
stabilityai/japanese-stable-clip-vit-l-16 を利用して、ローカルの画像フォルダを自然言語で検索してみる

stabilityai/japanese-stable-clip-vit-l-16 という、Stability AI社による、日本語のCLIPのモデルが公開されました。有り難い限りです。
これを使って、ローカルの画像フォルダを日本語の自然言語で検索してみました。
以下の様に、500枚ほどの画像が入っています。私が東京ゲームショウで撮影した写真、VTuberイベントで撮影した写真、うちの猫、ゲームのスクリーンショットなどです。
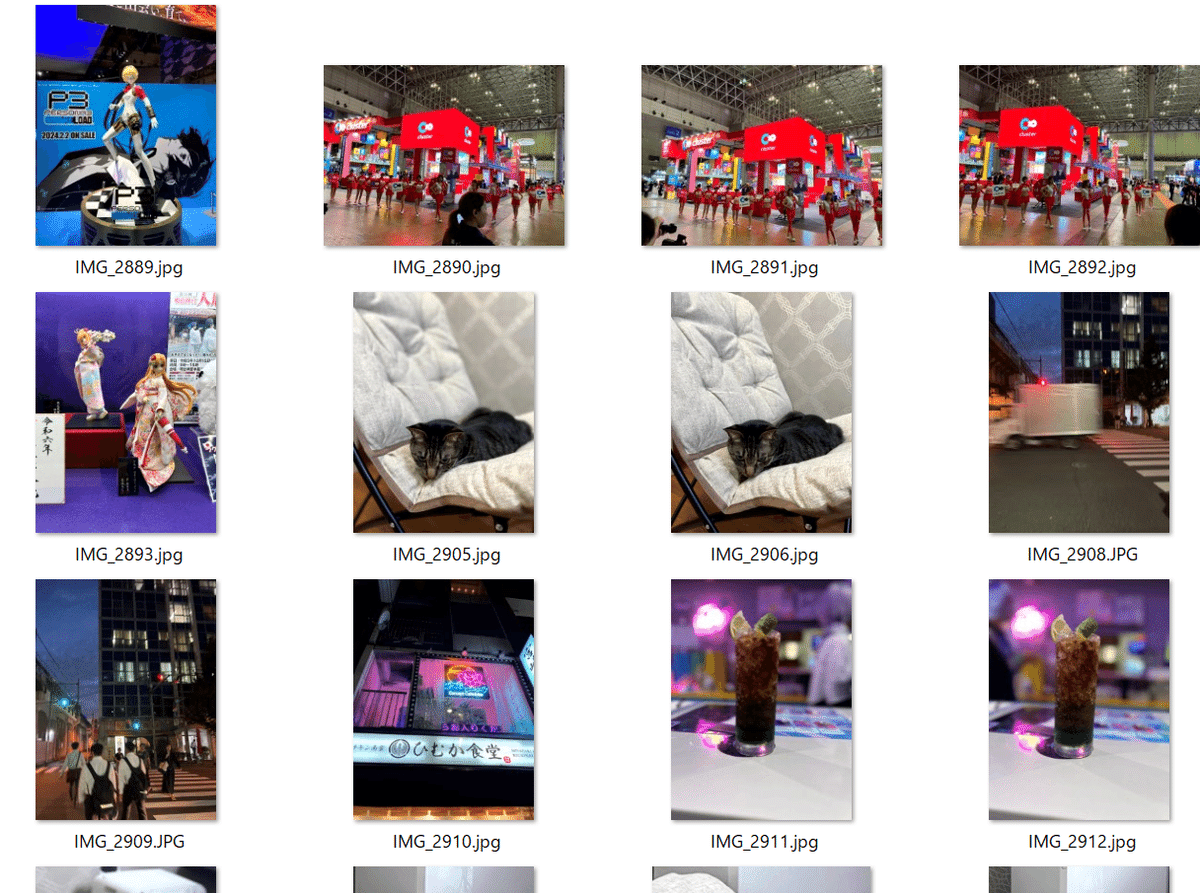
このフォルダに対して自然言語で検索すると、以下の様に画像を取り出すことができました。



画像を自然言語で検索するなんてことが、個人のPCで動かせるなんて嬉しいです! ちょっと違うものが出てきてはいますが、十分な性能ではないでしょうか。
ステップとしては、
検索対象とするフォルダの画像全部のベクトルを生成し、JSONファイルに保存
検索したい文字列のベクトルを生成し、ベクトルとして近い画像のファイル名を返す
というシンプルなものです。
ちなみに、画像フォルダは、pythonファイルがあるフォルダの直下imagesとしてある想定です。
必要なパッケージのインストール(Windows 11で動かす想定)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install ftfy pillow requests transformers sentencepiece protobuf gradio tqdmまずは、フォルダ内の画像のベクトルを生成します。
# make_embeddings.py
from transformers import AutoModel, AutoTokenizer, AutoImageProcessor
import os
import glob
from tqdm import tqdm
from PIL import Image
import torch
import json
# モデルとトークナイザーとプロセッサーの準備
model = AutoModel.from_pretrained(
"stabilityai/japanese-stable-clip-vit-l-16",
trust_remote_code=True
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(
"stabilityai/japanese-stable-clip-vit-l-16"
)
processor = AutoImageProcessor.from_pretrained(
"stabilityai/japanese-stable-clip-vit-l-16"
)
# imagesフォルダの中身の画像を全てprocessorでembeddingに変換
image_features = []
for image in tqdm(glob.glob("./images/*")):
# imageが画像ファイルでないならスキップ
if not image.endswith(('.jpg', '.png', '.jpeg')):
continue
# imageのファイルネームを取得
filename = os.path.basename(image)
image = Image.open(image)
image = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
embedding = model.get_image_features(**image)
embedding = embedding / embedding.norm(dim=-1, keepdim=True)
image_features.append({'embedding': embedding,
'filename': filename})
# print(image_features[0])
# image_featuresを文字列に変換
image_features_json = []
for image_feat in image_features:
image_features_json.append({'embedding': image_feat['embedding'].tolist(),
'filename': image_feat['filename']})
# image_featuresをJSONに保存
with open('image_features.json', 'w', encoding='utf-8') as f:
json.dump(image_features_json, f, indent=4)
すると、image_features.json が生成されます。
画像を検索するスクリプトは以下です。gradioでブラウザから操作出来るようにしています。
# image_search.py
from transformers import AutoModel, AutoTokenizer
import ftfy, html, re, torch, gradio as gr
from typing import Union, List
from transformers import BatchFeature
import json
# モデルとトークナイザーとプロセッサーの準備
model = AutoModel.from_pretrained(
"stabilityai/japanese-stable-clip-vit-l-16",
trust_remote_code=True
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(
"stabilityai/japanese-stable-clip-vit-l-16"
)
def basic_clean(text):
text = ftfy.fix_text(text)
text = html.unescape(html.unescape(text))
return text.strip()
def whitespace_clean(text):
text = re.sub(r"\s+", " ", text)
text = text.strip()
return text
def tokenize(
tokenizer,
texts: Union[str, List[str]],
max_seq_len: int = 77,
):
if isinstance(texts, str):
texts = [texts]
texts = [whitespace_clean(basic_clean(text)) for text in texts]
inputs = tokenizer(
texts,
max_length=max_seq_len - 1,
padding="max_length",
truncation=True,
add_special_tokens=False,
)
input_ids = [[tokenizer.bos_token_id] + ids for ids in inputs["input_ids"]]
attention_mask = [[1] + am for am in inputs["attention_mask"]]
position_ids = [list(range(0, len(input_ids[0])))] * len(texts)
return BatchFeature(
{
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long),
"position_ids": torch.tensor(position_ids, dtype=torch.long),
}
)
# image_featuresをJSONから読み込み
with open('image_features.json', 'r', encoding='utf-8') as f:
image_features_json = json.load(f)
print(len(image_features_json))
# image_features_jsonをimage_featuresに変換
image_features = []
for image_feat in image_features_json:
image_features.append({'embedding': torch.tensor(image_feat['embedding']).to('cuda'),
'filename': image_feat['filename']})
def find_similar_image_and_display(query: str):
# 既存のコード
text = tokenize(
tokenizer=tokenizer,
texts=[query],
).to("cuda")
# 推論の実行
with torch.no_grad():
text_features = model.get_text_features(**text)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
# 画像の特徴量とテキストの特徴量の間のコサイン類似度を計算
cos_similarities = torch.stack([torch.nn.functional.cosine_similarity(text_features, img_feat['embedding'], dim=-1) for img_feat in image_features]).squeeze()
# cos_similaritiesが空でないことを確認
if len(cos_similarities) == 0:
return []
top_k = min(3, len(cos_similarities))
try:
top_sim_indices = cos_similarities.topk(top_k, largest=True).indices
selected_images = [image_features[idx]['filename'] for idx in top_sim_indices]
except RuntimeError as e:
print("Runtime error occurred:", e)
return []
# 画像のファイルパスを返す
return [f"images/{filename}" for filename in selected_images]
# Gradioインターフェースの出力を変更
iface = gr.Interface(
fn=find_similar_image_and_display,
inputs="text",
outputs=gr.Gallery(label="Images")
)
iface.launch()cosine_similaritiesを計算するところで、次元数を落とす.squeeze()を付け忘れたことでしばらくハマりました。テンソル計算、難しい。
あとは、image_search.pyを実行して、Gradioが起動すれば、ブラウザから操作することができます。
今回は500枚程度の画像なので配列でやってしまいましたが、もっと大量になってくるのなら、ベクトル検索に向いたデータベースや、faissのようなベクトル検索用のライブラリを使うのがいいかもしれません。
なお、Japanese Stable CLIPの使い方は、npakaさんの記事を参考にさせていただきました。
Japanese Stable CLIPはいろいろな活用法がありそうなので、探求したいです。