
Python メモ(NumPyとPandas)

ライブラリとは?
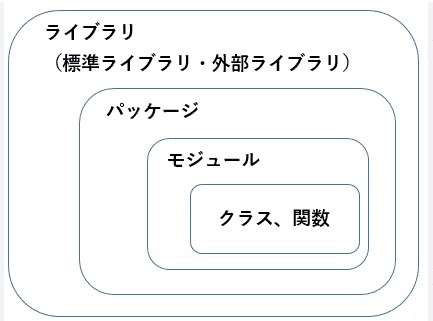
●ライブラリ
・便利な機能をひとまとまりにしたもの
・複数のパッケージからなる
・標準ライブラリと外部ライブラリの2種類ある
標準ライブラリ:Pythonインストール時から備わっているライブラリ
外部ライブラリ:Pythonに搭載されていない、第三者が作成したライブラリ
●パッケージ
・複数のモジュールからなる
・.pyファイルが複数あるフォルダ
●モジュール
・再利用可能なPython のコード(.py)
●関数
・特定のタスクや処理を実行
●クラス
・オブジェクト指向における設計図のこと
便利な標準ライブラリ
datetime
日付や時刻を操作するための標準ライブラリ
# datetime ライブラリをインポート
import datetime
#現在の年、月、日、時間、分、秒、マイクロ秒を取得
now = datetime.datetime.now()
#取得した時刻を表示
print(now)
#日時それぞれの値を別々に確認
print(
now.year, #年
now.month, #月
now.day, #日
now.hour, #時
now.minute, #分
now.second, #秒
now.microsecond, #マイクロ秒
)glob
指定したパターンに適合したフォルダ名やファイル名のパスを取得する標準ライブラリ
# glob ライブラリから glob 関数をインポート
from glob import glob
# 実行している ipynb ファイルと同じフォルダにあるファイルとフォルダをすべて取得
files = glob('*')
# 実行している ipynb ファイルと同じフォルダにある txt ファイルのパスをすべて取得
files = glob('*.txt')
print(files)random
疑似乱数を生成したい場合に利用する標準ライブラリ
randomライブラリを使うことで、代表的な確率分布に従う疑似乱数が生成できる。
・一様分布
・正規分布(ガウス分布)
・対数正規分布
・負の指数分布など
※セキュリティ(パスワード生成など)や暗号の用途ではrandomライブラリを使ってはいけない。
# random ライブラリをインポート
import random
# シード値を設定
random.seed(0)
# 100以上〜1000以下の範囲から乱数を10個生成
for _ in range(10):
print(random.randint(100, 1000))NumPyとPandas
どちらもデータを「箱」に格納する処理に便利な外部ライブラリ
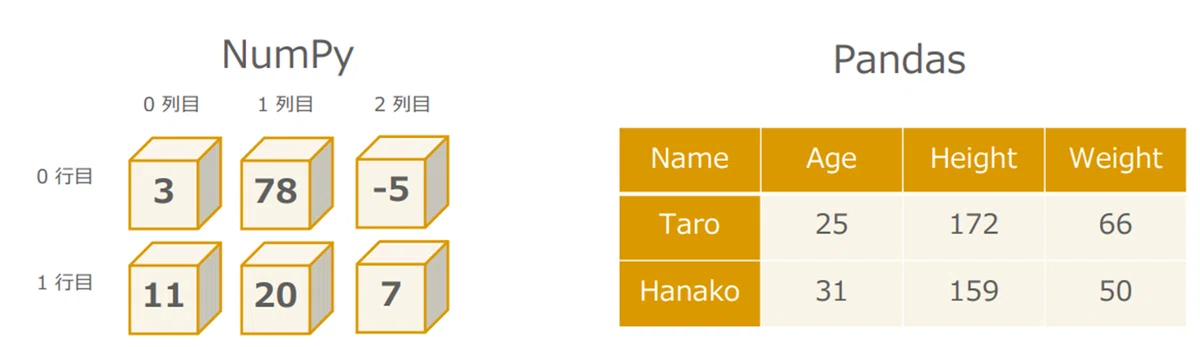
Numpy:ベクトルや行列など配列を扱うのが得意
Pandas:一つ一つの値に何かしらの意味があるようなデータを扱うのが得意
NumPy

●多次元かつ大量のベクトル・行列の演算が得意
●中身がCやFortranを用いて実装されており処理が高速
●Pandas・Matplotlibなど多くのライブラリはNumPyに依存
【配列の作り方(1次元)】
#Numpyのインポート
import numpy as np
a = np.array([1, 2, 3])
#誤:エラーが生じる
#a = np.array(1, 2, 3) 【配列の作り方(2次元)】
# 正
a = np.array([[1, 2, 3],
[4, 5, 6]])
# 誤:エラーが生じる
#a = np.array([1, 2, 3],
# [4, 5, 6]) 【配列の性質】

【配列の形を変える】
reshape(p,q):p行q列の行列に変換
#6要素の配列を生成
array = np.array([1, 2, 3, 4, 5, 6])
#arrayを2x3行列に整形
arr2x3 = array.reshape(2, 3)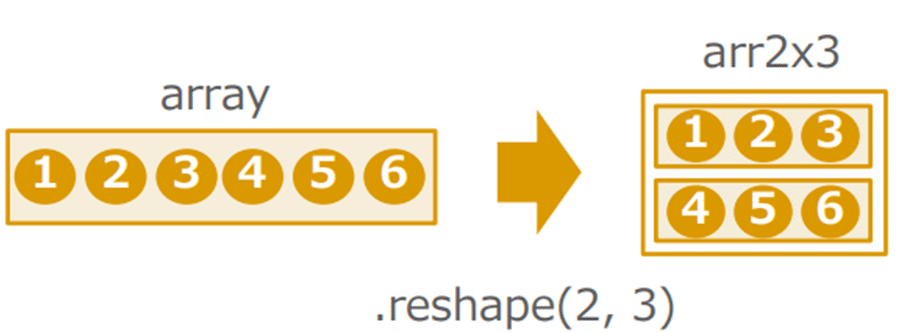
ravel( ):1次元の行列にほどく
a = arr2x3.ravel()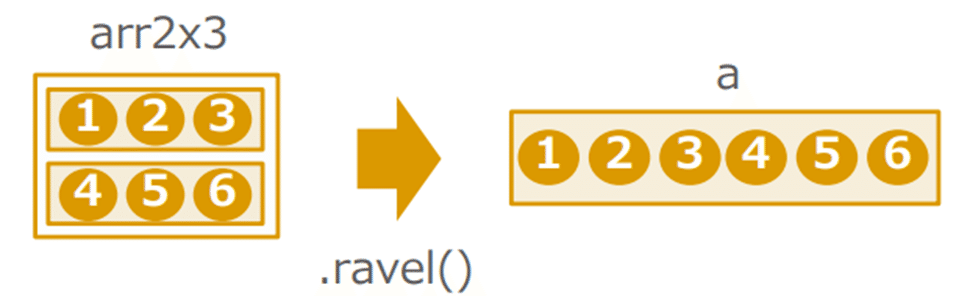
transpose( ):転置を行う
→行と列を入れ替える操作
#転置行列
a2x3_T = arr2x3.T
#transpose関数でも同様
arr2x3_transpose=arr2x3.transpose()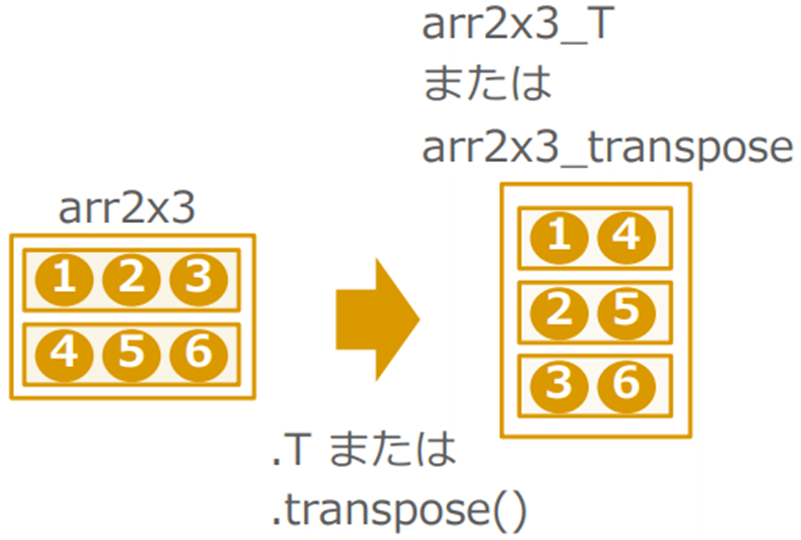
Pandas

表形式でデータを扱うことのできるライブラリ
表のことをデータフレームと呼ぶ
Pandasでは列名が重要!
【データフレームの作成】
#ライブラリのインポート
import pandas as pd
df = pd.DataFrame({
#'表の項目(=列名)':[表の要素(=各行の値)]
'Age':[12,14,12,18],
'Gender':['M','M','F','F'],
'Height':[150,160,150,175],
'Weight': [35,50,36,60]})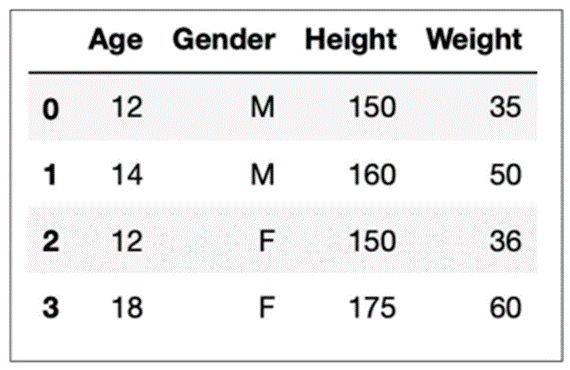
データフレームの概要表示
df.info()【データフレームの確認】
# dfのindex前から二つを表示する
df.head(2)
# dfのindex後ろから二つを表示する
df.tail(2)
#headもtailも()に数値を入れないと5つ表示してくれる
#全ての列の名前を出す
df.columns
#全てのindexを出す
df.index【列の追加・削除】
#ライブラリのインポート
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40]
}
#新しい列の追加
df['Salary'] = [50000, 60000, 70000, 80000]
#列を削除,columnsというパラメータで指定
df = df.drop(columns='Age')↑前処理の過程でよく用いる!
【データフレームの参照】
特定の列を取り出す場合、
#列名を指定してデータを参照
df['Salary']
df.Salary
#↑二つは同義
#2列同時に参照する場合
df[['Name', 'Salary']]インデックスとヘッダーを同時に指定して特定のデータを取り出す
→loc[]を使う
df.loc["インデックス番号", "列名"]
【欠損値処理】
欠損値:値の存在しないデータ。よくNaNと表現される。(Not a Number)
欠損値が含まれると分析が困難なため何かしらの対処する必要がある。
欠損値の対処法
①欠損値を含む行を削除する
②欠損値を平均値や中央値などの別の値で置き換える
欠損値はnp.nanで作成
#欠損したデータフレーム
df = pd.DataFrame({'Age':[12,14,12,18],
'Gender':['M','M','F','F'],
'Height':[np.nan,160,150,175],
'Weight': [35,50,np.nan,60]})isnull関数で欠損値の存在を確認
True:欠損値である
False:欠損値でない
#Isnull関数を用いて欠損値の存在を確認
#欠損値ならばTrueが表示される
df.isnull()
#欠損地の数を数える
df.isnull().sum()dropna関数:欠損値を含む行を削除
データの総件数に対して、欠損値を含む行がわずかであればこの方法でOK
fillna関数:欠損値を置き換え