
Python初心者による時系列解析〜SARIMAモデルの実装〜

はじめに
aidemyの「データ分析コース」を学び始めて6ヶ月となりました。
学習開始当初よりは、少しずつ理解が深まってきたように感じていますが、それに伴って分からない事も増えてきました。
本記事は、時系列解析手法の一つであるSARIMAモデルをPythonで実装するまでの流れをまとめたものになります。
初心者が、一から学んだことの整理と知識スキルの定着度合いの把握をするために行っていきます。読みにくい部分があるかもしれませんが、ご容赦ください。
時系列解析とは
時系列解析とは、時間の経過に伴って変化するデータのパターンや構造を分析する統計的手法です。一定の間隔で観測される時系列データ(毎日の売上や来客数、株価など)からパターンや傾向を把握し、その情報をもとに未来の値を予測したり、データの特徴やパターンを分析するを目的としています。
主な手法として
ARモデル(自己回帰モデル)
MAモデル(移動平均モデル)
ARMAモデル(自己回帰移動平均モデル)
ARIMAモデル(自己回帰和分移動平均モデル)
SARIMAモデル
などがあり、経済学や気象学、株式市場の予測、需要予測など、さまざまな分野で活用され、データのトレンドや季節性の把握、異常検出、パターン認識などにも応用されています。
以下に、4つの主な手法について説明していきます。
主な手法
ARモデル
ARモデルは、ある時点の値が、何個前までのデータの影響を受けているかを示すモデルであり、p個前の値までの影響がある場合、AR(p)と表します。例えば、今日の気温を昨日の気温を用いて単回帰したモデルはARモデルです。
MAモデル
MAモデルは、ARモデルと違い、ある時点の値ではなく過去の誤差に対して回帰していると考えるモデルです。q個前の誤差を考慮する際、MA(q)と表します。
ARMAモデル
ARMAモデルは、ARモデルとMAモデルを組み合わせたモデルになります。過去のデータとの自己相関と誤差を同時に考慮します。ARMAモデルは定常過程でしか使用できないという特徴があります。
定常過程とは、時系列データの特徴の一つであり、時間経過とともにデータの平均や分散が変化しないことを言います。
ARIMAモデル
ARIMAモデルは、ARMAモデルに差分操作(I成分(d))を組み合わせたモデルで、定常過程でない時系列データに対しても使用できることが特徴です。
差分操作とは、データの差分を計算し、非定常性を取り除くために行われます。一次差分や季節差分などがあります。
SARIMAモデル
SARIMAモデルは、ARIMAモデルに季節成分を追加したモデルです。ARIMAモデルは季節性を持つ時系列データには使用できないため、使用できるように拡張したものがSARIMAモデルになります。ARIMAモデルと同様に定常過程にない時系列データに対しても使用することができます。
ここからは、実際にサンプルデータセットを使用して、SARIMAモデルを実装していきます。
以下に、環境・サンプルデータセットについて紹介します。
環境、およびサンプルデータセット
環境
MacBook Air M1
Chrome
Python3
google colaboratory
サンプルデータセット
サンプルデータセットとして、Kaggle のStore Item Demand Forecasting Challenge のデータを使って販売実績を予測していきます。
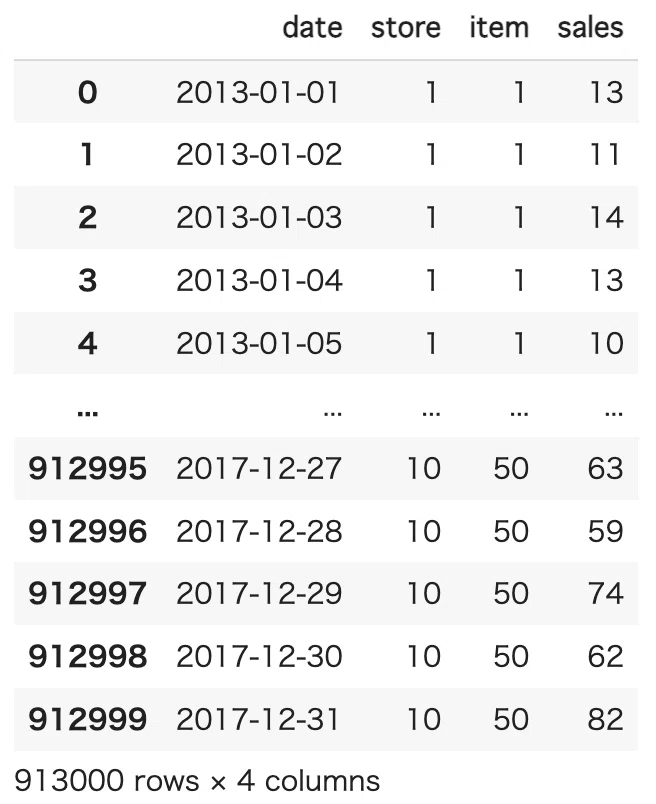
このデータでは、同じ50種類の商品を販売している小売店10店舗の2013/1/1〜2017/12/31の期間での毎日の販売実績(913000行)がトランザクションデータとしてあります。
これらのデータセットを用い、今回は store1 の item1 の 2013年から2016年 のデータを訓練データとし、2017年の予測をするSARIMAモデルの構築を行ってみたいと思います。
以下にデータセットのサンプルを示します。
SARIMAモデルの実装
Pythonでは、statsmodelsというライブラリを使うことでSARIMAモデルを実装できます。
また、SARIMAを用いた時系列データの分析手順は以下になります。
データの読み込み
データの整理
データの可視化
データの周期の把握 (パラメーターsの決定)
s以外のパラメーターの決定
モデルの構築
データの予測とその可視化
1.データの読み込み
まず、データセットをgoogle driveに保存したので、読み込んでいきます。
データセットをpandasライブラリで読み込んで表示していきます。
pandasの読み込みには、pd.read_csv()を使用します。引数に"読み込み元のファイルのパス"を用います。読み込んだcsvデータを変数"df"とします。
今回は、google driveの「MyDrive」「個人」フォルダ「aidemy」フォルダに「train.csv」という名前で保存してあるので下記のようなコードになります。
# Goole Driveにあるデータを参照する
from google.colab import drive
drive.mount('/content/drive')
# csvデータを読み込む
import pandas as pd
df = pd.read_csv('./drive/MyDrive/個人/aidemy/train.csv')2.データの整理
次に、時系列解析が行いやすいようにデータの整理を行っていきます。
まず、どんなデータが入っているかの確認します。先ほど読み込んだcsvデータを変数"df"としたので、下記のようなコードで出力します。
# データセットの確認
df
2013-01-01から2017-12-31 , store1から10 , item1から50 の毎日のsales数が入っていることがわかりました。
次にどんなデータ型のデータなのかを確認します。
df.dtypesと記述します。これでデータ型の確認をすることができます。
# データ型の確認
df.dtypes
この後の作業で、「年だけを取得したい、月だけを取得したい、日付だけを取得したい」などをしたいと思った時、dateカラムのデータ型がobject型だとうまく認識されないため、datetime型に変換しておきます。
データ型の変更は、pandasのto_datetime()関数を使います。
変数"df"の dateカラム のデータ型を変換したいので、下記のようなコードになります。
きちんと変換されているか、再度確認しておきます。
# date列のデータ型をdatetime64[ns]型に変換
df['date'] = pd.to_datetime(df['date'])
# データ型の確認
df.dtypes
きちんとdateカラムのデータ型がdatetime型に変換されました。
3.データの可視化
時系列分析をしていくにあたり、どのように販売数が変移しているか視覚的に見ていくことが重要なため、グラフ化してみようと思います。
今回予測していく、store1 の item1 がどのくらい販売されたかを見てみます。
query関数を用いて、storeカラムとitemカラムが 1 であるものを抽出し、変数"small_df"とします。
きちんと抽出できているか確認しておきます。
# "store1" "item1" のデータに絞ってみる(small_df)
small_df = df.query('(store == 1) & (item == 1)')
# データセットの確認
small_df
store と item カラムが 1 だけのものとなり、きちんと抽出できていそうです。
次に、視覚的に販売実績の傾向を掴むために、グラフで可視化します。
matplotlib ライブラリの pyplot モジュールを"plt"としてインポートします。
plt.plot()でx軸に"dateカラム" y軸に"salesカラム"を指定し、凡例を "daily_sales"とします。
次に、y軸ラベルを"Sales"とし、x軸ラベルを"date"とします。
最後に plt.legend()で凡例位置を"upper left"と指定し、 plt.show() で出力します。
# matplotlibで可視化する
import matplotlib.pyplot as plt
plt.plot(small_df["date"], small_df["sales"], label="daily_sales")
plt.ylabel("Sales")
plt.xlabel("date")
plt.legend(loc = 'upper left')
plt.show()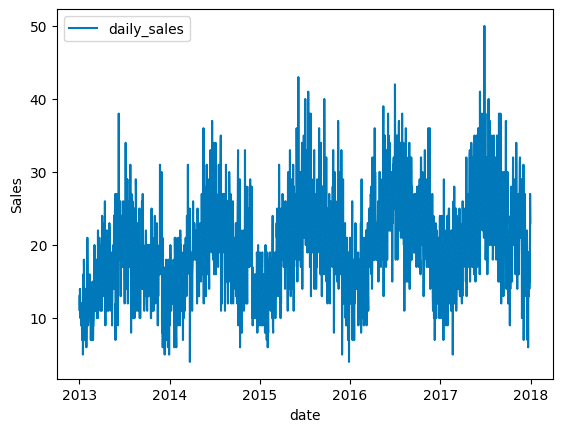
1年のサイクルで販売数が上がったり下がったりしているため、年単位での周期性がありそうな事がわかりました。
より細かく傾向を見ていくために、 store1 の item1 の 2013年 の販売実績に絞ってみます。
先ほどと同様にquery関数を用いて、dateカラムが 2013-01-01から2013-12-31 であるものを抽出し、変数"small_df_2013"とします。
きちんと抽出できているか確認しておきます。
# 年周期がありそうなため、2013年に絞ってデータを確認(small_df_2013)
small_df_2013 = small_df.query('(date >= "2013-01-01") & (date <= "2013-12-31")')
# データセットの確認
small_df_2013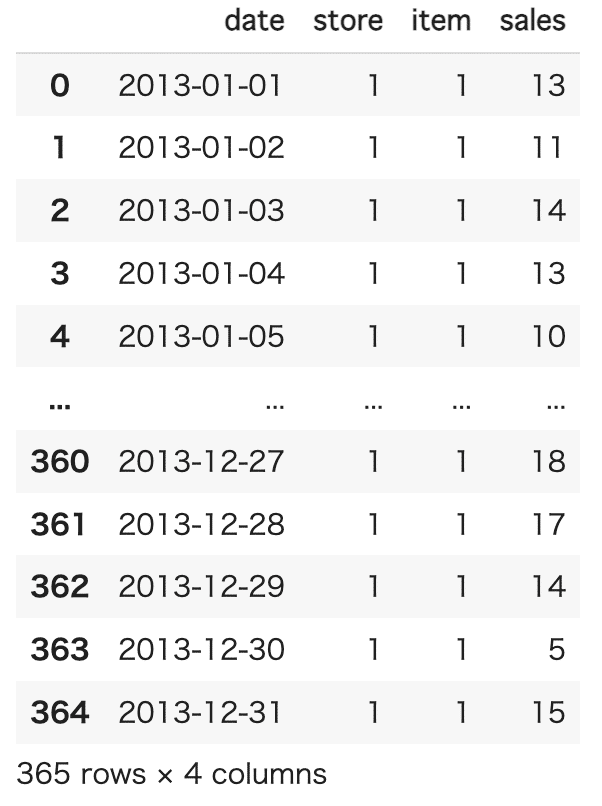
2103年だけの販売実績データとなりきちんと抽出できていることがわかります。先ほどと同様にグラフで可視化します。
plt.plot()でx軸に"dateカラム" y軸に"salesカラム"を指定し、折線グラフの色を"red"に、凡例を "2013"とします。
次に、y軸ラベルを"daily_Sales"とし、x軸ラベルを"date"とします。
最後に plt.legend()で凡例位置を"upper right"と指定し、 plt.show() で出力します。
# matplotlibで可視化する
plt.plot(small_df_2013["date"],small_df_2013["sales"], color ="red",label = '2013')
plt.ylabel("daily_Sales")
plt.xlabel("date")
plt.legend(loc = 'upper right')
plt.show()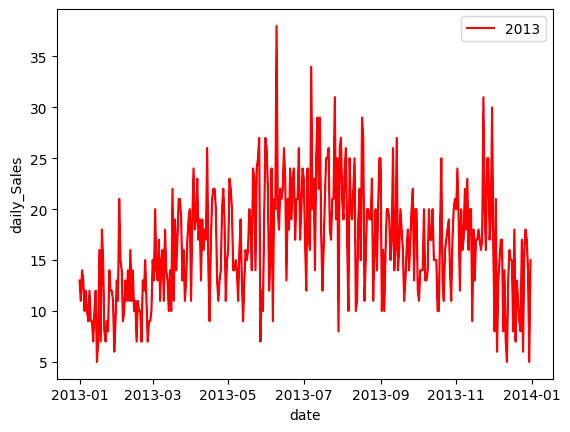
2013年の販売実績に絞ってみると、特に6月から8月あたりで販売数が増えることが見えてきました。ここまでで、季節性に関する傾向が掴めてきました。
最後に、SARIMAモデルを実装する際に必要な前処理を行っていきます。
時系列データを分析する際は、時間情報をpandasのインデックスにすることでデータを扱いやすくなるため、時間情報をインデックスにしていきます。
インデックス情報をdate_range()関数を使用して、 2013-01-01から2017-12-31 の日間隔で収集します。月間隔の場合は"M"、年間隔の場合は"Y"となります。
変数"small_df"を残しておきたいので、コピーをして変数"small_df_2"とします。
変数"small_df_2"にインデックス情報を代入し、"del small_df_2["date"]"で変数"small_df_2"の dateカラムを削除します。
また、今回予測に使用しない storeカラムと itemカラムを削除しておきます。
# 時間情報をインデックスにする
index = pd.date_range("2013-01-01","2017-12-31",freq = "D")
small_df_2 = small_df.copy()
small_df_2.index = index
# "date" カラムの削除
del small_df_2["date"]
# 今回は使用しない "store" "item" カラムの削除
del small_df_2["store"]
del small_df_2["item"]時間情報をインデックスにすると、どんな感じになるか確認してみます。
# データセットの確認
small_df_2
左側に時間情報がインデックス化され、dateカラムやstoreカラムitemカラムが削除され、データがすっきりしました。
日毎データのまま365周期で学習を行うと計算に時間がかかり過ぎてしまうので、月毎データを取り直して実装していきたいと思います。
resample().sum()を使用し、変数"small_df_2"を"月毎(M)"の"合計(sum)"にリサンプリングし、変数"small_df_month"とします。
# 日毎データだと計算に時間がかかるため、月毎データに変換
small_df_month = small_df_2.resample("M").sum()きちんとリサンプリングできたか確認します。
データが長くなるので、最初の5行のみ出力します。
head()で引数を指定しないと、最初の5行を出力できます。
# データセットの確認
small_df_month.head()
きちんと月毎の合計にリサンプリングできていそうです。
4.データの周期の把握 (パラメーターsの決定)
SARIMAモデルには、7つのパラメーター(p, d, q) (sp, sd, sq, s)があります。
p:自己相関度といい、モデルが直前 p 個の値を用いて予測されるのかを表しています。
d:誘導といい、 時系列データを定常にするために d 次の階差が必要だったことを表しています。
q:移動平均といい、モデルが直前 q 個の値に影響を受けることを表しています。
sp,sd,sq:それぞれ季節性自己相関、季節性導出、季節性移動平均といい、上記3つのパラメーターに季節性の要素を持たせたものを表しています。
s:季節周期を表します。例えば12ヶ月周期のデータであれば s = 12 とすればよいです。
ここまで、データの整理・可視化を行い、1年単位の周期がありそうなことが分かりました。月毎のデータにしたので、季節周期を表すパラメーター s = 12 としていきます。
5.s以外のパラメーターの決定
PythonにはSARIMAモデルのパラメーター(p, d, q) (sp, sd, sq, s)を自動で最も適切にしてくれる機能はありません。そのため情報量規準 (今回は BIC)によってどの値が最も適切なのか調べるコードを書かなければなりません。BICの場合は、値が低ければ低いほどパラメーターが適切であると言えます。
このコードの書き方はまだ理解できていないので、今回はaidemy教材の中から引用していきます。selectparameter()関数を定義し、 p,d,q を0から1の範囲の中から最適な値を探していきます。
import itertools
import numpy as np
import statsmodels.api as sm
import warnings
# orderの最適化関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,order=param,seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]6.モデルの構築
いよいよ、SARIMAモデルを構築していきます。sm.tsa.SARIMAXでSARIMAXモデルを実装できますが、説明変数Xを指定しなければSARIMAモデルとして使用できます。
2016年までのデータを訓練データとするため、変数"small_df_month"の後ろ12個以外のデータを変数"train"とします。後ろ12個のデータは2017年の12ヶ月分の販売実績データとなるため、訓練データから除外しています。
sm.tsa.statespace.SARIMAX().fit()関数でSARIMAモデルを構築し、変数"SARIMA_train"とします。訓練データを引用し、s以外のパラメーターは上記のselectparameter関数を実行すると探し出してくれ、order(p,d,q) はselectparameter関数の0インデックス、seasonal_order(sp,sd,sq) は1インデックスに格納されているのでそこから指定します。
#訓練データを2016年までのものとし、テストデータを2017年のものとする
train = small_df_month[:-12]
test = small_df_month[-12:]
# order(p,d,q)はselectparameter関数の0インデックス, seasonal_order(sp,sd,sq)は1インデックスに格納されている
# 周期は月毎のデータであることも考慮してs=12
best_params = selectparameter(train, 12)
SARIMA_train = sm.tsa.statespace.SARIMAX(train,order=best_params[0],seasonal_order=best_params[1]).fit()7.データの予測とその可視化
最後にデータの予測と可視化を行います。
2017年の1年間の販売実績予測を行い、実際の販売データと比較してみます。
予測はpredict()関数を用い、期間を2017-01-31から2017-12-31で指定し、変数"pred"とします。
2017年の販売実績予測は"pred"、実際の販売データは"small_df_month"
なので、それぞれ可視化していきます。変数"pred"は赤色で出力します。
# predに予測期間での予測値を代入
pred = SARIMA_train.predict("2017-01-31", "2017-12-31'")
# 可視化
plt.plot(small_df_month)
plt.plot(pred,color = "red")
plt.show()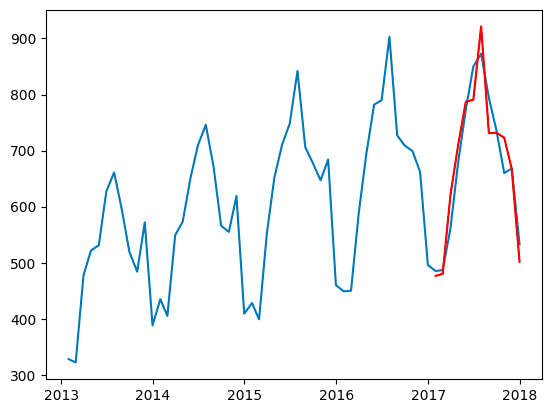
結果を見ると、おおよその予測はできていると考えていいと思います。
おわりに
ここまで6ヶ月間に渡りデータ分析について学習していきました。
途中学習が思うように進まず、心が折れかける場面が何度もありましたが、分かりやすい教材と丁寧にサポートしてくださるチューターの方々のおかげてここまで辿り着けたと思います。感謝しております。
今回、記事にまとめることで、理解できている部分と理解が不十分な部分の確認ができました。今後も継続的に学習を進めていこうと思います。
現在私は、在宅医療サービスを提供する会社に勤めています。世界でも類を見ない超高齢化社会を迎えている日本において、入院の短期化などを皮切りに在宅医療へのシフトが進んでおります。
人口分布や基幹病院のベッド数などの情報から、必要な在宅医療サービス量を予測することができれば、より地域貢献ができると考えているので、諦めずに学習を続けていこうと思います。