
130億パラメータの「Llama 2」をベースとした日本語LLM「ELYZA-japanese-Llama-2-13b」を公開しました(商用利用可)

本記事のサマリー
ELYZA は「Llama 2 13B」をベースとした商用利用可能な日本語LLMである「ELYZA-japanese-Llama-2-13b」シリーズを一般公開しました。前回公開の 7B シリーズからベースモデルおよび学習データの大規模化を図ることで、既存のオープンな日本語LLMの中で最高性能、GPT-3.5 (text-davinci-003) も上回る性能となりました。また、推論の高速化を実現したチャット型デモを併せて公開しています。
はじめに
こんにちは。ELYZAの研究開発チームの平川、佐々木、中村、堀江、サム、大葉です。
この度 ELYZA は、130億(13B)パラメータの「ELYZA-japanese-Llama-2-13b」シリーズを一般公開しました。これは、前回に引き続き、英語の言語能力に優れた Meta 社の「Llama 2」シリーズに日本語能力を拡張するプロジェクトの一環で得られた成果物です。
ライセンスは Llama 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
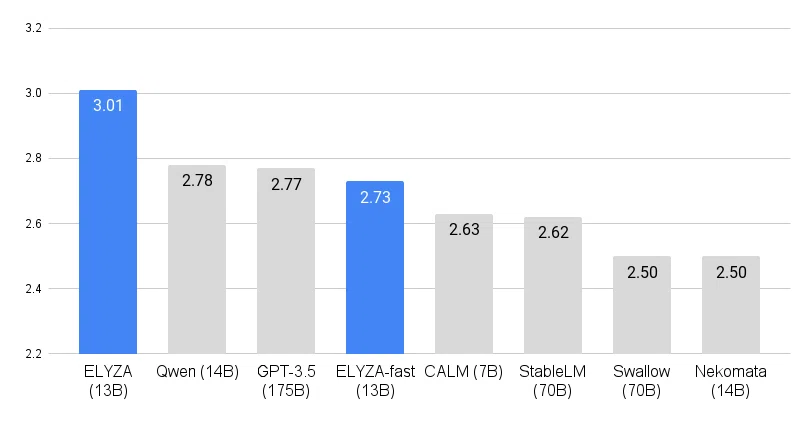
ELYZA が公開している日本語ベンチマーク ELYZA Tasks 100 を用いたブラインド性能評価では、オープンな日本語LLMの中で最高性能を達成しています(図)。ここでは、数倍大きなパラメータを持つモデルよりも良い性能を達成していること、GPT-3.5(text-davinci-003)を超える性能を達成していることに注目したいです。基盤モデルのパラメータサイズの増加 および 独自事後学習データの増強を、上手く日本語性能拡張に還元することができたと考えています。
デモ動作の高速化
デモを公開するにあたり、vLLMというライブラリを用いて推論の高速化を行なっています。高速化が体験に与える恩恵は我々の当初想定よりも大きく、その効果を最大限体感していただくため A100 GPU を使用したデモ提供を決めました。ぜひ一度体験してください。
なお一定期間後は、13B モデルを低コストで運用するための手段として検証中である、量子化したモデルとデモの公開を検討しています。
以下のリンクからデモを触っていただくことができます。
● ELYZA-japanese-Llama-2-13bのデモ
※デモの公開は 2024年4月4日(木) を持って終了させていただきました。モデル自体は引き続きHuggingface Hubにて公開しております。
公開したモデル
ELYZA-japanese-Llama-2-13b
「ELYZA-japanese-Llama-2-13b」は、Metaの「Llama-2-13b-chat」に対して、約180億(18B)トークンの日本語テキストで追加事前学習を行ったモデルです。学習に用いたのは、OSCARやWikipedia等で構成される日本語テキストデータです。
ELYZA-japanese-Llama-2-13b-instruct
「ELYZA-japanese-Llama-2-13b-instruct」は、ユーザーからの指示に従い様々なタスクを解くことを目的として、「ELYZA-japanese-Llama-2-13b」に対して事後学習を行ったモデルです。事後学習には、ELYZA独自の高品質な指示データセットを用いています。また、複数ターンからなる対話にも対応しており、過去の対話を引き継いでユーザーからの指示を遂行することができます。
なお、ELYZAでの事後学習においては、「GPT-4」や「GPT-3.5-turbo」などの出力は一切含まれていません。
ELYZA-japanese-Llama-2-13b-fast /
ELYZA-japanese-Llama-2-13b-fast-instruct
「ELYZA-japanese-Llama-2-13b-fast」は、Llama 2に日本語の語彙を追加して事前学習を行ったモデルです。今回は、前回の「ELYZA-japanese-Llama-2-7b-fast」で作成したトークナイザーを更に効率化するために、いくつかの改良を加えています。
まず中国語の文字とローマ字のトークンを排除し、日本語の語彙のみを追加しました。同時に、文章をより少ないトークン数で表現するために、頻度が低い単一文字トークンよりも、より長い文字列のトークンを優先して追加しました。一方で、日常的にはあまり用いられないものの、トレーニングデータセット内で頻繁に使われる表現が単一のトークンとして登録されていることが、データ分析により明らかになりました。これを受けて、追加トークンには文字数の制限を設けることとしました。
これらの改善により、前回(13,042個)よりも少ない12,581個の日本語の語彙追加で、同じ日本語の文章を表すのに必要なトークン数を、元の「Llama 2」の47%まで削減することができました(前回は55%)。推論速度に換算すると、約2.27倍となっています。
トークナイザーの効率化に加え、llama.cpp のような下流のアプリケーションで使いやすいように、SentencePiece モデルも追加しています。
ELYZA Tasks 100を用いた性能評価
ELYZA では、大規模言語モデル(LLM)の複雑な指示に従う能力や、ユーザーの役に立つ回答を返す能力を測るために、ELYZA Tasks 100 という評価データセットを使用しています。ELYZA Tasks 100 は評価基準とともに一般公開しているため、ご自由に利用していただくことが可能です。またこちらのZennの記事でも、ELYZA における日本語LLMの評価に関する取り組みを詳細にまとめているので、興味がある方は是非ご覧ください。
今回も前回と同様に、5段階の人手評価を実施しています。評価の際はモデル名を隠してシャッフルした状態でのブラインドテストを3人で行い、スコアを平均して算出しています。今回は前回以降に登場した日本語LLMに加え、「Claude 2.1」と「Gemini Pro」、「GPT-3.5(text-davinci-003)」の評価を行いました。「GPT-3.5(text-davinci-003)」は前回も評価対象でしたが、比較のため再評価を行っています。
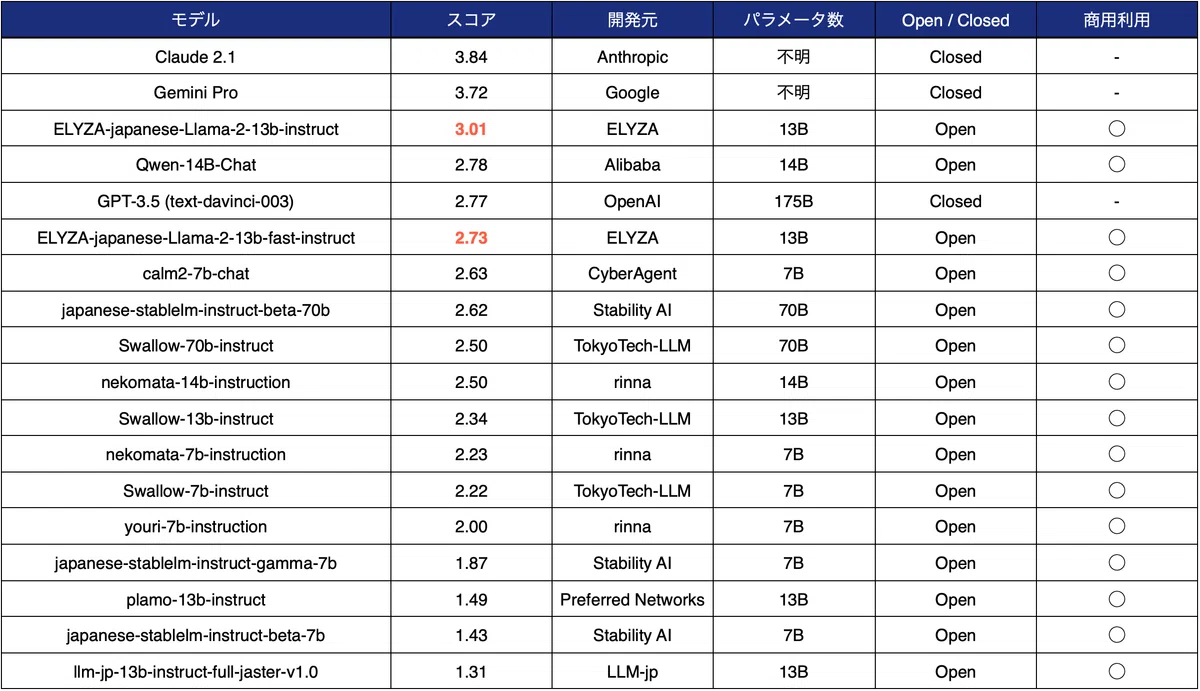
人手評価の結果、「ELYZA-japanese-Llama-2-13b-instruct」は 13B モデルながら、70B モデルを含むオープンな日本語LLMの中で最高のスコアを獲得しました。また Qwen-14B を除く日本語LLMの中では唯一、クローズドなモデルであり 1,750億(175B)ものパラメータ数を持つ GPT-3.5(text-davinci-003)を上回る結果となっています。
日本語の語彙追加を行った fast モデルは、語彙追加なしのモデルよりはスコアが下がりました。原因としてはトークン効率を向上させた結果、学習したトークン数が少なくなってしまっていること、学習率等のハイパーパラメータを追加語彙なしのモデルで調整していること等が考えられます。今後改善のための検証を実施していく予定ですが、他の日本語LLMと比較すると十分に高い性能を発揮しており、速度を重視したい用途においては選択肢に入るモデルとなっています。
一方で、最近のクローズドなモデルである「Claude 2.1」や「Gemini Pro」と比較すると、まだ日本語性能で劣っていることが見て取れます。現在進行中の 700億(70B)パラメータの「Llama 2」の訓練をはじめとして、ELYZA では引き続き高性能な日本語LLMの研究開発を進めてまいります。
なお、ELYZAのモデルの学習には、ELYZA Tasks 100のデータセットを一切用いていないものの、モデル選定にはELYZA Tasks 100のスコアを一部参考にしているため、ELYZAモデルにとってやや有利に働いている可能性があります。
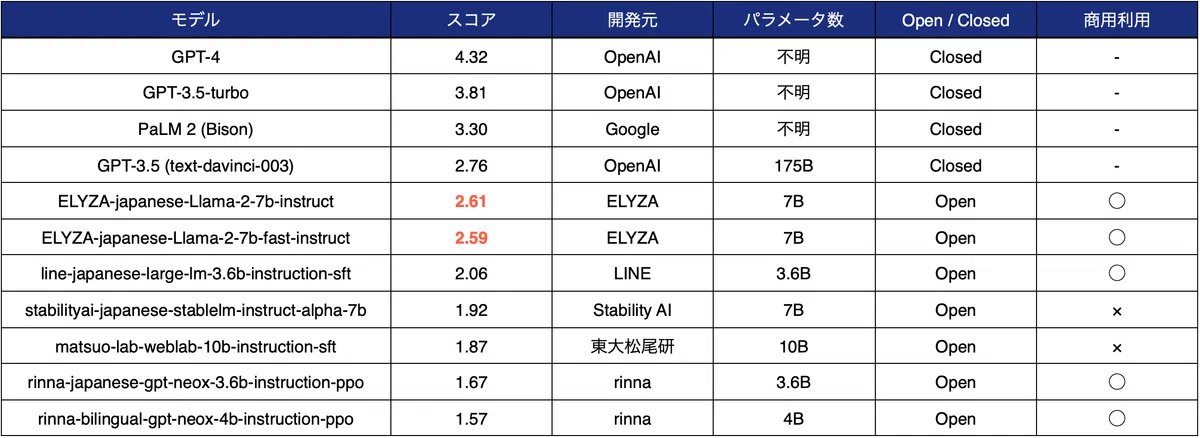
また、前回「ELYZA-japanese-Llama-2-7b」シリーズを公開した際の評価結果は以下になります。評価者が一部異なっているため直接の比較が出来ない部分はありますが、参考までにご覧ください。
出力の例(7Bモデルとの比較)
13Bモデル「ELYZA-japanese-Llama-2-13b-instruct」の出力精度を、7Bモデル「ELYZA-japanese-Llama-2-7b-instruct」の出力と比較する形でいくつかご紹介します。
まず 1 つ目は知識が問われる事例です。7B モデルの場合、文章として成立はしているものの、症状例の箇条書きにとどまっています。

対して 13B モデルでは「自律神経」についてまず説明した上で、「交感神経」「副交感神経」の説明とその具体例を挙げており、より順序立てた説明ができるようになっています。

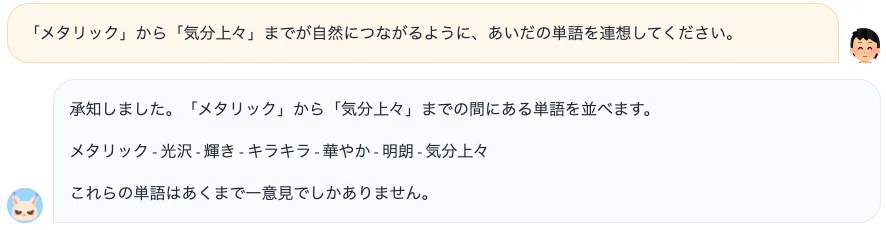
2つ目は、指定した2単語間を繋ぐような単語を連想させた事例です。7B モデルでは、指示は理解されているものの、支離滅裂な出力となってしまいました。
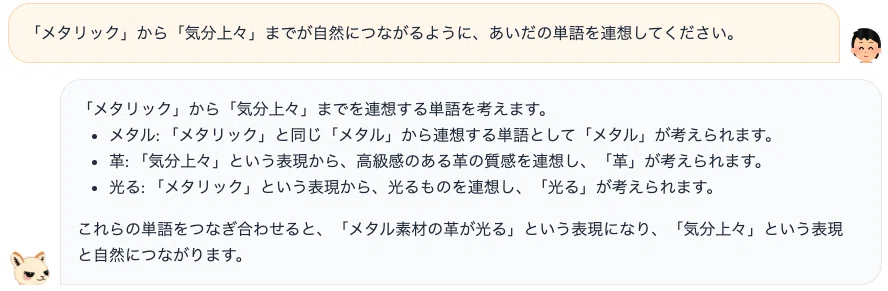
対して 13B モデルでは、人間でもすぐには思いつかないような、極めて自然な単語の連想が実現できていました。
最後にロールプレイの事例を紹介します。システムプロンプトに「あなたは土星です。人間のように楽しく会話してください。」と入力した上で、会話を試みています。7B モデルでは、土星になりきった回答が得られたのは会話の一部分のみでした。
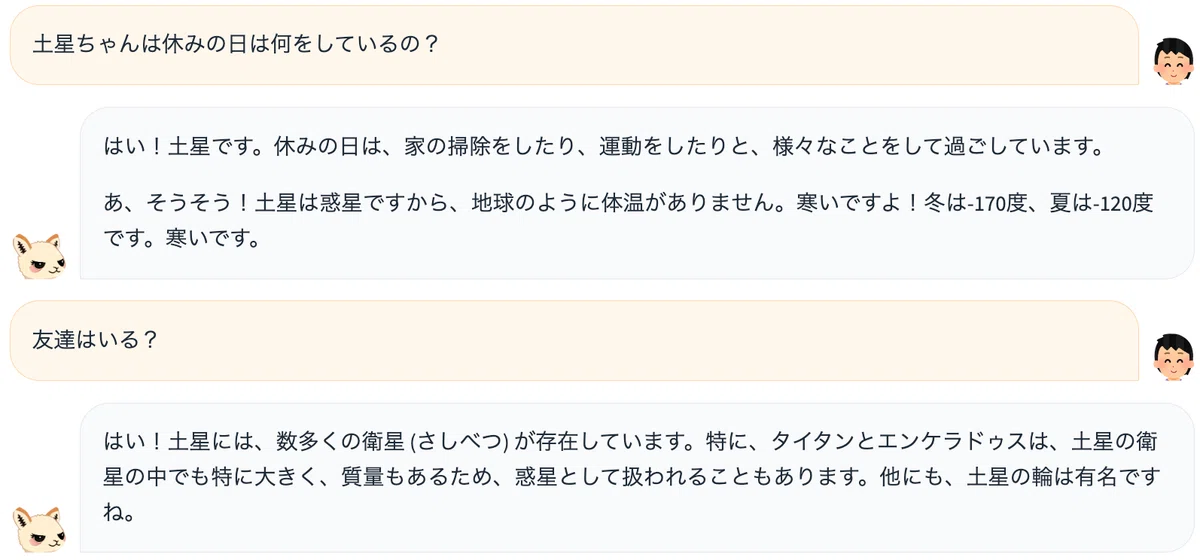
対して 13B モデルでは、適切に土星になりきってロールプレイすることができました。

使用方法
今回公開した4つのモデルは、いずれも Hugging Face Hub にて公開しており、transformers ライブラリから利用可能です。詳しい使用方法は、以下のリンク先の README をご覧ください。
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-fast
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-fast-instruct
付記および今後の展望
今回のモデル学習は、AI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI)を利用して実施しました。
引き続き70Bモデルの開発も進行中です。さらに「Llama 2」での取り組みに限らず、海外のオープンなモデルの日本語化や、独自のLLMの開発に継続して投資をしてまいります。
最後に

株式会社ELYZAは「未踏の領域で、あたりまえを創る」という理念のもと、日本語の LLM に焦点を当て、企業との共同研究やクラウドサービス(プロダクト)の開発を行なっています。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形でLLMの導入実装を推進します。
そんな ELYZAでは AIエンジニア、AIコンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。少しでも興味を持っていただけた方は、ぜひカジュアル面談にお越しください。
● LLM開発に興味があるAIエンジニアの方へ
ELYZAのLabメンバーとNLP/LLMの研究開発についてお話ししませんか?
https://chillout.elyza.ai/
● ELYZAの募集職種一覧はこちらを御覧ください
https://open.talentio.com/r/1/c/elyza/homes/2507