。そうすることで、どのように彼らが扱われているのか(まなざされている?)、ショタと男の娘の差は何なのかが見えてくると思います。
冒頭にも述べましたが、ここからは性的な表現が多く含まれているので苦手な方はスクロールしないようお願いします。(まず、全年齢対象の結果を2枚貼ったあと、R18のものが2枚来ます)




議論
まず、男の娘に関しては全年齢・R18問わず、女装タグが一位に来ています。これは、先ほど男の娘の定義から「女装している」という条件を外したものの、大部分の男の娘は女装しているということをしめしていると思います。また男の娘とショタが同時にタグ付けされていることから、女装+ショタ=男の娘になっている場合もかなりあると思います。ここは今後、共起などを調べたいと思います。
一方、ショタに関しては全年齢・R18で違いがあり、R18では基本的に女性との関係(巨乳・おねショタ・お姉さん・おっぱいなど)が多いが、全年齢の方は上位に「ボーイズラブ」が来ていて下位に「お姉さん」が来ている。
また男の娘とショタのR18を比較すると、男の娘は、その上位のタグ(アナル,ゲイ/男同士,男性受け)を見ると基本的に男性と性行為をしていておそらく「受け」に回っていることが多いと推測されます。一方、ショタの上位のタグは(巨乳・おねショタ・お姉さん・おっぱい・逆レイプ・男性受け)と基本的に女性と性行為をしていると思われ、逆レイプに近い形でしょうが、一応「攻め」の役割であると思います。逆にゲイ・男同士のタグはそこまでショタについていませんね。また、男の娘にのみ「メス堕ち」のタグがついていることは意外でした。男の娘はすでに女性的な要素がある分、どちらかというとショタのほうにタグ付けが多いと思っていましたが、このことは、先ほど定義の際に外した「ジェンダーアイデンティティは男性である」という条件に合致する男の娘が多いからこそのタグなのかと思いました。
解釈が難しかったところは、「中出し」のタグが、されているのか、しているのか区別がつかないところです。ここらへんは共起を今後見ていきます。
今後
第2回↓
次は、タグだけでは見えない情報を、紹介文からゲットしてみようと思います。具体的には、頻出語や共起語、LDAなどを試そうと思っています。LLMについては無知なので何か良い分析のアイデアがあれば教えてもらえると嬉しいです。また、今後は発売日や値段、販売数などもうまく変数として使っていけたらいいなと思います。
あと、何かジェンダー研究の観点から指摘があると嬉しいです。(そのうち、以下のジェンダー系の文献も読んでまとめる予定です)
なんでそもそもこの記事を書くに至ったかは、気が向いたら書きます。