ChatGPTやLLM関連で必要なEmbeddingsとは? 【OpenAI Embeddings】

はじめに
ChatGPTをはじめとするLLM関連で重要な技術であるEmbeddingsについてまとめてみました。
LangChainやLlamaindexのRetriever機能でもEmbeddingsが使われています。
LangChainやLlamaindexでは数行のコードでRetrieverが実現できるので、あまりEmbeddingsそのものは理解しなくても動いてしまいますが、動きや仕組みを理解するにはEmbeddingsの知識が必要になってきます。
「Embeddingsって何?」という人向けに、公式ガイドの説明をまとめました。
Embeddings
Embeddingsとは?
Embeddingsは、2 つのテキスト間の関連性を測定するために使用できるテキストの数値表現です。
Embeddingsは、検索、クラスタリング、推奨、異常検出、および分類タスクに役立ちます。
OpenAI のEmbeddingsは、テキスト文字列の関連性を測定します。
Embeddingsは一般的に次の目的で使用されます。
検索(クエリ文字列との関連性によって結果がランク付けされます)
クラスタリング(テキスト文字列が類似性によってグループ化される)
推奨事項(関連するテキスト文字列を持つアイテムが推奨される場合)
異常検出(関連性の低い外れ値が特定される場合)
多様性測定(類似性分布を分析する場合)
分類(テキスト文字列が最も類似したラベルによって分類されます)
Embeddingsは、浮動小数点数のベクトル (リスト) です。2 つのベクトル間の距離によって、それらの関連性が測定されます。
距離が小さい場合は関連性が高いことを示し、距離が大きい場合は関連性が低いことを示します。
似たような文章を検索するときに使われる「ベクトル検索」では、この距離をもとに意味が近いかどうか判断しています。
Embeddingsは、数値シーケンスに変換された概念の数値表現で、コンピューターがそれらの関係を理解しやすくなります。
人間の言葉のままでは、コンピュータは意味が理解しにくいですが、数値に変換することによりコンピュータが理解しやすくなります。
OpenAI /embeddingsエンドポイントの最初のリリース以来 、多くのアプリケーションにコンテンツのパーソナライズ、推奨、検索を行うためにEmbeddingsが組み込まれてきました。

リクエストは、送信された入力内のトークンの数に基づいて課金されます。
Model
Ada v2(text-embedding-ada-002)
Usage
$0.0001 / 1K tokens
トークン数を調べたい場合は以下のサイトが役立ちます。
例えば 「ChatGPT」という単語は3トークン使用されます。

Embeddingsを取得する方法
Embeddingsを取得するには、選択したEmbeddingsのModel ID (例: text-embedding-ada-002) とともにテキスト文字列をEmbeddings用のAPIエンドポイントに送信します。
レスポンスにEmbeddingsの結果が含まれており、抽出、保存、使用できます。
Embeddingsの作成
POST https://api.openai.com/v1/embeddings入力テキストを表すEmbeddingsベクトルを作成します。
サンプルコード
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Embedding.create(
model="text-embedding-ada-002",
input="The food was delicious and the waiter..."
)
パラメータ
{
"model": "text-embedding-ada-002",
"input": "The food was delicious and the waiter..."
}
レスポンス
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
Request Bodyの説明
model: string(必須)
使用するModel IDを記載します。
通常は最新のtext-embedding-ada-002を指定します。
input: string or array(必須)
Embeddings対象のテキストを入力し、文字列またはトークンの配列としてエンコードします。1 つのリクエストに複数の入力を埋め込むには、文字列の配列またはトークン配列の配列を渡します。各入力は、モデルの最大入力トークン ( text-embedding-ada-002の場合は 8191 トークン) を超えてはなりません。
user: string(任意)
エンドユーザーを表す一意の識別子。OpenAI による不正行為の監視と検出に役立ちます。
Embeddingsを取得する方法
Embeddingsを取得するには、EmbeddingsのModel ID (例: text-embedding-ada-002) とともにテキスト文字列をAPI エンドポイントに送信します。レスポンスにEmbeddingsが含まれています。
response = openai.Embedding.create(
input="Your text string goes here",
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
Example response:
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
OpenAI クックブックでその他の Python コード例を参照してください。
OpenAI 埋め込みを使用する場合は、その制限とリスクに留意してください。
Embedding models
OpenAI は、1 つの第 2 世代埋め込みモデル (**-002モデル ID で で示されます) と 16 の第 1 世代モデル (-001**モデル ID で で示されます) を提供しま
す。
第 2 世代の埋め込みモデルtext-embedding-ada-002は、以前の 16 個の第 1 世代の埋め込みモデルを数分の 1 のコストで置き換えるように設計されています。
第1世代はもう使用を推奨されていないため、特別な理由がなければこのtext-embedding-ada-002を使いましょう。
ほぼすべてのユースケースで text-embedding-ada-002 を使用することをお勧めします。
より良く、より安く、より使いやすくなりました。

使用料金は入力トークンごとに設定され、1000 トークンあたり 0.0004 ドル、または 1 米ドルあたり約 3,000 ページになります (1 ページあたり約 800 トークンと仮定)。
第二世代モデル
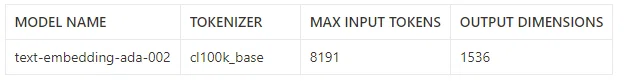
「text-embedding-ada-002」という第二世代のモデルの登場により、第一世代のモデルは非推奨になりました。
ユースケース
ここでは代表的な使用例をいくつか紹介します。次の例では、Amazon 高級食品レビュー データセットを使用します。
Amazon Fine Food Reviews | Kaggle
エンベディングの取得
このデータセットには、Amazon ユーザーが 2012 年 10 月までに残した合計 568,454 件の食品レビューが含まれています。説明のために、最新のレビュー 1,000 件のサブセットを使用します。レビューは英語で書かれており、肯定的または否定的な傾向があります。各レビューには、ProductId、UserId、スコア、レビュー タイトル (概要)、レビュー本文 (テキスト) があります。例えば:

レビュー概要とレビュー本文を 1 つの結合テキストに結合します。モデルは、この結合されたテキストをエンコードし、単一のベクトル埋め込みを出力します。
dataset.ipynb
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
保存したファイルからデータをロードするには、次のコマンドを実行します。
import pandas as pd
df = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)
制限とリスク
Embeddingsモデルは場合によっては社会的リスクを引き起こす可能性があり、緩和策がなければ損害を引き起こす可能性があります。
Social bias(社会的偏見)
制限: モデルは、特定のグループに対する固定観念や否定的な感情などを介して、社会的偏見をエンコードします。
SEAT ( May et al, 2019 ) および Winogender ( Rudinger et al, 2018 ) ベンチマークを実行することで、モデルにバイアスがある証拠を発見しました。これらのベンチマークは、男女別の名前、地域名、一部のステレオタイプに適用した場合にモデルに暗黙のバイアスが含まれているかどうかを測定する 7 つのテストで構成されています。
SEAT ( May et al, 2019 )
Winogender ( Rudinger et al, 2018 )
最近の出来事に対する知識
制限事項: モデルには、2020 年 8 月以降に発生したイベントに関する知識がありません。
2020 年 8 月までの実世界の出来事に関する情報を含むデータセットでトレーニングされています。最近のイベントを表すモデルに依存すると、適切なパフォーマンスが得られない可能性があります。
よくある質問
文字列を埋め込む前に、文字列に含まれるトークンの数を確認するにはどうすればよいですか?
Python では、OpenAI の tokenizer tiktokenを使用して文字列をトークンに分割できます。
Example code:
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
text-embedding-ada-002のような第 2 世代の埋め込みモデルの場合はcl100k_baseエンコーディングを使用します。
詳細とコード例は、tiktoken を使用してトークンをカウントする方法のOpenAI クックブック ガイドに記載されています。
K 個の最も近い埋め込みベクトルを迅速に取得するにはどうすればよいですか?
多数のベクトルをすばやく検索するには、ベクトル データベースを使用することをお勧めします。ベクトル データベースと OpenAI API の使用例は、 GitHub のクックブックで見つけることができます。
ベクター データベースのオプションには次のものがあります。
Chroma
、オープンソースの埋め込みストア
Milvus
、スケーラブルな類似性検索のために構築されたベクトル データベース
Pinecone
、フルマネージドのベクター データベース
Qdrant
、ベクトル検索エンジン
ベクトルデータベースとしてのRedis
Typesense
、高速オープンソース ベクトル検索
Weaviate
、オープンソースのベクトル検索エンジン
Zilliz
、データ インフラストラクチャ、Milvus を利用
どの距離関数を使用すればよいでしょうか?
コサイン類似度を推奨します。通常、距離関数の選択はあまり重要ではありません。
OpenAI のEmbeddingsは長さ 1 に正規化されます。これは次のことを意味します。
コサイン類似度は、ドット積のみを使用してわずかに高速に計算できます。
コサイン類似度とユークリッド距離により、同じランキングが得られます。
コサイン類似度とは?