brother標準プリンター(DCP-J928N)で両面スキャンPDF化

両面スキャンには対応していない!
私がbrotherの標準プリンター DCP-J928N を買って想定外だったことは、両面スキャンに対応していないことでした。両面プリントという機能があったので、てっきり対応しているものと思い込んでいましたが、残念ながら別物でした。(両面スキャンが必要なら複合機モデルを買ってということみたいです)
両面スキャンを実現する方法
両面記載された大量の書類をPDF化をする必要がありました。とてもじゃないけど1枚ずつ処理したくありません。
考えた結果、片面ずつスキャンしてPDF化した2つのファイルをパソコンにコピーして、Pythonで処理して適切に1つのファイルに結合するという方法でうまくいきました。
それでは詳しい手順を記載していきます。
① Pythonをインストール
ここからPythonのインストーラをダウンロードしてインストールします。あんまり新し過ぎたり古過ぎると対応したコードが少ないなど問題になるので、3.12か3.11ぐらいが良いのではないかと思います。
② 適当なフォルダを作成
どこでも良いので、例えばドキュメントフォルダにSCANというフォルダを作成します。
③ メモ帳で、pdf_merge.py と pdf_merge.bat を作成
以下のコードをコピーして、メモ帳に貼り付けて、SCANフォルダにそれぞれ指定のファイル名で保存します。(batファイルはWindows前提です。他のOSの場合は変換をするか、直接Pythonを実行ください)
pdf_merge.py(変換をかけるPythonコード本体)
from pypdf import PdfReader, PdfWriter
import os
def get_unique_output_filename(base_name="output.pdf"):
if not os.path.exists(base_name):
return base_name
name, ext = os.path.splitext(base_name)
counter = 1
while True:
new_name = f"{name}_{counter}{ext}"
if not os.path.exists(new_name):
return new_name
counter += 1
def merge_pdfs_alternating(file1, file2):
pdf1_reader = PdfReader(file1)
pdf2_reader = PdfReader(file2)
pdf_writer = PdfWriter()
num_pages = max(len(pdf1_reader.pages), len(pdf2_reader.pages))
for i in range(num_pages):
if i < len(pdf1_reader.pages):
page = pdf1_reader.pages[i]
pdf_writer.add_page(page)
if i < len(pdf2_reader.pages):
page = pdf2_reader.pages[-(i + 1)]
pdf_writer.add_page(page)
output_file = get_unique_output_filename()
with open(output_file, 'wb') as out:
pdf_writer.write(out)
print(f"PDF files merged successfully! Output saved as: {output_file}")
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Merge two PDF files alternately.")
parser.add_argument("file1", help="Path to the first PDF file.")
parser.add_argument("file2", help="Path to the second PDF file.")
args = parser.parse_args()
merge_pdfs_alternating(args.file1, args.file2)pdf_merge.bat(ドラッグアンドドロップ処理用バッチファイル)
@echo off
REM Check if two PDF files were dragged and dropped onto the batch file
if "%~2"=="" (
echo Please drag and drop two PDF files onto this batch file.
pause
exit /b
)
REM Specify the path to the Python script
set SCRIPT=pdf_merge.py
REM Command to run Python (adjust as needed based on your environment)
set PYTHON_CMD=python
REM Execute the Python script
%PYTHON_CMD% "%SCRIPT%" "%~1" "%~2"
pause④ PDF編集ライブラリをインストール
コマンドプロンプトを起動して、以下のコマンドを入力して、ENTERを押します。(問題なければ、ライブラリのインストールが完了します)
pip install pypdfここまでが初期設定です。毎回やるのは⑤以降です。
⑤ 片面スキャンで表面/裏面のPDFを作成、PCに保存
以下のような形で、上部パネルを開けて原稿をセットして連続スキャンします。表面、裏面と2回スキャンを実行します。

SDカード、USBメモリ、ネットワークPC、クラウド、いずれの手段でも良いので保存したPDFファイル2つを、PC上のSCANフォルダに格納します。
⑥ 2つのファイルを pdf_merge.bat にドラッグアンドドロップ
表面のPDFファイルを選択し、次にCTRLを押しながら裏面のPDFを選択します。(2つを選択することと、選択の順番が非常に重要です)
CTRLを離して、2つ選択中のPDFファイルをつまんで、 pdf_merge.bat にドラッグアンドドロップします。

すると、以下のメッセージが出て結合が完了します。キーを押して終了してください。
同じフォルダの output.pdf という名前で結合結果のファイルが保存されます。(同名のファイルが既に存在する場合は output_1.pdf _2.pdf …とカウントアップしたファイル名になります)

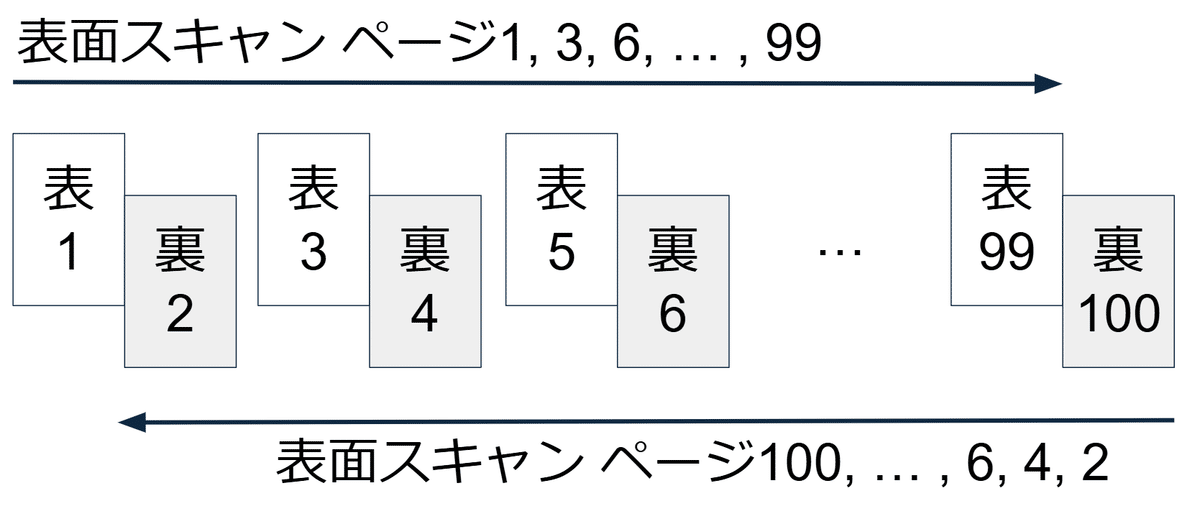
(参考) 結合の順番
PDFの結合時にPythonで表面・裏面と交互に1ページずつ取っていくのですが、表面は最初から読み込んで、裏面は最後から読み込んでいます。
これは、裏返してスキャンすると順番が逆転しているためです。