
Google Colabで始める。text generation webuiでgemma2との会話

gemma2をtext generation webuiで動作させてみた記録です。内容は、GitHubのoobabooga/text-generation-webuiにあるGoogle Colabのノートブックを参考に試してみました。
ここで試したコードはPythonのオープンソースライブラリ「Gradio」を使用して、AIアプリを開発しています。Gradioは、Pythonで簡単にAIアプリのデモを作成するためのライブラリであり、Hugging Faceとの連携が可能です。
Google Colabは、無償アカウントでもNVIDIA T4 GPUを利用できます。
text-generation-webuiを実行する
次を実行すると、Google Colabの環境が開きます。
https://colab.research.google.com/github/oobabooga/text-generation-webui/blob/main/Colab-TextGen-GPU.ipynb
1. Keep this tab alive to prevent Colab from disconnecting you
「実行」(Run cell)をクリックすると、しばらくして音楽プレイヤーが表示されます。このプレイヤーを再生状態にしておくことで、Google Colabの接続が切れないようにできるようです。
2. Launch the web UI
次にLaunch the web UIを実行します。

model_url: モデルのダウンロード元URLです。Hugging Face Hub 上の turboderp/gemma-2-9b-it-exl2というリポジトリを指しています。gemma-2 はGoogleが開発した最新の大規模言語モデル(LLM)で、9bはモデルのパラメータサイズ(90億)を意味しています。turboderpはAIおよび機械学習関連のプロジェクトを開発している開発者で、特にExLlamaとExLlamaV2という推論ライブラリで知られています。ExLlamaV2はGPTQ派生の量子化モデルを使用しており、モデルの各レイヤーを動的に調整することで、精度を高めつつVRAMの消費を抑えることが可能です。つまり量子化技術を用いてモデルのサイズを小さくしつつ、計算効率を高めているモデルになります。
branch: 使用するモデルのブランチ(バージョン)です。
public URLよりアクセス
「Running on public URL」にアクセスすると、チャットが可能になります。このモデルは日本語にも対応しています。
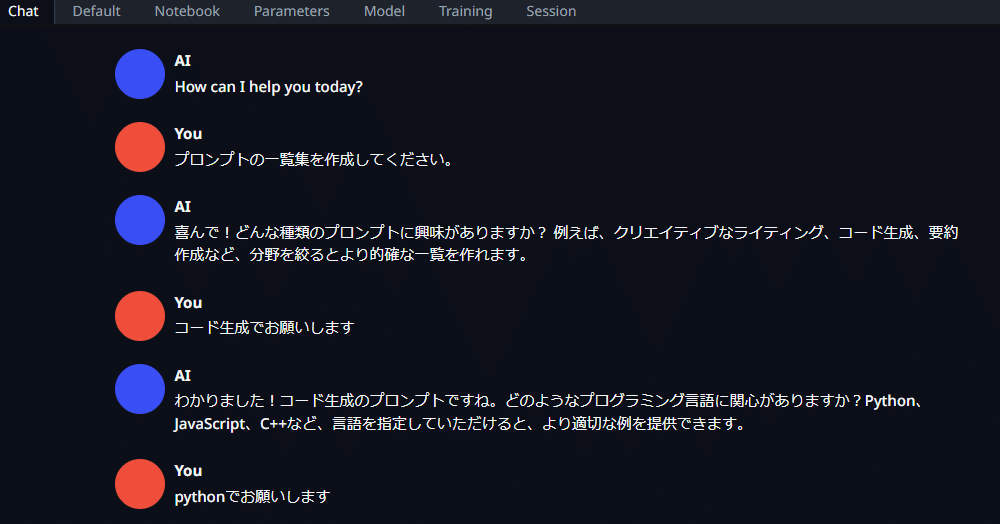
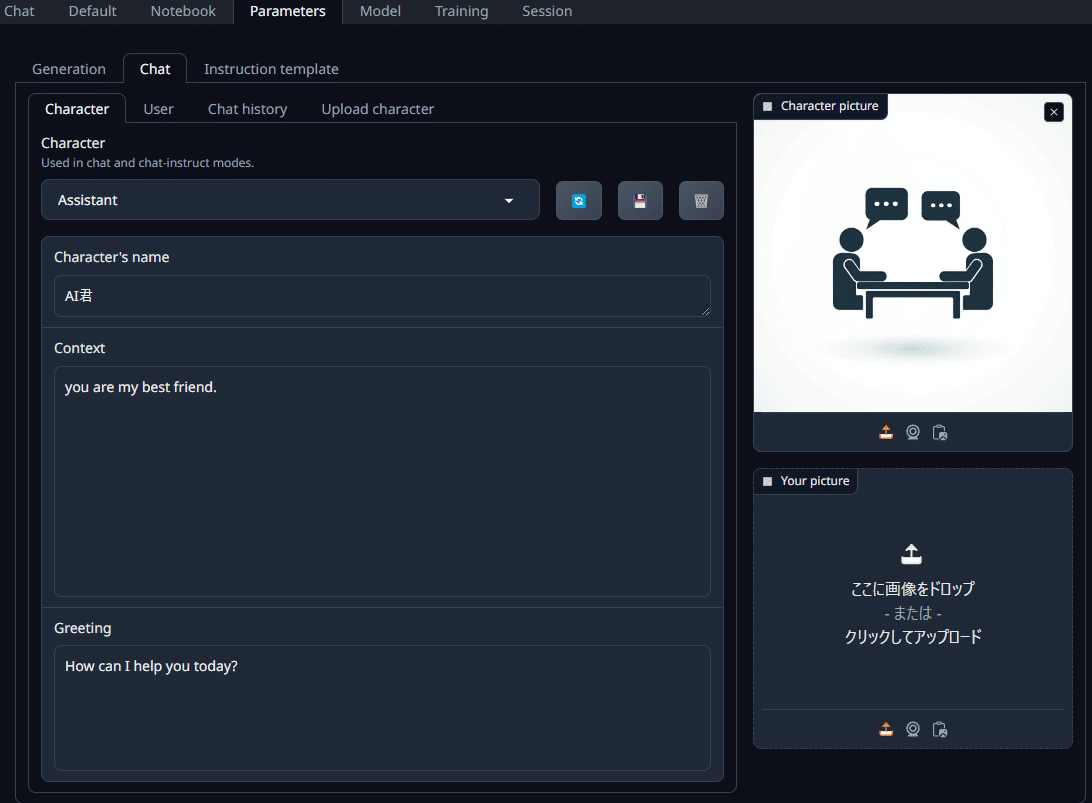
Characterの変更
ParametersメニューのCharacterタブに移動します。デフォルトでは「Assistant」となっていますが、ここでキャラクターの設定が可能です。
チャットボット設定:
モデルの応答キャラクター(名前、役割、性格など)を自由にカスタマイズできます。
会話の試行:
設定したキャラクターと実際に会話し、応答の内容や表現の自由度を確認します。
モデルの変更
ここでは、Llama-2モデルを使って新しいモデルをダウンロードして適用する手順を説明します。
1. モデルの変更手順
Modelメニューに移動します。
右下の「Download model or LoRA」を見つけ、そのすぐ上にある入力欄に「TheBloke/Llama-2-7B-Chat-GGUF」と入力してください。
「Get file list」ボタンをクリックすると、モデルのリストが表示されます。
2. モデルのダウンロード
表示された一覧の中から「llama-2-7b-chat.Q4_K_M.gguf」をコピーし、「file name」と貼り付けます選択します。
「Download」ボタンをクリックして、モデルのダウンロードを開始します。
3. モデルのリロード
ダウンロードが完了したら、左上のModelの項目にあるリロードアイコンをクリックして、モデル一覧を更新します。
プルダウンメニューから「llama-2-7b-chat.Q4_K_M.gguf」を選択します。
これで、新しいモデルが適用され、設定が完了します。

オープンソース基盤モデルの選び方
まず最初にやるのが「Open LLM Leaderboard」の確認です。特に英語ベースのモデルの性能評価が一覧で見れるため、現時点でどのモデルが注目されているかがすぐにわかります。
1.モデル選択のステップ
モデル選びは迷いがちですが、私は以下の3つのステップで整理しています。
ステップ1:基盤モデルを選択
Open LLM Leaderboardをチェックして、性能が高いモデルをまずリストアップ。候補を絞ることで迷いが少なくなります。
ステップ2:チューニング済みモデルの選択
次に、自分の用途に合ったチューニング済みモデルを探します。特定の分野に特化してチューニングされたモデルがあれば、そのまま使う方が効率的です。
ステップ3:適切なサイズの量子化モデルを選択
最後に、自分の環境(GPUなど)で快適に動作するサイズのモデルを選びます。リソースが限られている場合は、量子化モデルが役立つことが多いです。
2. 日本語特化モデルの現状と課題
日本語モデルの選定には、特徴と課題をよく理解することが重要だと感じています。
日本語モデルのメリット
日本語特化モデルの大きな魅力は、トークン分割が日本語仕様になっているため、より自然な日本語生成が可能な点です。英語ベースのモデルとは違い、日本語独自の言い回しや表現に対応できるので、文章の仕上がりがスムーズです。
日本語モデルのデメリット
しかし、学習データの量が英語モデルほど豊富でないため、専門的な知識が必要な場合など、限界を感じることもあります。そのため、必要に応じて多言語対応モデルを視野に入れることもあります。
多言語対応モデルの利点
多言語対応モデルは日本語以外のデータも学習しているため、言語の垣根を越えた思考力や文章の質が向上し、日本語でも高品質な文章を生成できるケースが多いです。私はこれを活用することで、日本語モデルの弱点を補っています。
まとめ
Googleのgemma-2をtext-generation-webuiで動作させるため、Google Colabのoobaboogaノートブックを使用し、Gradioを活用して簡単なデモを構築しました。モデルはHugging Faceからダウンロードし、量子化技術を備えたExLlamaV2でVRAM効率を高めています。また、キャラクター設定や他のモデル(Llama-2など)への切り替えも簡単に実行できました。Colab環境の無料GPUでの動作確認が可能なため、gemma-2のような大規模モデルを手軽に試せる点が非常に便利です。