
マルチモーダルembeddigモデルE5-Vを試してみる

画像と文字列を同じ埋め込みベクトル化できるマルチモーダルなembeddingモデルE5-Vというものを知ったので、試してみました。
画像と文字列を共にベクトル化できるとなると、先行するものとしてCLIPやSigLIPがありますが、このE5-Vは画像も理解するLLMであるLLaVA-NeXT-8Bをベースにしていることから、文章理解力が上がっているようです(上記論文参考)。
画像と文字列とでモダリティギャップがない、つまりは、似た意味なら画像だろうと文字列だろうと近いベクトルになる、という主張のようです。右側がE5-Vのイメージ
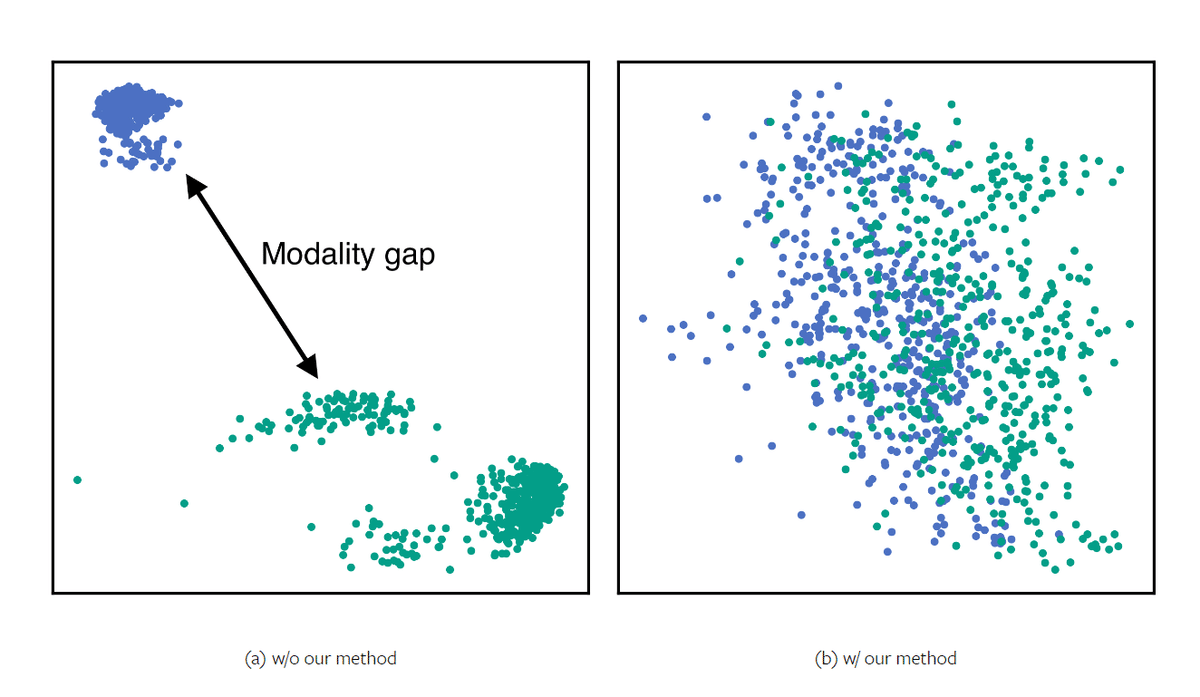
とりあえず、サンプルプログラムを元に、動かしてみました。
動作環境
Windows 11, Python 3.12.4, GeForce RTX 4090 (VRAM 24GB)
画像はWikipediaから借りることにしました。

文字列としては、'高原で暮らすリャマ', 'ボリビアのリャマ', '日本の温泉地にいるサル', '日本の伝統工芸'をチョイス。あえて「折鶴」や「折り紙」と言わずに、「日本の伝統工芸」として、意味を近く解釈するかどうかを見てみたかったからです。
これらで類似度マトリックスをとってみると、こんな感じでした。
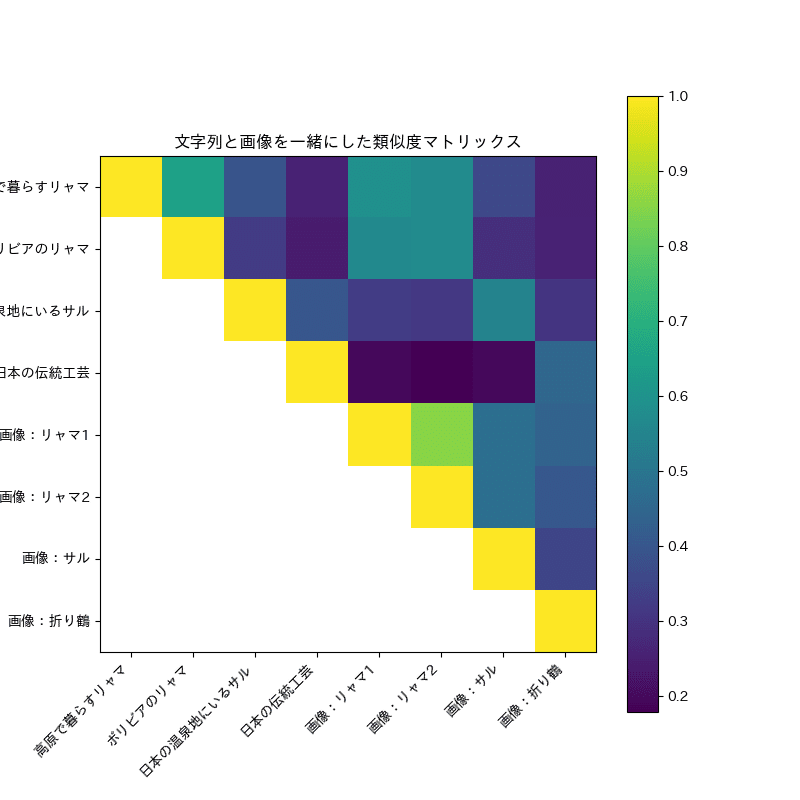
文字列「高原で暮らすリャマ」「ボリビアのリャマ」と、画像の「リャマ1」「リャマ2」はそれぞれ、色が薄い、つまり類似度が近いと判定されています。
文字列「日本の伝統工芸」と画像「折り鶴」の組み合わせも、他に比べれば色が薄い。リャマよりは近いと判断できていそうです。
これはなかなか面白い。より長文で試してみたいところです。
今回試したコード
必要そうなライブラリをインストールします。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers accelerate matplotlib bitsandbytes requests pillow matplotlib-fontjaほぼサンプルのままですが、一応コードを。
import torch
import torch.nn.functional as F
import requests
from PIL import Image, UnidentifiedImageError
from io import BytesIO
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import numpy as np
import matplotlib.pyplot as plt
import matplotlib_fontja
# テンプレートの定義
llama3_template = ('<|start_header_id|>user<|end_header_id|>\n\n{'
'}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n \n')
# プロセッサとモデルの初期化
processor = LlavaNextProcessor.from_pretrained('royokong/e5-v')
model = LlavaNextForConditionalGeneration.from_pretrained('royokong/e5-v', torch_dtype=torch.float16, load_in_4bit=True)
# プロンプトの定義
img_prompt = llama3_template.format('<image>\nSummary above image in one word: ')
text_prompt = llama3_template.format('<sent>\nSummary above sentence in one word: ')
# テキストと画像URLのリスト
texts = ['高原で暮らすリャマ',
'ボリビアのリャマ',
'日本の温泉地にいるサル',
'日本の伝統工芸']
images_urls = ['https://upload.wikimedia.org/wikipedia/commons/1/1a/Dos_llamas_en_Bolivia_%28deciembre_2001%29.jpg',
'https://upload.wikimedia.org/wikipedia/commons/f/f0/Llama_La_Paz_Bolivia.jpg',
'https://upload.wikimedia.org/wikipedia/commons/8/8c/Jigokudani_hotspring_in_Nagano_Japan_001.jpg',
'https://upload.wikimedia.org/wikipedia/commons/f/f8/%E6%8A%98%E9%B6%B4_WUXGA.jpg']
# テキストの処理
text_inputs = processor([text_prompt.replace('<sent>', text) for text in texts], return_tensors="pt", padding=True).to(
'cuda')
# 画像のダウンロードと処理
images = []
# ブラウザのユーザーエージェントを偽装するためのヘッダー
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 '
'Safari/537.36'
}
for url in images_urls:
response = requests.get(url, headers=headers)
if response.status_code == 200:
img_data = BytesIO(response.content)
try:
img = Image.open(img_data)
images.append(img)
except UnidentifiedImageError:
print(f"画像を開けませんでした: {url}")
else:
print(f"画像のダウンロードに失敗しました: {url} ステータスコード: {response.status_code}")
img_inputs = processor([img_prompt] * len(images), images, return_tensors="pt", padding=True).to('cuda')
# 埋め込みの生成
with torch.no_grad():
text_embs = model(**text_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
img_embs = model(**img_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
# 埋め込みの正規化
text_embs = F.normalize(text_embs, dim=-1)
img_embs = F.normalize(img_embs, dim=-1)
# Combine text and image embeddings
combined_embs = torch.cat((text_embs, img_embs), dim=0)
# Calculate similarity matrix
similarity_matrix = combined_embs @ combined_embs.t()
# Convert to numpy for visualization
similarity_matrix_np = similarity_matrix.cpu().numpy()
# Mask the lower triangle of the matrix
mask = np.triu(np.ones_like(similarity_matrix_np, dtype=bool))
masked_similarity_matrix = np.where(mask, similarity_matrix_np, np.nan) # Use np.nan to mask
# Define the labels for the x and y axes
labels = ['高原で暮らすリャマ', 'ボリビアのリャマ', '日本の温泉地にいるサル', '日本の伝統工芸',
'画像:リャマ1', '画像:リャマ2', '画像:サル', '画像:折り鶴']
# Visualize the masked similarity matrix
plt.figure(figsize=(8, 8))
plt.imshow(masked_similarity_matrix, cmap='viridis')
plt.colorbar()
plt.title('文字列と画像を一緒にした類似度マトリックス')
# Set the custom labels for the x and y axes
plt.xticks(ticks=np.arange(len(labels)), labels=labels, rotation=45, ha="right")
plt.yticks(ticks=np.arange(len(labels)), labels=labels)
plt.show()
ライセンスについて
LLaVA-NeXT-8BはLLaMA-3 8Bを元にした、画像も解釈できるLLMです。商用利用はNGの研究目的モデルなので、このE5-Vもそのライセンスを引き継いでいると思います。また、LLaMA-3 8Bのライセンスなども引き継いでいるので、ライセンス回りは複雑です。E5-Vはあくまでも研究目的と理解するのが良さそうです。
画像について
クリエイティブ・コモンズ 表示-継承 3.0 非移植 1992, photo by SHIBUYA K.
クリエイティブ・コモンズ 表示-継承 3.0 非移植 作者Yosemite
パブリックドメイン