
ニュース(イーラリリーの買収やTSMC高値更新など)

イーライ・リリーによるモーフィック・ホールディングの買収は、同社の製品ポートフォリオの多様化と、特に慢性疾患治療薬の開発強化を目的としています。以下に、この買収に関する主なポイントをまとめます:
買収の概要:
イーライ・リリーはモーフィック・ホールディングを約32億ドルで買収することを発表しました
買収価格は1株当たり57ドルで、モーフィックの5日終値に対して79%のプレミアムが付いています
買収は2024年第3四半期に完了する予定です
モーフィックの開発中の治療薬:
モーフィックは、炎症性腸疾患(IBD)向けの経口薬を開発中であり、成功すれば武田薬品工業の「エンタイビオ」と競合する可能性があります
エンタイビオは点滴での投与が必要なのに対し、モーフィックの開発中の薬は経口薬であるため、利便性が高いとされています
その他の開発プロジェクト:
モーフィックは自己免疫疾患やがん向けの治療薬も開発しており、これらの臨床試験を実施中です
この買収により、イーライ・リリーは自社の免疫学分野の製品ラインを拡大し、新しい治療オプションを提供することを目指しています。モーフィックの技術と開発中の薬剤は、イーライ・リリーの既存の製品とシナジーを生み出し、特に慢性疾患の治療において新たな選択肢を市場に提供することが期待されています。また、モーフィックの経口薬は、患者のQOL(生活の質)を向上させる可能性があり、これが買収の鍵となる要因の一つと考えられます。
モーフィック・ホールディングの臨床試験に関する最新の情報によると、昨年9月には臨床試験での低調なデータが原因で株価が大幅に下落したと報じられています。具体的な臨床試験の結果についての詳細は、公開されている情報からは明らかではありませんが、イーライ・リリーによる買収の発表は、モーフィックにとって前向きな展開と見なされています。
モーフィックが開発を進めている炎症性腸疾患(IBD)向けの経口薬は、成功すれば市場において武田薬品工業の「エンタイビオ」と競合する可能性があると指摘されており、点滴ではなく経口で投与できることが強みとなると考えられています
また、モーフィックは自己免疫疾患やがん向けの治療薬の臨床試験も実施しているとのことですが、これらの試験に関する具体的な結果や進捗については、追加の情報が必要となります。今後の公式な発表や研究結果の公開を待つ必要がありそうです。
モーフィック・ホールディングについての情報は以下の通りです:
会社概要:
モーフィック・ホールディングは、自己免疫疾患、心血管疾患、代謝性疾患、線維症、がんを対象にインテグリン経口薬の開発に従事するアメリカのバイオ医薬品メーカーです
開発中の薬剤:
炎症性腸疾患(IBD)向けの経口薬を開発しており、成功すれば武田薬品工業の「エンタイビオ」と競合する可能性があります。エンタイビオは点滴での投与が必要なのに対し、モーフィックの開発中の薬は経口薬であるため、利便性が高いとされています
臨床試験:
自己免疫疾患やがん向けの治療薬の臨床試験を実施していますが、昨年9月には臨床試験での低調なデータが原因で株価が大幅に下落したと報じられています
イーライ・リリーによる買収:
イーライ・リリーはモーフィック・ホールディングを約32億ドルで買収することに合意しました。買収価格は1株当たり57ドルで、モーフィックの5日終値に対して79%のプレミアムが付いています。買収は2024年第3四半期に完了する予定です
モーフィック・ホールディングは、その革新的な経口薬の開発により、特に慢性疾患の治療分野で注目されています。イーライ・リリーによる買収は、モーフィックの技術と開発中の薬剤が、イーライ・リリーの製品ポートフォリオを強化し、新たな治療オプションを市場に提供することを目指しています。

エンタイビオは、潰瘍性大腸炎などの炎症性腸疾患(IBD)の治療に使用される生物学的製剤です。以下にその特徴をまとめます:
作用機序:
エンタイビオは抗α4β7インテグリン抗体製剤で、炎症を引き起こすリンパ球が大腸に入りすぎないようにすることで、腸管での炎症を選択的に抑制します
投与方法:
点滴による静脈内投与やペン・シリンジ製剤による皮下投与があります
適応症:
中等症から重症の潰瘍性大腸炎の患者さんで、他の薬物療法(ステロイド、アザチオプリン等)等の適切な治療を行っても症状が残っている場合に投与されます
エンタイビオは、炎症の起きている腸にだけ作用し、炎症を抑えることが特徴です。潰瘍性大腸炎患者さんの大腸では、免疫にかかわるリンパ球が必要以上に大腸の組織に侵入し炎症を引き起こしていると考えられており、エンタイビオはこの炎症反応を抑制することで症状の改善を目指します。
ムーディーズ・アナリティクスのチーフエコノミスト、マーク・ザンディ氏は、米国のインフレ率が2%の目標に近づいており、全体的な経済指標が良好であると分析しています。彼は、賃貸料の指標の遅効性がインフレ率が2%を上回っている主な理由であると指摘し、現在の経済状況を踏まえて、利下げを開始すべきだと主張しています
ザンディ氏によれば、雇用と消費の鈍化、自動車販売台数の減速、そして成長の潜在成長率以下へのシフトは、米経済が下方リスクに直面していることを示唆しています。しかし、彼は9月の利下げが遅すぎるとは考えておらず、適切なタイミングであると述べています。選挙が近づくにつれて、利下げの決定がより複雑になる可能性があるものの、金融当局者は政治的影響を受けたくないという強い願望を持っているとも指摘しています
FRBが利下げを行うかどうかは、多くの要因に基づいて決定されますが、ザンディ氏の分析によると、現在の経済データは利下げを支持する方向にあると言えるでしょう。ただし、最終的な決定はFRBの政策立案者によって行われます。今後の経済指標の発表や政治的な動きに注目が集まることでしょう。
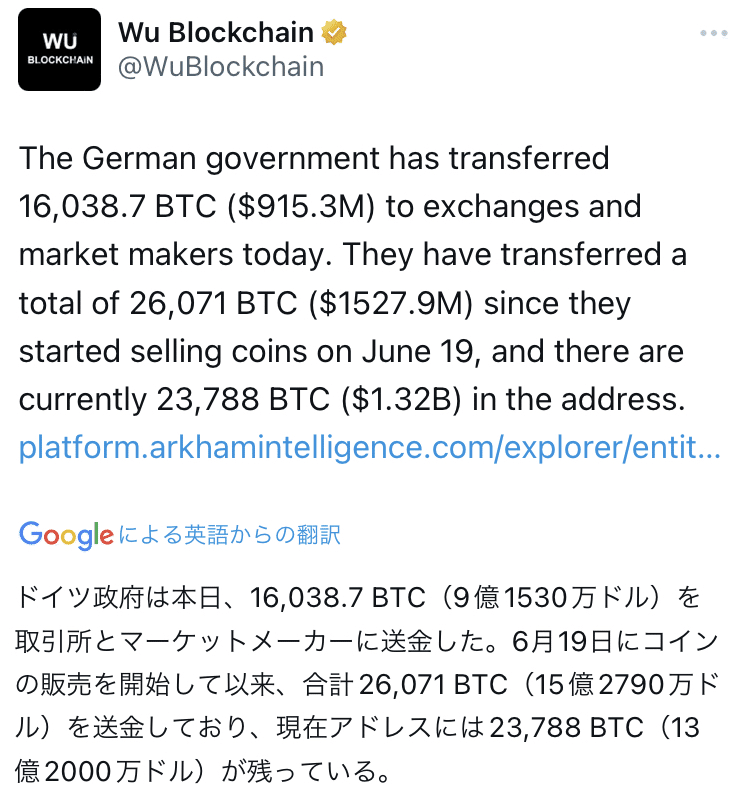
ドイツがどんどん売ってますね。半分以上売って売り圧力も減っていくと思います。

台湾積体電路製造(TSMC)の時価総額が一時的に1兆ドル(約160兆円)に到達し、世界で8番目に価値の高い企業となりました。これは、AIブームの追い風を受けて、年初来の株価が80%以上上昇した結果です。特に、米国預託証券(ADR)はニューヨーク株式市場で取引開始直後に4.8%上昇しました。TSMCは、米アップルやエヌビディアなどの重要な半導体サプライヤーとして、AIに投資する世界の投資家から高い評価を受けています。
モルガン・スタンレーは、TSMCが来週発表する決算で年間売上高見通しを上方修正すると予想しており、その結果、同社の目標株価を約9%引き上げました。このような動きは、TSMCが持続可能な成長を続けていることを示しており、AI技術の進展とその応用が今後も市場に大きな影響を与えることが期待されます。
TSMCは、AI技術の進歩とその応用に大きく投資しており、特に先端AIチップの製造に力を入れています。最新の3nmプロセス技術は、AI半導体の需要増加に対応するために開発され、TSMCの売上高の9%を占めています。また、5nmプロセスも受注が拡大しており、売上比率は37%に上昇しています。
世界的なAIブームの中で、TSMCはサーバー用AI半導体の需要が急拡大しており、その受託製造をほぼ一手に引き受けています。例えば、エヌビディアの主力チップ「H100」、AMDの「Instinct MI300」、インテルの「Gaudi3」など、多くの先端AIチップはTSMCの5nmプロセスを採用しています
さらに、TSMCは新たな半導体製造工場を台湾に建設する計画を発表し、約4000億円を投じてAI用半導体の需要増に対応するとしています。これらの動きは、TSMCがAI分野でのリーダーシップを強化し、将来の成長を見据えていることを示しています。
補足1)3ナノはどのようなケースで使われてますか?
3nmプロセス技術は、半導体製造における最新の技術革新であり、トランジスタの微細化をさらに進めたものです。従来の5nmプロセスに比べて、性能の向上、消費電力の低減、そして集積度の向上が期待されています。この技術により、より小型で高性能な電子デバイスの開発が可能となり、スマートフォンやデータセンターの効率を大幅に向上させることができます1。
特にAppleは、3nmプロセス技術をいち早く採用し、新しいM2搭載MacBook Proの後継機に投入する予定です。この技術を使用することで、Appleはデバイスの性能を大幅に向上させることができ、同時にエネルギー効率も改善されます。また、AppleのチップはRISCアーキテクチャを採用しており、これにより、より効率的な計算処理が可能になります
3nmプロセス技術は、AI、IoT、自動運転車などの新しいアプリケーションにおいても重要な役割を果たします。これらの分野では、膨大な計算リソースを必要とするため、より微細なプロセス技術により効率的なチップが求められます。さらに、3nm技術は、エネルギー効率を向上させることで、環境負荷の低減にも寄与します
これらのメリットにより、3nmプロセスは業界のスタンダードとなりつつあり、今後も多くの先進的なデバイスに採用されることが期待されています。
補足2)RISCアーキテクチャ(Reduced Instruction Set Computer)は、「縮小命令セットコンピュータ」と訳され、マイクロプロセッサ(CPU)の設計方針の一つです。このアーキテクチャは、固定長の少数の単純な命令のみを備え、実行効率を向上させることを目的としています
RISCアーキテクチャの主な特徴は以下の通りです:
単純な命令セット:複雑な命令を排除し、単純な命令のみを使用することで、命令のデコードが容易になり、高速な実行が可能です。
命令の実行時間の均一化:すべての命令が同じクロック数で実行されるように設計されており、パイプライン処理の効率化に寄与します。
ハードウェアによる実装:命令を物理的に結線した論理回路(ワイヤードロジック)で実装することで、高速化を実現します。
省電力と小型化:回路規模が小さくなるため、チップのサイズや消費電力を抑えることができます。
RISCアーキテクチャは、高性能コンピュータや携帯機器向けのプロセッサ製品で広く採用されており、特にスマートフォンやタブレットなどの携帯情報機器において、ARMアーキテクチャとして知られるRISC型のCPUが大きなシェアを占めています。また、AppleのMシリーズチップなど、パフォーマンスとエネルギー効率のバランスが求められる製品にも利用されています
補足3)
エヌビディアの主力チップ「H100」は、データセンター向けの高性能GPUであり、特にAIと機械学習のワークロードに最適化されています。以下は、H100の主な特徴です:
Tensor Core GPU: H100は第4世代のTensor Coreを搭載しており、AIトレーニングと推論の性能を大幅に向上させています
Transformer Engine: この新しいエンジンは、パラメーターが兆単位の言語モデルを実装できるように設計されており、大規模な言語モデルの推論を最大30倍高速化します
NVIDIA NVLink Switch System: 最大256個のH100を接続し、エクサスケールのワークロードを高速化できる拡張性を提供します1。
メモリ: H100は188GBのHBM3メモリを搭載しており、大規模なデータセットを扱う能力を持っています
FP8精度: H100はFP8精度で混合エキスパート(MoE)モデルのトレーニングを前世代比最大9倍高速化することができます
これらの特徴により、H100はAIアプリケーションのトレーニングと推論において、前世代のGPUと比較して大幅な性能向上を実現しています。また、H100はTSMCの4Nカスタムプロセスノードで製造され、800億トランジスタを搭載したモンスターチップであり、FP8で4PFLOPS、FP16で2PFLOPS、TF32で1PFLOPSの性能を実現しています。
このような高性能なGPUは、AIモデルの学習と展開に使用される主要チップであり、例えばOpenAIがChatGPTのようなAIモデルの学習に使用しています。さらに、メタ(Meta Platforms)は、AI戦争で優位に立つために、2024年末までに34万個以上のH100を確保する予定であると報じられています。このような動きは、AI技術の進歩とその応用が今後も市場に大きな影響を与えることを示しています。
補足3)AMDの「Instinct MI300」シリーズは、AIと高性能コンピューティング(HPC)のワークロードに特化したデータセンター向けのアクセラレータです。このシリーズは、AMDの最新のCDNA™ 3アーキテクチャに基づいており、マトリックスコアテクノロジを提供します。Instinct MI300は、INT8からFP64までの幅広い精度をサポートし、特にAI向けのスパース性への対応を含むFP8での高効率を実現しています
Instinct MI300シリーズには、GPUの「MI300X」とAPU(CPU+GPU)の「MI300A」があります。MI300Xは304個のGPU演算ユニットと192GBのHBM3メモリを搭載し、5.3TB/sのピーク理論メモリ帯域幅を持っています。一方、MI300Aは228個のGPU演算ユニットと24個の"Zen 4" x86 CPUコア、128GBの統合されたHBM3メモリを備えており、FP32を使用したワットあたりのHPCワークロード性能がMI250Xアクセラレータと比較して約2.6倍になっています
これらのアクセラレータは、AMDの第4世代Infinity Fabric™リンクを介して接続され、低レイテンシのAI処理向けに最大1.5TBのHBM3容量を提供するプラットフォームに統合されています。Instinct MI300シリーズは、エクサスケールのスーパーコンピューターに搭載され、AIを利用した史上初のシミュレーションを実行し、科学研究を前進させることが期待されています
AMDのInstinct MI300シリーズは、AIとHPCの要求に応えるための強力なツールであり、データセンターの性能と効率を大幅に向上させることができます。このような高性能なアクセラレータの開発は、AI技術の進歩とその応用が今後も市場に大きな影響を与えることを示しています。
補足4)
ワークロードとは、コンピューターやシステムにかかる処理負荷の大きさを指す用語です。ITの分野では、稼働中のコンピュータにかかっている負荷の大きさ、つまり、実行中のソフトウェアによって処理能力が占有される度合いを表します
具体的には、CPU使用率やメモリ使用率、ネットワーク使用率などの総称あるいはこれらの総体で、コンピュータの持つ資源が、その最大容量に対してどのくらいの割合が発揮・利用されているかを表すことが多いです
また、仮想化やクラウド化の文脈では、ワークロードは仮想マシン(VM)上で実行されているソフトウェア全体のメモリイメージを意味することもあります。これにはオペレーティングシステム(OS)、ミドルウェア、アプリケーションソフト、その中で展開されているデータなどが含まれます
ワークロードの管理は、これらの負荷を最適化し、システムの効率を高めるために重要です。クラウド分野では、ハイブリッドクラウド環境でワークロード管理が困難になる場合がありますが、クラウドサービスを利用することで効率的にワークロード管理ができる方法が提案されています2。ワークロードの適切な管理により、システムのパフォーマンスを向上させ、コスト削減にも寄与することができます。