
【ほぼ全文】「LLM開発はPost-trainingがカギとなる」ELYZA曽根岡がLLMの現状・課題・展望を解説

【Profile】
曽根岡 侑也 Soneoka Yuya/1990年東京都生まれ。2013年に東京大学 工学部システム創成学科卒業。2017年東京大学大学院工学系研究科技術経営戦略 学専攻修士課程修了。2018年に株式会社ELYZAを創業。「未踏の領域で、あたりまえを創る」というミッションを掲げ、 自然言語処理に焦点を当てて研究開発と社会実装を行う。株式会社松尾研究所取締役も兼任。
全スライドをこちらからご覧いただけます。
※編集注
・本記事は2023年7月13日に行われた勉強会の書き起こしです。
・言語生成AI、大規模言語モデルなどを記事中は「LLM」で統一します。
・企業様の名称は敬称略としてご了承ください。
ChatGPT登場までの歴史と今後の進化
ELYZAの紹介
私たち株式会社ELYZAは、東京大学の松尾研究室発のAIスタートアップです。創業以来、自然言語を扱うAIを専門にしてきました。中でもLLM(大規模言語モデル)という技術に注力しております。

2020年には日本語特化の独自LLMを開発し人間を超える精度を実現しました。要約するAIやキーワードから自然な文章を執筆するAIなどを公開し、多くの方々にご利用いただいています。
事業としては企業様のDXの流れに沿ってLLMを社会実装するプロジェクト、および各社固有の独自モデルを作るための研究開発プロジェクト双方に力を入れています。

社会実装として例えば、JR西日本グループ様とコンタクトセンター業務の一部自動化に取り組み、対応時間を約34%削減することができました。マイナビ様とは求人原稿作成のAI化に取り組み、業務時間を約30%効率化することができました。
研究開発としては、各企業様専用のLLMを作りたいというニーズの高まりを受けて、LLM開発の支援プログラムを提供開始しています。本日の勉強会の最後にご紹介させてください。
現在、何が起きているのか?
OpenAIのChatGPTは2022年の11月30日に公開され、大変なブームとなりました。2023年3月には新モデルであるGPT-4が公開され、さらに精度が向上しました。テックジャイアントであるGAFAMらがそれぞれ追従し、大きなトレンドとなっています。

MicrosoftはOpenAIのモデルを採用し、大手企業向けにAzure上で提供を開始しています。

Googleも同様に独自LLMのAPIを提供開始し、GmailやGoogleスライドなどの製品に組み込もうとしています。

AmazonはAWS上でLLMの提供を進めています。Meta(旧Facebook)は他のプレイヤーと毛色が違う動きをしており、自社のモデルをクローズドに提供するのではなく、研究者が利用可能なようにモデルを公開していく(※)方向で進んでいます。これが第三勢力の動きを加速する大きな要因となっています。
※編集注:2023年7月19日、Metaは商用利用可能なモデルとして「Llama 2」を無償で提供開始しました。
LLM登場までの歩み
これらLLM(大規模言語モデル)と呼ばれるものがどのような技術トレンドから生まれてきたのか、その歴史を紐解いて説明します。

実はこの技術は4年ないし5年前から登場しています。当時もディープラーニングが非常に注目を浴びていましたが、その主な対象は画像認識や音声認識で、自然言語を対象にしたAI技術は未成熟でした。

それまで最も優秀だとされたモデルでも、人間が87.1点を取れるタスクで65.6点しか出せませんでした。そのため限定的な領域でしか実用に至りませんでした。
しかし2018年にLLMが登場し、精度は一気に80.2点へジャンプアップ。その8ヶ月後には人間の精度を超えてしまいました。

LLMはディープラーニングを用いて構築されたモデルの一種で、大量のテキストデータを学習させた、パラメータ数(脳の大きさようのうなもの)が非常に大きなものとなっています。
LLMが登場するまでは、例えば要約タスクを解かせる場合、何も学習していないモデルに数万件の要約データセットをそのまま学習させるというやり方をしていました(左図:従来の言語AI)。日本語の知識が全くない人に、日本の大学入試の赤本を与えて勉強させるようなやり方です。
LLMを用いる場合は、まず言語を学習させます。日本語のモデルであれば日本語の文章を大量に読み込ませ、日本語の語彙や文法、一般常識的な知識を学習させます。その後、特定のタスク(例えば要約や分類)に対して、そのタスクに適した学習データを用いて追加の学習を行うのです。
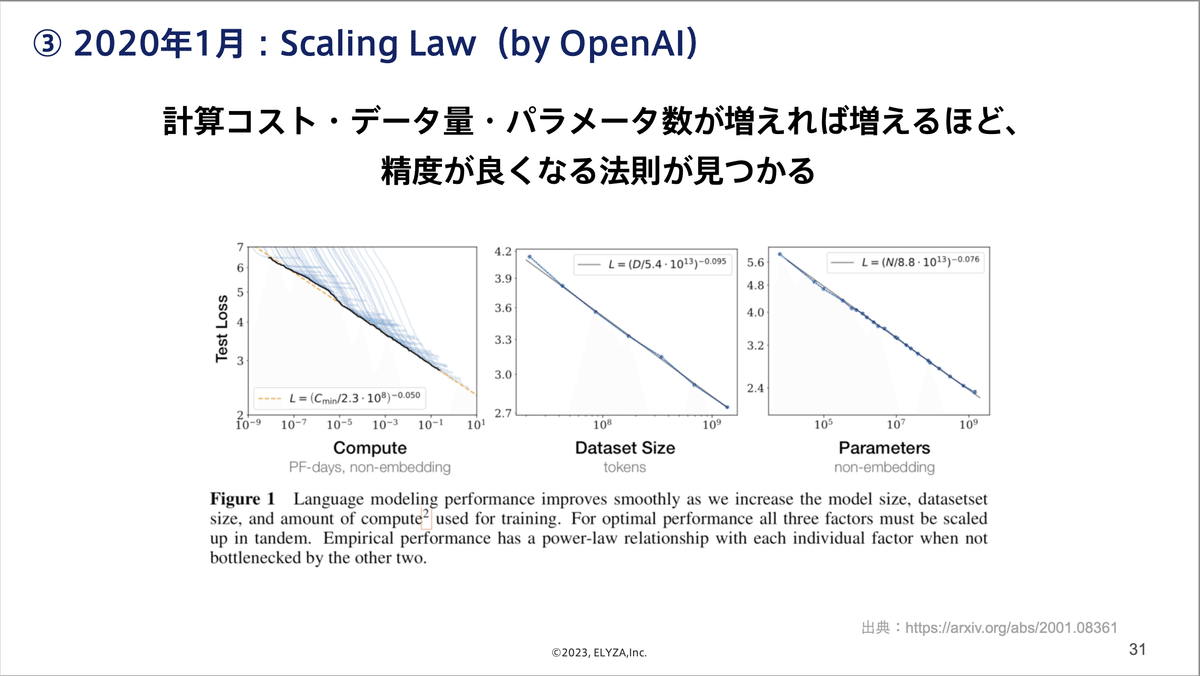
さらにOpenAIが2020年にスケーリング則(scaling law)という驚くべき法則を発表しました。学習量、データ量、パラメータ数を大きくすればするほどAIが賢くなるというものです。彼らはそのスケーリング則を前提に、GPT-3という巨大なモデルを約15億円かけて作成しました。

このモデルでは、文章を途中まで与え、その続きを書かせるという学習手法が採用されます。次に来る単語を予想するだけのモデルですが、0〜数件のデータを与えるだけで、様々なタスクで一定の精度が出せることが当時の研究界隈で話題となりました。

そこからは世界中で大規模なモデルの開発が始まりました。OpenAIだけではなくGoogleやLINE、中国政府が支援する研究機関なども含まれています。その中で抜け出したのがやはりOpenAIのChatGPTでした。
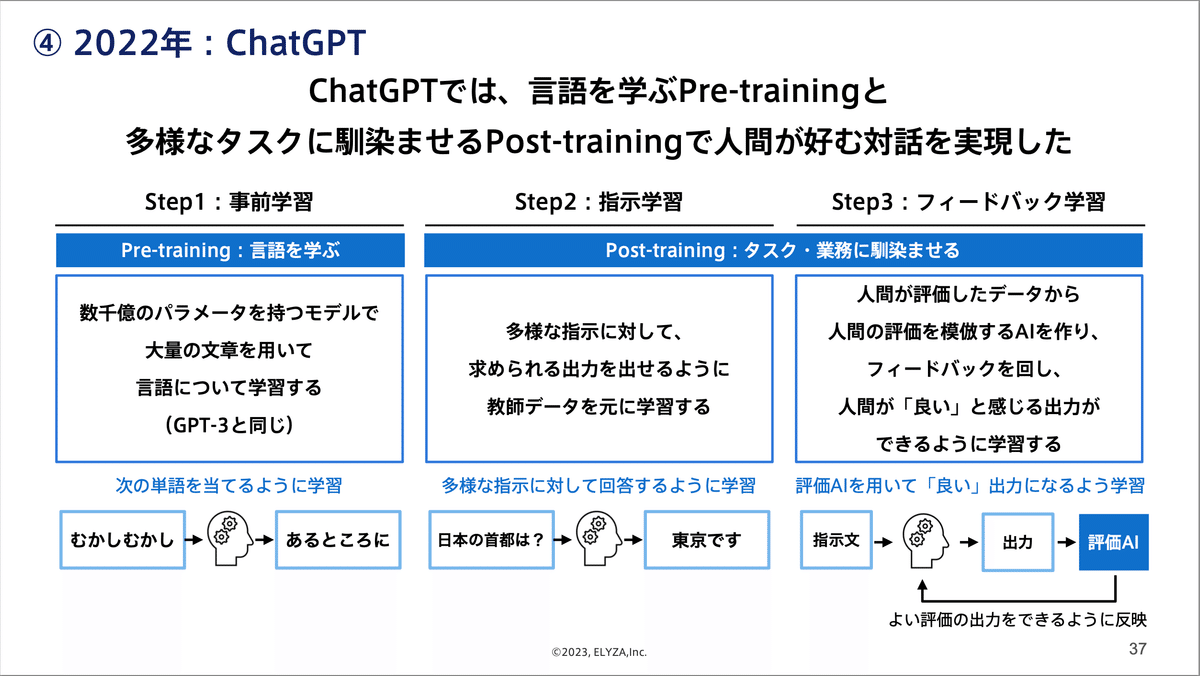
ChatGPTの革新性は、学習データを一切加えなくても多様なタスクに対して高精度な出力ができるところです。これを実現可能にした重要な技術がPost-trainingになります。
LLMは大きく3つの学習ステップを踏みます。最初のステップは事前学習あるいはPre-trainingと呼ばれます。先ほどご説明した、大量の文章を読み込ませ、次の単語を予測させ続けるというものです。語彙や文法、一般常識的な知識を学ぶ段階です。
OpenAIが採用したPost-trainingはステップ2と3に位置します。言語や知識を学んだAIに、特定の入力や出力結果を学ばせ、タスクに適応させていくプロセスです。
ステップ2では、AIに出したい多様な指示データを集め、それに対する回答を学習させていきます。具体的には「日本の首都は何ですか?」や「この文章を要約してください」という指示に対する回答を数万件用意し、それを学習させます。
ステップ3のフィードバック学習では、ある程度指示に従って回答できるようになったAIに、さらなる出力内容の改善を加えます。AIが出力した結果に対して人間が評価をつけ、それに基づいて品質を改善していきます。

これらを地道に研究開発した結果として、ChatGPTは非常に性能の高いモデルとなり、多くの人々に衝撃を与えました。
LLM、今後の進化
技術は今後も進化し続けます。まず、言語だけでなく画像も扱えるようになるマルチモーダル化が一層進むと思われます。次にウェブアプリケーションを操作できるAIも普及していきそうです。

例えば元OpenAIのメンバーによってつくられたAdeptというスタートアップが、AIがウェブブラウザを自動操作するデモ動画を公開しています。指定した条件に沿ってAIが自動的に不動産サイトを操作して家を探してくれています。その他、SalesforceやGoogleスプレッドシートの操作も例に挙げられています。

さらに、物理世界での行動を可能にするAIの研究も進行中です。Googleの研究によると、人間の曖昧な指示をLLMが具体化し、その具体化された指示に従ってロボットが行動する、ということが一定可能になってきています。
LLMを取り巻く動き:DXとR&D

LLMを取り巻く主要なトレンド
ChatGPTなどLLMに社会全体からの注目が集まる中で、DXの文脈でいち早く社会実装を目指す動きと、R&Dで自社独自モデルを開発しようとする研究開発強化の動きが顕著となっています。
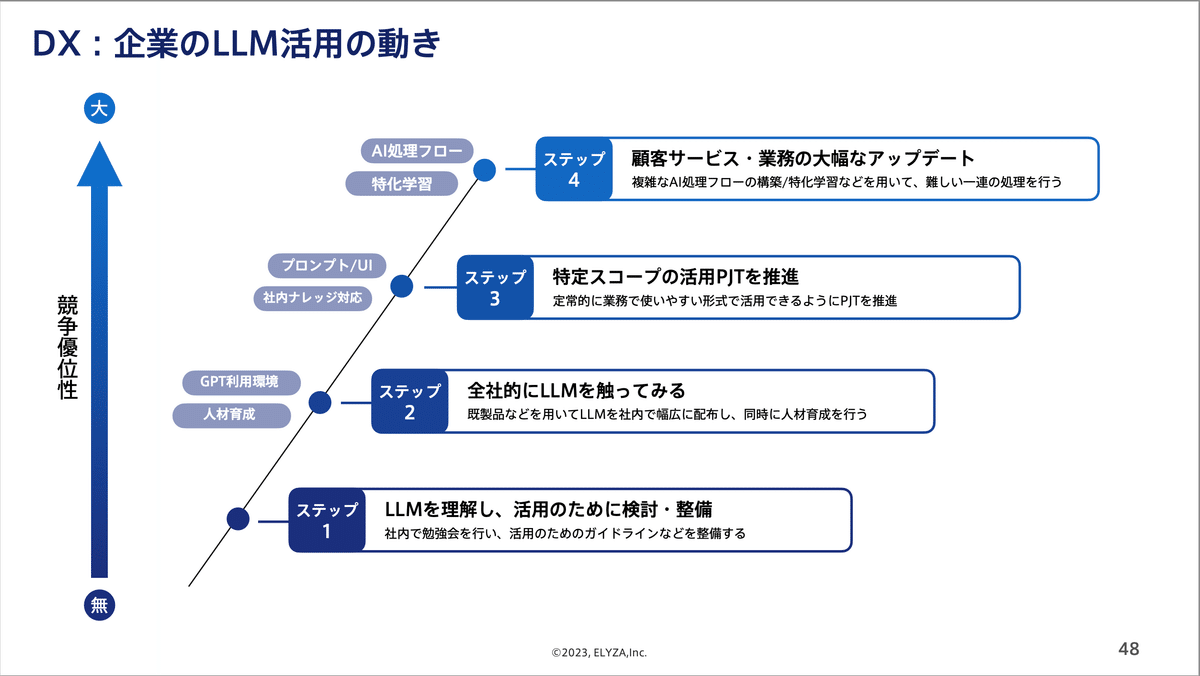
まずDXについて、企業のLLM活用の動きを4つのステップで表すと、全社員がGPT等を利用できる環境を整備し、ガイドライン策定や勉強会を行っていくことがステップ1。全社的にLLMを触ってみてLLMへの解像度を高め、活用シーンを探索していくのがステップ2です。ステップ3では自社業務の特定タスクで本格的に実用化を進めていきます。ステップ4では業務全体を大幅に見直すLLM活用や、顧客向けサービスの革新を目指していきます。

これを別の図にして、横軸にLLM利用者数、縦軸に課題解決量を置いた場合、横向きに広げていく活動がステップ2に当たります。縦向きに課題の解決量を増やす動きがステップ3、4です。

例えばパナソニックコネクトは従業員1万2,500名にGPT利用環境を提供しています。企業向けにGPT利用環境を提供するベンダーの動きも盛り上がっています。

大手企業では専門組織を立ち上げ、人材育成にも力を入れ始めています。日立製作所は『Generative AIセンター』を新設、コクヨはデジタル人材を育てる『KOKUYO DIGITAL ACADEMY』を発足させています。

次に縦向き、特定タスクで本格実用を進めていく動きがステップ3と4です。例えば、メルセデスベンツでは音声認識を用いたカーナビゲーションサービスにGPTを組み込み、さらに詳細な情報の提供に活用しています。ELYZAのご支援事例として冒頭に紹介した、マイナビ様の事例もここに該当します。

今後ニーズが高いユースケースは、AIが多様かつ膨大な社内ドキュメントを参照しながら対話に応えるというもので、技術的にはRAG(Retrieval Augmented Generation)と言われるものだと思います。Microsoftも『Add your data』という機能を提供し始めていますが、このニーズに対して各企業がどう対応していくかは注目です。私たちも対応していきます。

ステップ4になるとまだほとんどが水面下で、今後は「試み始めました」というようなニュースが増えてくると思います。ELYZAが支援するJR西日本グループ様のコンタクトセンターでは、ひとつの業務を置き換えるのではなく、業務全体のフローを再構築する動きが実際に起きているところです。
LLMを活用しDXを進めるための留意点

次に、DXを進める上での留意点という観点から見ると、A.コスト構造、B.模倣容易性、C.利用量制限、D.セキュリティの4つに注目すると良いと思います。

まずコスト構造ですが、売上の相当割合がGPTのAPI利用料金やクラウドインフラの利用料金として消費されるという構造になっています。模倣容易性はそのままの意味で、ほぼ全ての企業が同じAIモデルを利用するので、模倣されやすい構造になっています。

利用量には厳しい制限が存在します。これについては後ほど詳しく説明します。最後のセキュリティも大きなブロッカーとなっています。機密情報や個人情報を海外サーバーに送るのは怖いと感じている企業様が多いです。ただしMicrosoftが日本国内でサーバー展開を開始する可能性は高い(※)ので、近いうちに解決するかもしれません。
※編集注:2023年7月末、正式に東日本拠点の開設が発表され、Azure OpenAI Service を利用する場合は、海外通信なしでGPTを利用できるようになっています。
利用量制限についての補足ですが、LLMを動かすために必要な演算装置である、GPUの不足が深刻化しています。そのため利用量に制限を設けざるを得ません。Azure OpenAI Serviceの場合、ChatGPTは1分間に24万トークン、1秒あたり4,000トークンまでしか扱うことができません(※)。日本語の場合1文字あたり1〜3トークン程度なので、2,000文字の文章を要約しようとすると秒間1〜2回しか使えない計算になり、多くの一般ユーザーが利用するサービスを展開するのは難しくなります。
※編集注:2023年7月13日時点。最新情報は公式ページでご確認ください。
R&D、独自LLM開発の流れ

一方、R&Dの流れも非常に活発化しており、特定ドメインや業界特有のタスクに特化したモデル開発が進んでいます。例えばBloombergは金融向け、Googleは医療向けに特化したモデルの開発を独自に行っています。

個人情報など機密性の高い情報を扱うケース、業界専門用語が多いドメインでは独自LLMの需要が高くなると思います。金融や医療はまさに、ですね。

また、OpenAIに依存する状況から脱し、各企業が独自のLLM作成に取り組むケースも増えてきています。日本国内の通信キャリアであるソフトバンクとNTTはそれぞれ自社のモデルを作成すると発表しています。

リコー、NEC、富士通などがその動きを先導しています。情報通信研究機構などの研究機関でも、GPT-3よりも大きなパラメータ数のモデルの開発を目指しています。
独自LLM開発のカギとなるPost-training
自社LLMを開発する際の選択肢

このR&Dの流れを受けて、弊社ELYZAでも企業各社の独自LLM開発を支援するプログラムを開始します。LLM開発には選択肢が2つあります。1つ目は、フルスクラッチで事前学習(Pre-training)からPost-trainingまで独自で行う方法。2つ目は既に公開されている商用利用可能なモデルを利用し、Post-trainingのみを行う方法です。

私たちが提供する支援プログラムは、図にあるオプション2の方で、Post-trainingのノウハウや環境構築を提供するものです。その理由としてはまず、事前学習済みのモデルが公開されるトレンドが起きていることが挙げられます。また、フルスクラッチ開発に比べて費用を大幅に抑えることもできます。

そして、先にPost-trainingこそがOpenAIの大きな研究成果だったと述べた通り、モデルサイズが小さくてもPost-training次第で巨大なモデルと同程度の精度が出る事例がいくつか出てきています。弊社内の実験でも同様の事例が出ており、一定証明もされています。

ELYZAの独自LLM開発支援プログラム
私たちは商用利用可能な事前学習済モデルに対してPost-trainingを行う基盤を既に保有しています。まずはこれらを各企業に提供します。その上で、各企業に特化したPost-trainingを行うためのデータ基盤を一緒に構築し、企業独自モデル開発の基盤とする支援を行います。

先述のように、事前学習済みモデルが公開される流れがある中で、より精度の高いモデルを都度、独自LLM開発に取り込んでいく必要があると考えています。
ELYZAが保有するPost-Training基盤と各社独自のPost-Training基盤があれば、業界特有のタスクに強い独自LLMを継続的に開発できます。私たちのこの支援プログラムが、LLMの社会実装を早め、企業様の競争優位性にもつながることを確信しています。
最後までご視聴いただき、ありがとうございました。
ここまで読んでいただき、ありがとうございます。
役に立ったと思った方はぜひ「スキ」やシェアをいただけると嬉しいです。
こちらもぜひ👉 ELYZA 公式サイト /ELYZA 求人募集一覧