
Aidemy AIアプリ作成講座受講の振り返り

はじめに
はじめまして。
この度、AidemyのAIアプリ作成講座を受講してみましたので、これから始める&受講しようか迷っている方々の参考になればと思い、本記事を作成します。
私の前職は官公庁系の事務職(勤続7年)で、プログラミングの経験はありませんでしたが、退職を期に、手に職をつけたい。自分ひとりでもお金を稼げるスキルを身につけたいという思いから受講を決めました。
本記事の概要
1.受講したコースおよびカリキュラムについて
2.制作したアプリ
・自作アプリ
・制作環境
・モデル作成のコード
・画像認識→結果表示のコード
3.今後の課題と活用について
4.さいごに
1.受講したコースおよびカリキュラムについて
受講したコース
受講したコースは「AIアプリ開発講座」で、受講期間は6か月でした。
昨年末に退職後、主夫として家のことをやりながら無理なく勉強を進めるためにこの期間としました。
しかしながら、後半になり急な引っ越しやネット環境がない期間があったことにより、自作アプリの作成に充分な時間を確保することができなかったことが反省点です。
したがってアプリの作成とブログ執筆の時間確保のために、どんどん前倒しで学習することをお勧めします。
カリキュラム
・初めてのPython
・Python基礎
・ライブラリ「 NumPy」基礎(数値計算)
・【新】ライブラリ「Pandas 」基礎(表計算)
・ライブラリ「 Matplotlib」基礎 (可視化)
・機械学習概論
・教師あり学習(分類)
・データクレンジング
・スクレイピング入門
・ディープラーニング基礎
・CNNを用いた画像認識
・男女識別(深層学習発展)
・コマンドライン入門
・Git入門
・Flask入門のためのHTML&CSS
・Flask入門
・MNISTを用いた手 書き文字認識アプ リ作成
・アプリ制作
・Renderへのデプロイ方法
・成果物の作成
上記のカリキュラム一覧は私が受講した時点のものですが、Webアプリ開発~実装までの基礎的な知識を一通り身に着けることができます。
学習を6か月で進める場合、1つのカリキュラムにつき1~2週間でクリアしていく必要がありますが、難易度やボリュームが1つ1つ異なるので、自分の予定と相談して臨機応変に進めていくのが良いと思います。
自分の場合、序盤でPython、Numpy、Pandas、Matplotlib、これらの基礎を学ぶのが苦しくモチベーション管理に苦労しましたが、そんなときは無理せず学習ペースを落としたり、講師の方と面談して(要面談予約)モチベーションを保つなどの工夫が必要でした。
2.制作したアプリ
自作アプリ
本講座では、学習のポートフォリオとして自作アプリの制作をします。
学習モデルを自分で作ったりして複雑なアプリを制作することも可能ですが、自分はスケジュールの都合で予めデータが用意されているものを使い、
Tシャツやズボンなどの衣類の画像を識別する以下のアプリを作りました。
リンク
実際にアプリを動かしてみます。
今回はモデル作成の際に学習させた画像のデータセットに含まれない市販のTシャツのデータを読み込ませてみます。
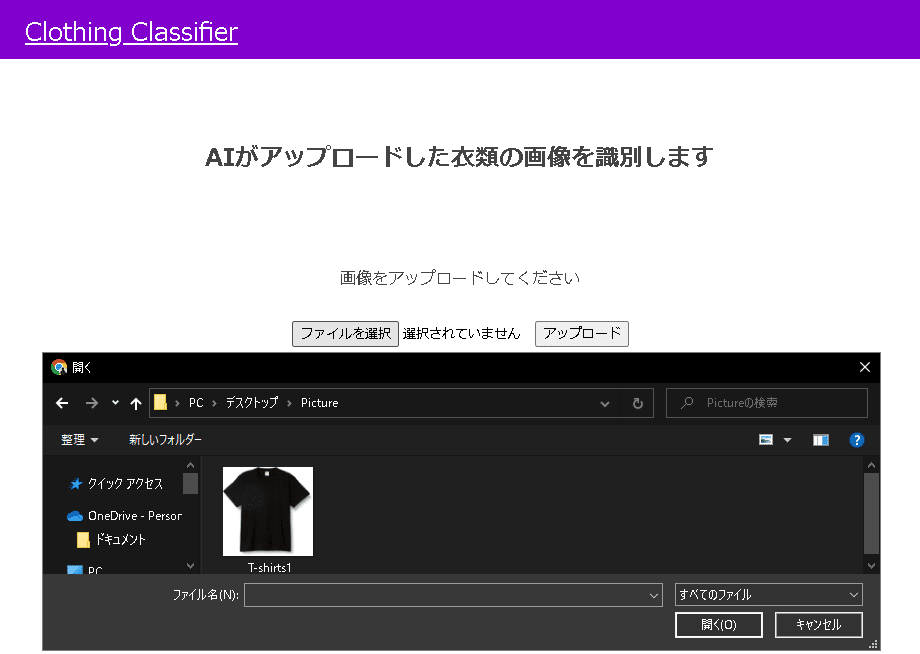
アップロードボタンを押下すると、画面下部に「これはTシャツです」と表示され、正しく識別することができました。

制作環境
・Python 3.10.9
・TensorFlow 2.12.0
・Google Colaboratory
・Fashion-MNIST(衣類の画像のデータセット)

モデル作成に使用したFashon-MNISTは、10種類の衣類の写真データセットで、手書き数字の画像セットであるMNISTと同様にKerasからロードすることができます。
モデル作成のコード
MNIST手書き文字識別アプリを作成した際のコードを参考に、
Keras.datasetsからデータセットfashion_mnistを読み込み、
学習前に画像の正規化を行います。
また、精度を出すためにBatchNormalizationをインポートします。
from keras.datasets import fashion_mnist
from keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activation
from keras.layers import Conv2D, MaxPooling2D
from keras.models import Sequential, load_model
from keras.utils.np_utils import to_categorical
from keras.utils.vis_utils import plot_model
import numpy as np
import matplotlib.pyplot as plt
#モデルの保存
import os
from google.colab import files
# データのロード
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# 画像の正規化
plt.figure()
plt.imshow(X_train[0])
plt.colorbar()
plt.grid(False)
plt.show()
X_train = X_train / 255.0
X_test = X_test / 255.0モデルを作成して重みを保存します。
# Convレイヤーは4次元配列を受け取ります。(バッチサイズx縦x横xチャンネル数)
# MNISTのデータはRGB画像ではなくもともと3次元のデータとなっているので予め4次元に変換します。
X_train = X_train.reshape(-1, 28, 28, 1)
X_test = X_test.reshape(-1, 28, 28, 1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルの定義
model = Sequential()
model.add(BatchNormalization())
model.add(Conv2D(filters=64, kernel_size=(3, 3),input_shape=(28,28,1), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
history = model.fit(X_train, y_train,
batch_size=128,
epochs=70,
verbose=1,
validation_data=(X_test, y_test))
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i].reshape((28,28)), 'gray')
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
# 予測(検証データの先頭の10枚)
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
model.summary()
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
#AccuracyとLossの結果
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train_acc', 'Test_acc'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train_loss', 'Test_loss'], loc='upper left')
plt.show()
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' ) 何パターンか試した結果、4層のCNNでモデルを作成しました。
最終的なテストデータの正解率は
Test accuracy: 0.8878999948501587(≒88.7%)
Test loss: 0.31097421050071716
となりました。
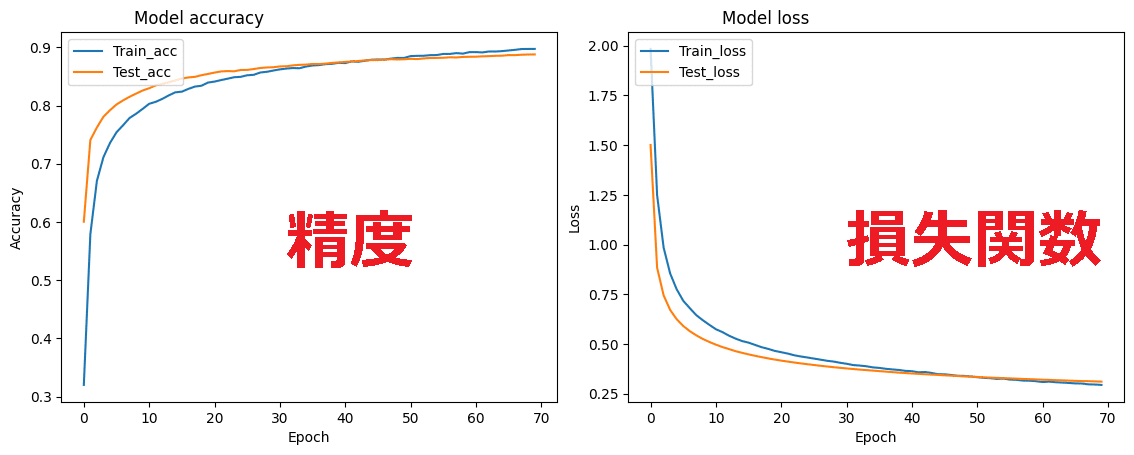
以下が学習データとテストデータの損失と精度の結果をグラフに示したものになります。
学習の回数(エポック)が増すと、損失関数が減少し、精度が上がっていることがわかります。
画像認識→結果表示のコード
アップロードされた画像をモデルに渡し、識別の結果を返すためのメインのコードです。
識別する画像をnumpyの配列形式に変換した後、前記で学習させたモデルに変換後のデータを渡して予測させ、結果を「これは~です。」の形で画面上に表示するよう作成しました。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["Tシャツ","ズボン","セーター","ドレス","コート","サンダル","シャツ","スニーカー","バッグ","ブーツ"]
image_size = 28
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5' , compile=False) #学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)3.今後の課題と活用について
モデルの精度の向上が課題だと感じています。出来れば講座中で作成した手書き文字識別アプリのように正解率90%越えにしたかったので、
それには、学習データの追加や、バッチサイズ、イテレーション数およびエポック数といったハイパーパラメータを適切に設定する必要があると思います。
学習した内容を基にモデルを作成することはできるようになりましたが、
1つひとつのモデルに合った精度の向上方法は、今後アプリを作成するなかで経験を積み、習得していきたいと思います。
4.さいごに
プログラミング&Pythonの基礎、アプリ開発から実装まで、AIの基礎を一通り学習できたので受講を決めて大変良かったと感じています。
普段何気なく触れているWEBアプリの裏側がどうなっているかを知ることができ、また、そういったサービスに触れるときの姿勢が変わりました。
卒業後はどのような道に進むか具体的には決めていませんが、早くWEBアプリ等のサービスを提供する側の一員になりたいと思っています。