
文系の非エンジニアが、ゼロから「データ分析の手法」を学んだロードマップ

この記事の概要
数学の知識は中学レベル、データ分析の知識はゼロ、Python(プログラミング言語)の知識も皆無の状態から、「人工知能」「機械学習」「ニューラルネットワーク」「ディープラーニング」「統計」の基礎的な知識と、それを使うための技術をどのように学んだのかをお伝えします。
学び初めの初学者が、初学者視点で書いている記事なので、「厳密にはそれは違うぞ」みたいな部分や、「その単語や概念はこっちの括りじゃなくてこっちだろ」というのもあるかもしれませんがご容赦ください&こっそり教えてください。
プログラミングの知識や技術を身につけることで、できることは星の数ほどありますが、僕は1年ほど散々迷走した挙げ句、「データ分析」「データサイエンス」「人工知能」「機械学習」の分野に興味を持ち、全くのゼロの状態から、ある程度理解できようになりました。
この記事では、1年間でどうやってこれらの知識と技術の初歩を身につけて理解することができたのか?そのロードマップをお伝えしたいと思います。
私と同じように、これからプログラミングやデータサイエンスを勉強したいーー!と思う方の一助になればとても嬉しいです。
だいたいの学習時間ですが、理解の速さによりますが、私はめちゃくちゃ要領が悪いので、平日は仕事の前の朝2〜3時間、休みの日は4時間を1年続けて身につけました。

何を学んだか?
ひとくちに「データ分析の手法を学ぶ」と言っても、何を学んだらいいのか? どこから手をつけていいのか? 知識が無い状態だと全くわからないですよね。
そこでまず、1年間で何を学んだかについてざっくりお伝えしたいと思います!
【1年間で学んたこと】
・機械学習の知識
・統計学の知識
・Python、R、SQL等プログラミングの知識
・問題解決のプロセス&手法
・上記に必要な数学の基礎知識
↑大まかにこれらを学んだのですが、もうちょっと体系化した方がいいと思ったので、オンラインのホワイトボードツールmiroで学んだことをまとめてみました。

クリックすると拡大されるのですが、細かすぎて書いてあることが全くわからないことに先程気がついたので、一つずつ拡大してお話したいと思います。
数学の知識はどこまで必要か?
データ分析や機械学習では、コンピュータが計算してくれるので、出てきた結果の解釈ができて、それが理解できれば、数学の知識はあまり要らないです。というのが1年間学んで気づいたことです。
でも、理屈を知りたかったり、深堀りしたり、ブラックボックスの内側ではどういう動きをしているのかを知りたければ、数学の知識は必要不可欠です。高校時代に数学を学んできた方は、ちょっと学び直せば思い出すかもしれませんが、私のように高校時代に数学を全く学ばなかった方は、学び直しがとても大変だと思います。
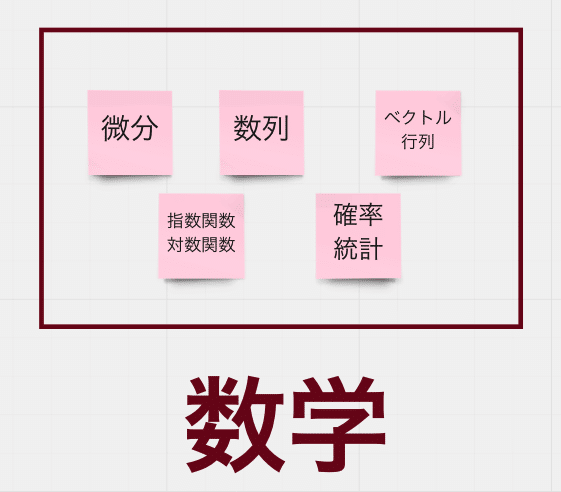
データ分析を学ぶ上での数学の知識は、以上のような範囲の学びが必要になってきます(ちなみに中学の+ー÷×とか因数分解とか√の計算とか一次式とか二次式の知識があるという大前提です)。
ただ、ご存知の通り、学問は何でもそうですが積み上げて身につけるもので、指数とか対数とか言われても、その前提となる高校数学の基礎を知らないと、何を言ってるかさっぱりわからないんですよね……。
英語で言うと、「過去完了進行形」を理解するには、過去形と完了形と進行形を理解してないと絶対理解できないのと同じです。そして過去形を理解するには現在形の理解が必要だし、現在形の理解には動詞の理解が必要で、動詞の理解には品詞の理解が必要で……みたいな感じです(笑)。
そこで私はまず、「最短コースでわかる ディープラーニングの数学」「文系プログラマーだからこそ身につけたい ディープラーニングの動きを理解するための数式入門」という本をざっと読み、完璧ではないですが、データ分析に必要な数学の知識を「なんとなく」理解しました。
これで学んでいる途中の数学の式や理論が、「全く理解できない」という状態から、「10%ぐらいは何を言いたいかわかる」という状態になりました(笑)。これでも1年のデータ分析の学びは何とかやりきることができました(細かい部分は理解できなくても、概略は理解できます)。

ですが、この状態では全然話にならないので、1ヶ月ほど前から高校の数学をゼロから学ぼうと決めて、今使っているが「長岡先生の授業が聞ける 高校数学の教科書」という本です。
これは音声&活字で高校数学がゼロから学べますが、一冊で数学I、数学A、数学II、数学B、数学III、数学Cを網羅していて、1000ページ近くあって凶器に使えるほどの厚さなので、100%勇気と覚悟が必要です。
あとは、さらに易しめの「やさしい高校数学数I・A、数II・B」の2冊に、「ふたたびの確率・統計」という本を読み進めていまして、これが泣ける程厚くて途方に暮れる日々。

これを読破すれば、データ分析に出てくる数式や理論はもうちょっと理解できるのかな……と淡い期待を抱いています。
(追記)
数学に関してですが、会社で京大数学科卒の数学のプロがいるのですがその人に聞いたら高校の数学は図形以外はデータ分析には使うと言っていたので、高校の数学の知識無い方はほぼ全部学び直した方がいいかと思います。
確率・統計の知識の話
あと数学に紐づいて確率・統計の話ですが、日本統計学会公認認定の「統計検定N級対応」という教科書は、3・4級と2級と準1級及び1級対応が出ていますが、はっきり言ってめちゃめちゃわかりにくいです。3級の途中までは頑張って読めますが、数学の知識ないと絶対挫折します。
なので、確率統計を本当に一から勉強したいのであれば、まず最初に「完全独習 統計学入門」という本を読んでみてください。この本は本当にわかりやすく書かれていて、数学苦手でも読み切ることができます。名著です。
上記の本を読破したら、復習を兼ねてWEBの「統計学の時間」というサイトを頭から読んで理解します。このサイトは非常にわかりやすくて勉強になります。
また同時に理解を深めるために「マンガでわかる統計学」という本を並行読書してみてください。この本はマンガでわかるというキャッチから、めちゃめちゃ簡単でレベルの低い本かというと、結構難しいです。多分80ページあたりの確率密度関数で一度挫折します。
でも統計学の時間のサイトを並行して学習していると、だんだんこのマンガの内容も完全理解しはじめます。
そして「統計学の時間」の「Step1」まで進んだら、それを進めつつ「はじめての統計学」か「コアテキスト統計学」を並行してやるのがおすすめです。この二つの本は、文系の方にはちょっと敷居が高い(数式出てくるので)ので、並行して学ぶのがいいと思います。
そして学びながらわからない数学の知識や理論が出てきたら、最近はYoutubeに素晴らしい動画がたくさん落ちているので、調べると独学でもなんとかなります。
これをこなすと、だいたい統計検定2級ぐらいの知識は身につきます。
意外と大切なビジネス課題の解決法の知識
社会人がデータ分析を学ぶ目的は色々あると思いますが、
「データ分析で目の前にある仕事の課題を解決したいんや!」
「データ分析でマーケティングデータを解析してガッポリ儲けたいんや!」
という人が結構多いのではないでしょうか?
ビジネスにおける分析というものは、「課題の本質を理解し、解明すること」で、長年の勘や経験でなく、データに基づいた意思決定をサポートするもの=データドリブンで課題を解決することです。
なので「起きている本当の課題は何か?」を知るためのノウハウはあった方がいいと思います。
でないと、データ分析や機械学習の知識を得たとしても、それがビジネスや実践になかなか繋がらないのかなと思います(まだビジネスにつながってない俺が言うなという話ですが。笑)。

ビジネス課題の解決手法は、上記のように色々あるのですが、読んで役立ったのは「戦略プロフェッショナルが選んだフレームワーク115」「問題解決フレームワーク大全」という二冊です。この二冊は問題解決のための具体的な手法が網羅されていて、かつ具体的な事例も書かれていてとても役に立ちました。
プログラミングの知識
これに関しては大きく分けて3つです。①機械学習、ディープラーニングを使いこなすために必要なPython(パイソン)、②統計学を学び理解するために役立つR(アール)、③データベースにアクセスして必要な情報を取ってきたりするのに必要なSQL(エスキューエル)です。
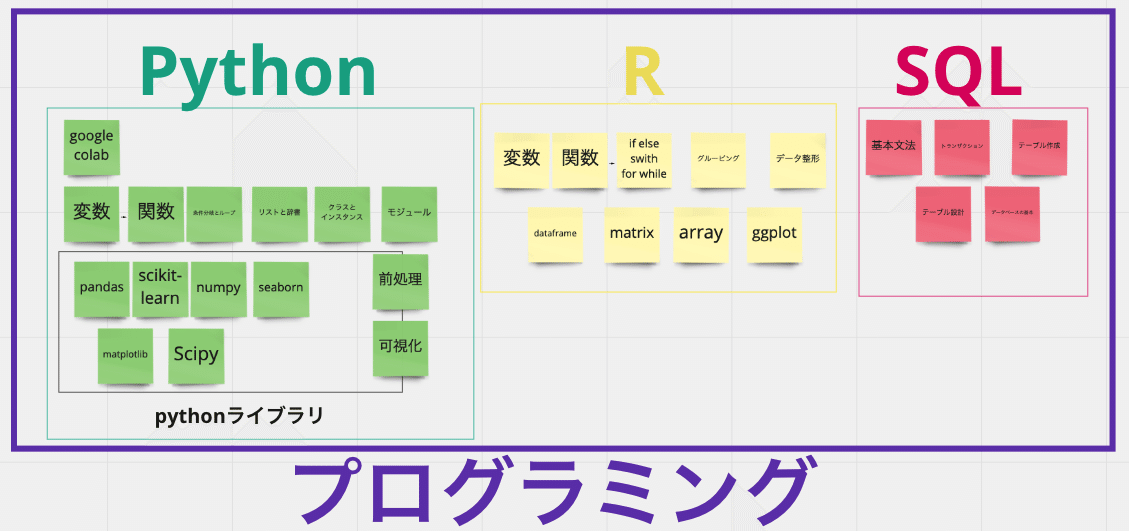
Pythonを学ぶ上では、変数や定数、関数や条件分岐やループ、リストと辞書などの基本的な知識をまず身につけて、その後にデータ分析や機械学習をする上で必須の色々なライブラリの使い方について学びます。
「やさしいPython」と「東京大学のデータサイエンティスト育成講座」という本が非常に役に立ちました。(クラスとかインスタンスとかモジュールとか例外処理という項目が出てきますが、難しければ飛ばしてもなんとかなります。最初は)
「東京大学の〜」はPythonの知識だけでなくて、機械学習の基礎についてわかりやすく書かれている名著です。数式が所々に出てきたり、難しい理論もたまに出てきますが、読み飛ばして読破するとデータ分析の全体像がちょっと見えてきます。
あまりにいい本なので周りの初学者に勧めまくってて、俺の宣伝で多分10冊ぐらいは売れてるので、著者と出版社から虎屋の羊羹でももらっていいんじゃないかと最近思っています(うそです)。

ちなみに、Pythonを学ぶのは、環境構築が面倒なので、Googleが提供している無償のGoogle Colab上で学ぶことをめちゃおすすめします。
Rに関しては、「Rによるやさしい統計学」という本がおすすめです。Rの書き方はもちろん、統計学についても学べるので一石二鳥です。数式出てきますが、無視しても読破できます。数式分かればもっと理解が深まると思いますが……。
Rの学習には、R studio cloudというタダでクラウド上でRが書けちゃうありがたい文明の利器があるので、ぜひこちらをご活用ください。
SQLは、まず最初に「スッキリわかるSQL入門」か「集中演習SQL入門」っていう本をおすすめします。SQLは学習する前に環境構築をしなくちゃいけない本が大半で、この環境構築が素人には本当に大変!
でもこの本は環境構築しなくても、SQLのクエリ(コードみたいなもんです)が学べるクラウドデータベースが構築されているので、どうやったらデータベースから自分の欲してるデータを取り出したり加工できるのか?という基礎が学べます。
どちらの本もわかりやすいですが、前者の方は会話形式の超入門書のような感じで、後者はGoogleのBigqueryというサービスを使ったものです。将来的なことを考えると、前者の本をざっと目を通して、腰を据えて後者に取り組むというのがいいと思います(これでサブクエリとウインドウ関数というSQLの中でも初心者がつまづく部分までは理解できます)。
機械学習の知識
データ分析を学ぶ本丸とも言うべきエリアがここです。
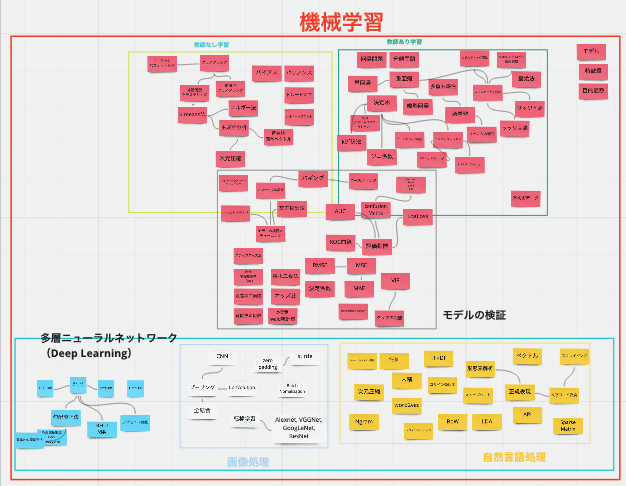
区分けの方法とか解釈が色々あるのですが、僕は以下のような感じで概略を掴んでから細部に踏み込んで学びました(間違っている部分があったら教えてください)。
まず大前提として、よく「人工知能を使って〜」とか「ディープラーニングをビジネスに活用するのに〜」とか、「機械学習をマーケティングに役立てるために〜」など、この周辺の言葉は人口に膾炙されがち(おまけに間違って使っている人も多い)ですが、私の理解だとこんな感じの関係図になっています。

広義としての人工知能というものがあって、その中に機械学習があり、その中にニューラルネットワークという手法があり、その中の多層構造を使った機械学習が多層ニューラルネットワーク=ディープラーニングと言われます。
ということでまず、大きな括りで「機械学習」というジャンルがあることを捉えます。そしてその中には、
・教師あり学習
・教師なし学習
・作ったモデルの検証&チューニング
・多層ニューラルネットワークの基礎知識
・画像処理の技術
・自然言語処理の技術
というのがあり、これらを学びました。(ここに強化学習とか転移学習というのもあるらしいですが、私は未学習です)
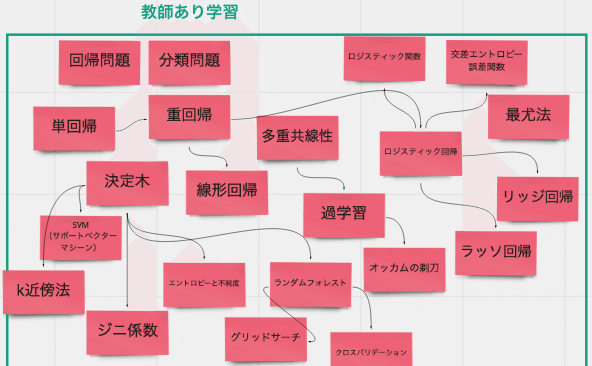
教師あり学習
まず一つ目が教師あり学習です。「教師あり」と言われても何のことやら、ですよね。でも実は意外とシンプルで「教師あり=答えあり」みたいに捉えるとわかりやすいです。

たとえば、あるスーパーのチェーンがあって、各店舗で毎月の売上が上がります。売上の要素は客単価や客数や立地、顧客のリピート数や特性など色々あり、その要素が組み合わさって売上が出ますよね。
教師あり学習とは、「すでにある色々な要素(過去の客単価とか客数)と結果(この場合売上額)を学習させて、将来のある時にどんな結果(幾らぐらいの売上になるか?)になるかを予測する」ものです。
たとえば不動産屋さんだったら、賃貸物件の値段って立地場所、駅からの距離、面積、築年数、ペット可不可、階数……(これらの要素を特徴量といいます)で家賃(これを目的変数と言います)が決まりますよね。
すでにある特徴量と目的変数を使って、未知の値(たとえばこの場合だったら○○駅から徒歩何分の○DKの鉄筋コンクリートマンション●階の値段の相場は幾ら)を予測するのが教師あり学習と呼ばれるものです。
この「教師あり学習」を大まかに理解するために学んだことが以下です。
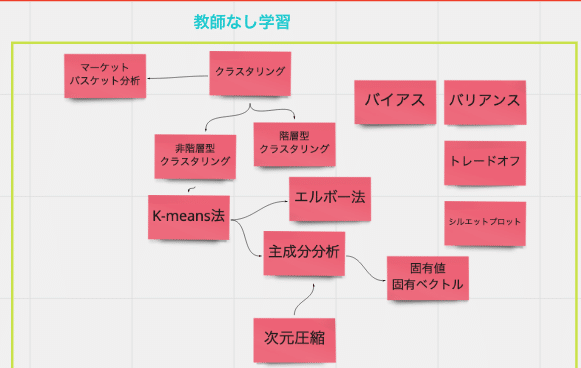
教師なし学習
教師あり学習が存在するなら、教師なし学習も存在します。教師なし学習で一番有名なのは分類問題です。
分類問題というのは、たとえば○○○万人いる人達をあるルール(属性)で分ける時に使ったり、いわば、過去のデータの中から、あるルールに従った類似性を見つけてグルーピングすることです。

この教師なし学習を理解するために学んだことが以下です(多分他にも沢山あると思いますが……)。
作ったモデルの検証&チューニング
機械学習を学ぶ上で、ここがめちゃくちゃ大事だと途中で気づきます。
これはつまり、作ったモデル(モデルというのは何だろうな、そこに何か数字とかを入れると中で計算して解答が出てくるような箱みたいなもの?)が本当に使えるのか?役に立つのか?を検証して、ポンコツなモデルだったらチューニングして磨いていくための知識や技術です。
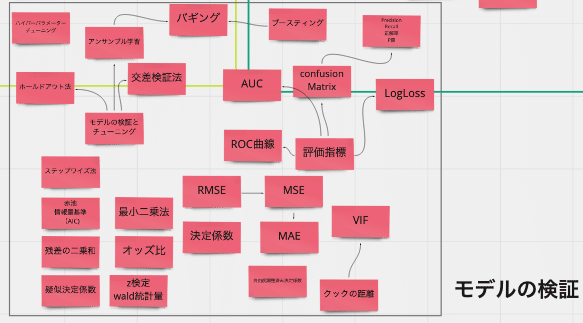
上記のような単元をこのモデル検証&チューニングで学びましたが、個人的にはここを理解して身につけるのが一番難しいです。
多分数学の造詣が深い人は、ここをディープに理解できるんだろうなと思います。

上記「教師あり」「教師なし」「モデルの検証&チューニング」はさっきご紹介した「東京大学の〜」に詳しく書かれています。あと「Pythonによる因果分析」という本もわかりやすくかつ具体的でおすすめです。
地味だけどめちゃ大切な「前処理」
ちょっと脱線しますが、データ分析で地味だけどとても大切な作業が「前処理(データクレンジング)」と呼ばれる工程です。
前処理というのは、あるデータ(エクセルでもCSVでもテキストファイルでも何でもいいです)を綺麗にするための作業です。
単位を揃えたり、欠損値を除去したり埋めたり、半角や全角を統一したり、一つのカラムに複数のデータが入っているのを直したり……と聞いているだけでめちゃ地味ですよね。
でも、データ分析を学んで知ったんですが、この作業に全体の8割ほど時間を取られます。そしてめちゃめちゃ大切&奥が深いです。
「Garbage in, garbage out(ゴミからはゴミしか出てこない)」という有名な格言があるのですが、汚いデータで分析をしても、決していい結果は出てこなくて、データ分析する前にデータを綺麗にする前処理が必要です。

現実世界では、実家の物置のゴミみたいなガラクタからお金になるものが発掘されるなんてことはありますが、データ分析の世界では、ゴミからはゴミしか出てきません。ここがポイントです。
前処理はPythonのpandasなどを使った知識&技術を使って対応します。おすすめなのは、「Python実践データ分析100本ノック」「現場で使える! pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法」です。
多層ニューラルネットワークの基礎知識
ここは深堀りすると素人にはわけがわからない世界なのと、知らなくてもまあ初学者レベルならなんとかなるので、あまり深堀りしませんでした。
多分ここを深堀りするには微分などの知識が必要みたいなので、本をそっと閉じまして、以下のような言葉の意味とニュアンスを捉えるのにとどめました。
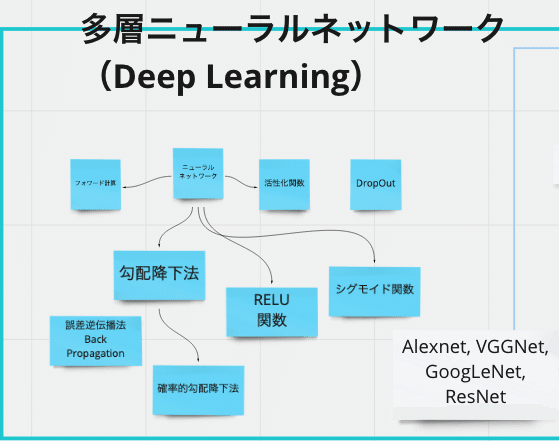
この辺りは、「機械学習&ディープラーニングのしくみと技術がしっかりわかる教科書」「はじめてのディープラーニング -Pythonで学ぶニューラルネットワークとバックプロパゲーション」という本がおすすめです。
画像処理の技術
画像処理の技術っていうのは、例えば顔認識とか、スマホのカメラかざすだけで花の名前がわかったり、ワインのラベル撮影するだけでワインの名前がわかるアプリとか、ああいうので使われている技術で、それを知るために必要な知識です。
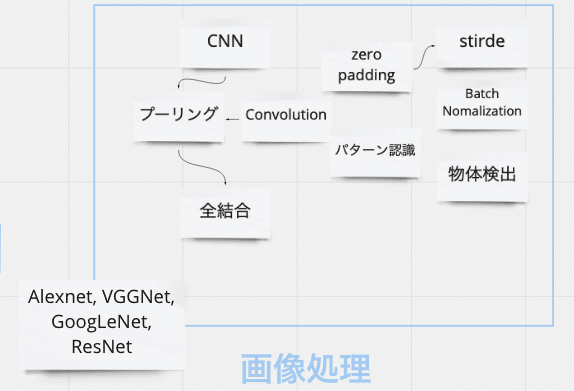
この辺の話は、「機械学習&ディープラーニングのしくみと技術がしっかりわかる教科書」で基本を知り、「今すぐ試したい! 機械学習・深層学習(ディープラーニング) 画像認識プログラミングレシピ」で深堀りしていくのがいいです。
ちなみに、先日アレな動画のアレなモザイクをAI使って消したらパクられたニュースが騒がれましたが、この技術も画像処理何でしょうか?動画だからちょっと違うのかな。誰か詳しい人いたら教えてください。
自然言語処理の技術
なんでテクノロジーの世界って難しい言葉を使うんでしょうか!「自然言語処理」と言われても何のことやらですよね。
これも後から知ったのですが、情報処理の世界でプログラミング言語に対しての「自然言語」っていう解釈の仕方で(合ってるのか?)、つまり自然言語とは英語とか日本語とかスワヒリ語とかドイツ語とかパンジャーブ語のことです。
だから自然言語処理っていうのは、日本語とか英語のような、我々が使っている言葉をコンピュータに分析してもらう手法です。
たとえば膨大なアンケート文書の中から客の趣味趣向を紐解くとか、頻出単語と単語と単語の関連性を調べるとか、口コミを分析してどんな評判が多いのか分析するとか……そんな処理をします。
そんな自然言語処理を理解するのに学んだ知識が以下です。

自然言語処理を学習する上で参考にしたのは、「現場で使える!Python自然言語処理入門」「機械学習・深層学習による自然言語処理入門 ~scikit-learnとTensorFlowを使った実践プログラミング」です。
さいごに
最後までお読み頂きありがとうございました。勉強すること、結構ありますよねーー。
もしもう少しライトに知りたいんだけど……。と考えていらっしゃる方は、pythonと機械学習(教師あり、なし)だけを学んでみて、概要掴んでから興味のある方向に拡げてみるという学習法もありだと思います。
この記事がプログラミングやデータ分析に興味のある人、初学者の皆さんに参考になれば幸いです!
(おわり)
感想頂けると泣いて喜びます!

いいなと思ったら応援しよう!
