
【GAS】正規表現でURLを抽出する

メール群からURLのみを抽出するにはどうすれば?
LINE BOTを作った際、その準備段階として、Gmailの中から特定のタイトルのメールを抽出し、抽出した各メールに含まれるYou Tubeリンクを抽出するコードを書きました。
当初は、このリンク抽出という処理にParserライブラリを使用していました。具体的には以下のようにfromとtoを利用して、特定のフレーズの後から、次の特定のフレーズの前までの文字列を取得していました。
function getLinksInGmails() {
const query = 'subject:筋トレ部へのご参加、ありがとうございました'
const threads = GmailApp.search(query);
const dateAndLinkArr = [];
threads.forEach(thread => {
const messages = thread.getMessages();
messages.forEach(message => {
const recievedDate = message.getDate(); //日付
const messageBody = message.getPlainBody(); //本文
const youtubeLink = Parser.data(messageBody)
.from('トレーニングの参考にしていただければと思います。<br />\r\n')
.to('<br />')
.iterate();
const strYoutubeLink = String(youtubeLink);
dateAndLinkArr.push([recievedDate, strYoutubeLink]);
});
Sh1.getRange(2, 1, dateAndLinkArr.length, 1).setNumberFormat("yyyy/MM/dd"); // グローバルで指定したSh1の1列目の表示形式を設定
Sh1.getRange(2, 1, dateAndLinkArr.length, dateAndLinkArr[0].length).setValues(dateAndLinkArr); // グローバルで指定したSh1に貼り付け
});
}ですが、上のコードは、gmailに含まれるリンクの前後の「特定のフレーズ」が変更されると用をなさなくなってしまいます。そこで、You Tubeリンク自体をターゲットに指定するため、正規表現を利用することに。
正規表現でURLを抽出する
文字列からのURL抽出に広く使える「秘伝のタレ」はこちら✨
const regex = /https?:\/\/\S*/;*タブ、改行などを含むホワイトスペースで終わるURLに適用できます
ここでは、なぜこれで文字列からURLが抽出できるのかを、MDNと突き合わせて復習していきます。
まず、抽出したい文字列の前後をスラッシュで囲み、「正規表現ですよ」と合図を送っています。
さらに、抽出したい文字列に元からスラッシュが含まれている場合は、直前にバックスラッシュを入れて1つ1つエスケープします。
つまり、https:// を抽出したければ
/https:\/\//となります。
さらに、https、http のどちらもあり得る(sがつく場合と付かない場合がある)ので、sを「sが0個か1個ある」という正規表現に変えます。
MDNを見ると以下のように書かれています。

つまり、?はそのすぐ左の項目が0個か1個、を表す、ということなので、httpsのsをs?に書き換えます。
こうして、https:// または http:// を抽出したければ、
/https?:\/\//と書けばよいことになります。
さらに、https://もしくはhttp://の後に続く文字列を、改行の前まで取得したい、という場合、バックスラッシュでエスケープした大文字のSと*を追加して、
/https?:\/\/\S*/となります。
エスケープした小文字のsは、
スペース、タブ、改ページ、改行を含むホワイトスペース文字を表し、
エスケープした大文字のSは
上記の否定(つまりホワイトスペース以外の文字)を表します。
そして*はすぐ左の文字列が0個以上、という意味。
ですので、上の正規表現は、https://ホワイトスペース以外の0文字以上、を取ってきてくれるのです(つまりホワイトスペースの前まででカット)。

以上が、文字列の中から、改行などで終わるURLを抽出する一般的な正規表現でした。
さらに、文字列に含まれるすべてのURLを取ってきたい場合は、正規表現の最後のスラッシュの後にgを追加します(グローバルフラグ)。(追加しないと、最初にマッチした1つのみを取ってきます)
/https?:\/\/\S*/gとなりますね。
さらに、今回は複数のURLが含まれる文字列の中から、You Tubeリンクのみを抽出したいので、「youtu」を含めて
/https?:\/\/youtu\S*/gとします。
一般的には上記の表現で、文字列の中からYou Tubeリンクが取れます。
ただ、GmailからgetPlainBodyで取得した文字列にこれを当てはめると、改行箇所に<br />が入っているため、取得される文字列が
https://youtu.be/hogehoge<brとなってしまいます(<brが入ってしまう)。
そこで、MDNから探し出したのがこちら↓

つまり、[^A]と書くと、A以外、という意味になるようです。
ということは、
https://youtu.be/hogehoge<br>という文字列から<の前までを取り出したい時は、先程の正規表現の\S*(スペース以外の文字列である限り取り続ける)を[^<]*(<以外の文字列である限り取り続ける)に置き換えればいいはず、、、。
ということで実験してみました。
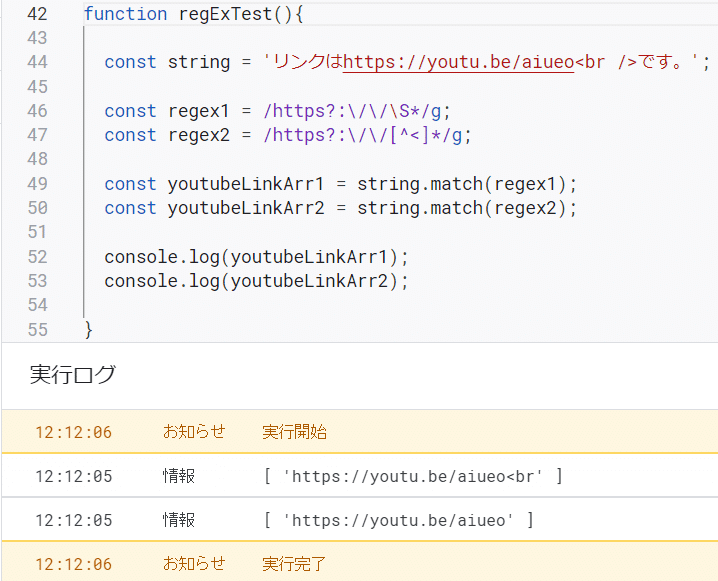
上の画像で、regex1による出力とregex2による出力を比較すると、[^<]*を正規表現に含めることで、<を含まない文字列(<の前までの文字列)が抽出できていることが分かります。
これで無事、gmailからgetPlainBodyで取得した文字列の中から、You Tubeリンクを抽出して配列にする準備が整いました!
【matchメソッドについての参考URL】https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/String/match
メールからYou Tubeリンクを抽出するコード
最終的に、Gmailから特定タイトルのメッセージを抽出し、その中から更に、日付とYou Tubリンクを抽出して二次元配列にして返すコードは、以下のようになりました。
function getInfoFromEmails() {
const titleToSearch = 'subject:筋トレ部へのご参加、ありがとうございました';
const threads = GmailApp.search(titleToSearch);
const emails = threads.map(thread => thread.getMessages()).flat();
const dateAndLinkArr = [];
emails.forEach(email => {
const emailDate = email.getDate();
const emailBody = email.getPlainBody();
const strToExtract = /https?:\/\/youtu[^<]*/g;
const youtubeLinkArr = emailBody.match(strToExtract);
if (!youtubeLinkArr) { throw 'youtubeリンクが含まれていません'; }
if (youtubeLinkArr.length > 1) { throw 'youtubeリンクが2つ以上あります'; }
dateAndLinkArr.push([emailDate, youtubeLinkArr[0]]);
});
return dateAndLinkArr;
}※getPlainBodyによって得られた文字列のYou Tubeリンクの後が<br…となっている場合に特化した正規表現です。
※当初は、文字列からURLを抽出をする部分を別関数に切り分けていたのですが、対象をYou Tubeに限定にしたこと、そして、文末が<である場合に限定したことで、汎用性が限定されたため、元の関数の中へ戻しています。
※mapとforEachは、いずれも配列の各要素に対して処理を行いますが、戻り値を配列にして後で利用したい場合はmap、そうでなく単に反復処理したいだけの場合はforEach、と使い分けるそうです。emailsの取得にはmapを使わず、forEachをネストする形も可能です。(今回は、別の用途も考えていたため、1回目の反復処理にはmapを使っています)