
『ELYZA Lab』は何を目指すのか。研究開発を担う Lab チームの想いとは?

こんにちは、株式会社ELYZA CTOの垣内です!今回の記事では、改めてELYZAの研究開発チーム(ELYZA Lab)の活動や今後の展望についてご紹介します!

ELYZA について
ELYZAは「未踏の領域で、あたりまえを創る」をミッションとして日々活動をしています。先端技術を探索し、未踏の領域での社会実装を行うことで、次の「あたりまえ」になる革新的なプロダクトを生み出し続けることを目指しています。
先端技術は常に新たな体験を生み出し、世界に革新をもたらしてきました。エンジン技術が馬車の時代を変えたように、技術は歴史を創ります。私たちはこの技術の力を深く信じ、先端技術を駆使して未踏の領域へ挑戦していきたいと考えています。
具体的なチャレンジとしては創業当初より大規模言語モデル(以下、LLM)領域に投資をし続けており、LLM の実用化を通じた業務変革・価値創出に挑戦しています。
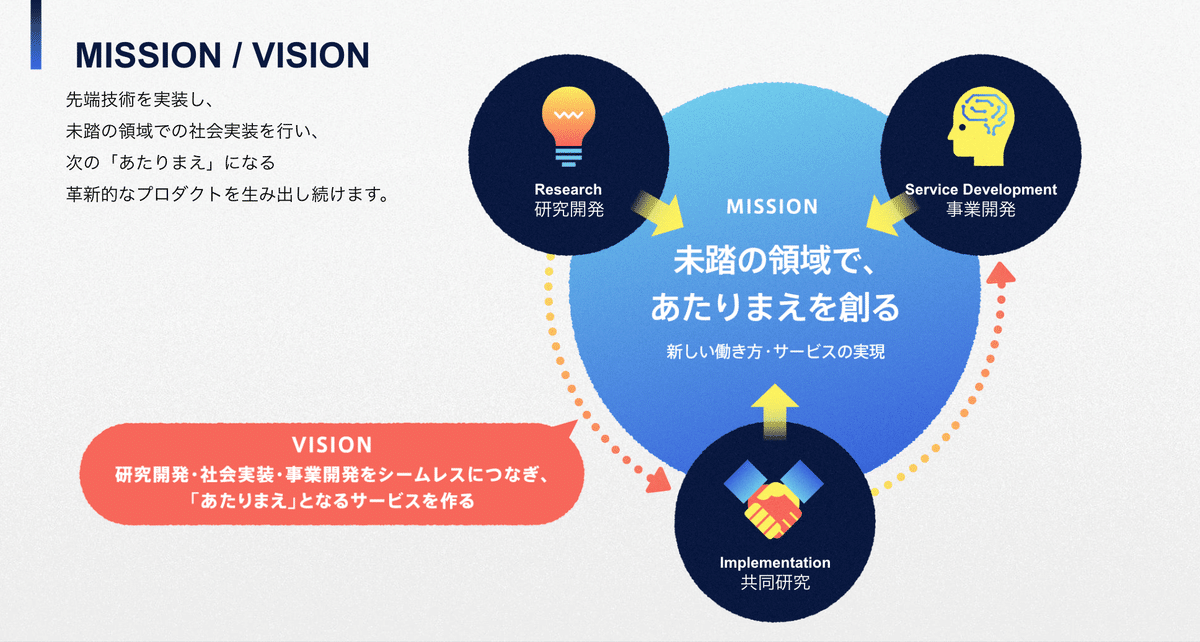
このミッションに向かっていくためには、常に先端技術を検証し、実用化の道を探求することが不可欠です。この役割を担うのが ELYZA Lab です。この活動はELYZAの競争力の源泉であり、ELYZAが社会に与える影響力を占う重要な存在だと自負しています。
ELYZA Lab とは?
ELYZA Lab の活動指針
ELYZA Lab では、ELYZAの中長期の事業に資する研究開発を行っています。この中で重要なことは、論文執筆や研究自体が主目的になるのではなく、「技術の価値は、社会実装し還元されてこそ」という考え方です。
もちろん対外発表やコミュニティ貢献は重要ですし、ELYZAでは実際にLLMに関するモデルや評価データの公開、ノウハウの共有、学会や勉強会へのスポンサードを積極的に行ってきています。
ただ目的はあくまでも、技術が社会に実装され大きなインパクトを生むこと、そしてELYZAのプロダクトや事業を大きく成長させることです。そのためには何をすべきか?という意識を持って、1〜2年後を見据えた意思決定や開発を心がけています。
ELYZA Lab が何をやってきたのか
ELYZA Labがこれまでやっていたことを簡単にご紹介します。
■ ELYZA Brain(2020年)
当時日本最大規模のBERTベースのアーキテクチャのLLMを開発しました。
https://brain.elyza.ai/
■ ELYZA DIGEST(2021年)
要約に特化した LLM を開発し、デモサイトを公開しました。 公開 5 日で 13 万人に利用されるなど、大きな反響をいただきました。https://www.digest.elyza.ai/
■ ELYZA Pencil(2022年)
文章執筆(メール・ニュース記事・職務経歴書)に特化した LLM を開発し、デモサイトを公開しました。 公開 11 日間で 11 万人に利用され、こちらも大きな反響をいただきました。
https://www.pencil.elyza.ai/
■ ELYZA-japanese-Llama-2シリーズ(2023年)
Meta社の Llama 2 シリーズに対して、追加事前学習と独自データでの事後学習を実施し、日本語化する取り組みです。7Bモデル、13Bモデル、Code Llama 7B モデルを日本語化し、商用利用可能な形で一般公開しています。また、モデルと同時に ELYZA Tasks 100 という評価用データセットや、その評価過程を記したスプレッドシートも公開しました。
現在は70Bモデルの開発を進めており、グローバルレベルのLLMをつくるための取り組みに注力しています。
このように、ELYZA Lab では創業当初より LLM に関する研究開発を進めてきました。その成果として重要なことは、これらの開発したモデルや得られた知見をもとに、実際に社会実装を進めて価値創出までつなげている点です。
ELYZA DIGEST をベースとした要約サービスは、複数の大手企業に対して導入が進んでいます。例えば、JR西日本グループ様のコールセンターでは現場目線でAI要約の90%以上が有用と評価され、オペレーターや管理者の負担軽減効果が実証されました。

また、ELYZA Pencil をベースとしてマイナビ様と開発した求人原稿執筆サービスは、約30%の業務効率化が実証されています。

ELYZA-japanese-Llama-2 シリーズとして公開したモデルも多くの方にご利用いただき、様々なアプリケーションに組み込まれています。ELYZA自身も顧客企業向けの独自LLM開発支援プログラムなどで活用しています。
このように、ELYZA Lab の活動は「未踏の領域で、あたりまえを創る」ための礎になっています。
ELYZA Lab が大切にしている考え方
ELYZA Lab が活動する上で大切にしている考え方を2つご紹介します。
1つ目は、Long Term Greedy に、ゼロベースで考えることです。
Long Term Greedy である
Long Term Greedyとは、目先にとらわれず、より長期的な視点で最適化を考えようという、ELYZAの Core Value(価値観) です。ELYZA Lab においても 常識にとらわれ過ぎることなく、Long Term Greedy に考えることを大切にしています。

例えば ChatGPT が登場して以降の1年間、ELYZA Lab では、LLM をゼロから開発するのではなく、SFT や RLHF などの Post-training に注力した研究開発を行ってきました。海外のモデル公開の流れや、多くのプレイヤーが事前学習から LLM 開発に取り組んでいる状況を踏まえて、既存のモデルをチューニングして性能を上げたりコントロールするためのデータ作成に集中する戦略をとったためです。
これは ChatGPT 登場直後、錯綜する様々な情報に惑わされることなく、長期的な視点でELYZAとしてどのような取り組みをしていくべきかをチームで考えた結果です。その決定の軸はやはり、LLM の社会実装を進めるためには?ELYZAの技術優位性を築くには?という問いでした。
ELYZAでは、元々LLMにおけるデータの重要性を感じており、2022年頭にデータ作成専任チーム(Data Factory)を組成していました。この1年はその Data Factory を中心に Post-training に必要なデータを作成し、フィードバックを受けて改善することを繰り返してきました。その結果が ELYZA-japanese-Llama-2 シリーズをはじめとする、ELYZAの LLM 開発につながっています。
仮説検証で自分たちだけの学びを得る
大切にしていることの2つ目は、自ら考え、仮説検証をどんどん回していくことです。
もちろん論文などから先行事例を学ぶことも非常に重要ですし、社内でも「ML Night」という論文輪読会を定期開催しています。一方、全ての前提条件が揃うことは稀ですし、論文に全てが書いてあるわけでもありません。自分が信じる仮説があれば、手を動かしてどんどん検証し、自分たちだけの学びを高速に蓄積していくことが大切だと考えています。
ELYZAのミッションを達成するためには、常識にとらわれない仮説を打ち立て、検証を回していくことも必要です。ELYZA Lab では、方向性は全員ですり合わせつつも、各自が裁量を持って仮説検証を回しています。
モデルや評価データセット公開についての想い
既に述べた通り、2023年に ELYZA-japanese-Llama-2 シリーズや ELYZA Tasks 100 などのモデルやデータセットを立て続けに一般公開しました。
この背景にあるのは、僕を含めたELYZAのメンバーは、この生成AI・LLMの技術が社会に本当に大きなインパクトを与えるものだと信じており、だからこそ、社会全体で昨今のムーブメントをしっかりと価値につなげたい、という想いです。
モデルやノウハウを公開した理由
ELYZAはもちろん急成長を志す営利企業であり、会社の取り組みの全てを公開するということは難しいです。一方、現在の日本の LLM技術開発はグローバルで見ると大きく遅れをとっている状態であり、資金や言語リソースの面でもその遅れを取り戻すのは簡単では無いと感じています。この状況で、例えばみんながゼロから事前学習をしてモデルをつくろうとしていたら、日本語モデルにユーザーが期待を感じるのはまだまだ先になってしまいます。
まずは日本でも LLM の開発や社会実装がどんどん進み、社会全体の取り組みが広がって欲しい。そのような想いから、特に英語の公開モデルを日本語化することで、高性能な日本語 LLM をつくることができるという実績やノウハウの公開を進めてきました。その上で、ELYZA独自の優位性を持って、今後のLLM開発を進めて行ければと考えています。
評価用データセットの公開に寄せた想い
ELYZAが汎用モデルを開発する際には、様々な種類の指示に従い柔軟な回答ができるモデルを目指していますし、この能力が重要であると考えています。一方、既存の評価データセットでは、基礎的な幾つかのタスクを解く能力や知識などが問われており、汎用能力を評価するのには適していませんでした。
このような背景から、ELYZA内部では以前から LLM の性能を評価する独自の評価指標(ELYZA Tasks 100)を用いていました。評価指標は研究開発の方向性や目的を反映するものであり、非常に重要です。
もちろんこのデータセットでの評価が完璧だとは全く思っていません。しかし僕たちなりの考え方を発信することで、議論が生まれ、みんなでより良い形を模索していけるのではないかと考え、評価データセット及びその評価過程を詳細に公開しています。ELYZAのリリースに対しては、どしどしとフィードバックをいただけると嬉しいです。
最後に

ELYZAは、この生成AI・LLM 時代のリーディングカンパニーになるべく日々奮闘しています。そして、ELYZA Lab はそれを推し進めるエンジンとして、ミッションを達成するための研究開発を進めていきます。
取り組みたいことは山積みですが、メンバーがまだまだ足りていません。僕たちの取り組みに少しでも興味を持ってくださった方、考え方に共感してくださった方がいれば、ぜひ気軽にお話しさせてください!一緒に先端技術で新しい体験をつくっていきましょう!!
● LLM開発に興味があるAIエンジニアの方へ
ELYZA Lab メンバーとNLP / LLMの研究開発についてお話ししませんか?
https://chillout.elyza.ai/
● ELYZAの募集一覧はこちらを御覧ください
https://open.talentio.com/r/1/c/elyza/homes/2507