SQS?Lambda?ECS?。PDF作成がカオスになってしまった話w

XTechの鈴木です。現在XTechグループの株式型クラウドファンディングを運営するイークラウドで開発に従事しています。

弊社では、金融系サービスという事でデータから書類を作成し、PDFとして管理しておく機能がございます。
その機能について、最終的に下記の流れで作成するに至っているのですが、その至った経緯とどのようにPDFを作成しているのかについて今回は、書いていきたいと思います。
API(ECS)→SQS→Lambda→ECS
---------------------------------------------------------------
お断り。この記事を書いた後AWSからこんな発表がありましたw
「Lambdaコンテナ対応するよー」
なので、今後は、Lambda→ECSしなくてもそのままいけそうww
---------------------------------------------------------------
これまでのPDF作成
弊社では、Djangoを用いて開発を行っており、下記の流れでPDFを作成しておりました。
◆ DjangoTemplateを用意しておく
◆ APIアクセスがあった場合にDBから取得した情報をTemplateに渡す
◆ Template to HTMLを作成する
◆ 出来上がったHTMLをPDFに変換する
◆ 出来上がったPDFをS3にアップロードする
◆ S3のPathをDBに保存
これまでは、そこまでPDF作成の重要度も低く、運用担当者が任意のタイミングで作成する程度の機能でしたので上記の方法で作成をしていたのですが、
運用担当者より
「PDFを数百人分を一気に作りたいのですが。。。」
との話がありました。がーん ʅ(◞‿◟)ʃ
数百人を一気に作るとなると、下記の懸念がございます。
◆ 非同期じゃないので、APIからレスポンスが返ってくるより先にtimeoutに
◆ APIを握ってしまう
◆ APIが握る事で、APIの負荷が増大
運用担当者が連打なんてした日には_:(´ཀ`」 ∠):
(管理画面なので、あまり制御入れてなかった;;;)
という事で、今のAPIで処理する方法ではなく、非同期の別のリソースで処理をする必要が出てきました
API→SQS→Lambdaを試す
弊社はAWSを使用している事もあり、まず考えたのはAPIにアクセスがあった場合にAWSのSQSを使用し、メッセージキューのトリガーとしてlambdaを発火させる方法を考えました。
イメージはこんな感じです。
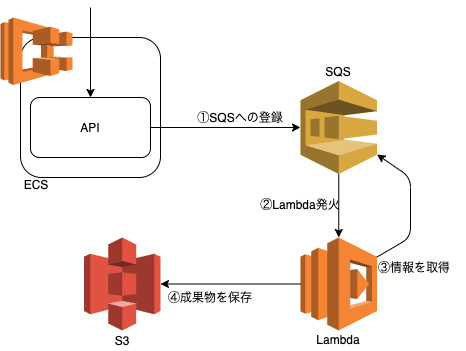
API側のコード
class SQS:
"""
SQSへのアクセスの基本的な機能を提供する
"""
def __init__(self):
if (
settings.AWS_ACCESS_KEY_ID is not None
and settings.AWS_SECRET_ACCESS_KEY is not None
):
self.client = boto3.resource(
"sqs",
aws_access_key_id=settings.AWS_ACCESS_KEY_ID,
aws_secret_access_key=settings.AWS_SECRET_ACCESS_KEY,
region_name="XXXXXXX",
endpoint_url="https://sqs.XXXXXXX.amazonaws.com",
)
else:
self.client = boto3.resource(
"sqs",
region_name="XXXXXXX",
endpoint_url="https://sqs.XXXXXXX.amazonaws.com",
)
def send_messages(self, name="", message_body=""):
try:
# キューの名前を指定してインスタンスを取得
queue = self.client.get_queue_by_name(QueueName=name)
# except:
except ClientError as error:
Logging.warning(error)
# 指定したキューがない場合はexceptionが返るので、キューを作成
queue = self.client.create_queue(QueueName=name)
entries_id = なにかしらID
body = json.dumps([message_body])
Logging.info(f"SQS send_messages Id:{entries_id}, MessageBody:{body}")
response = queue.send_messages(
Entries=[{"Id": entries_id, "MessageBody": body}]
)
Logging.info(response)弊社の環境ではECSからSQSにアクセスする形になるので、AWS_ACCESS_KEY_IDは使用せず、IAMの制御で行っておりますが、別環境などからアクセスする場合は、任意にAWS_ACCESS_KEY_IDを指定する事も可能です。
SQS

こんな感じでSQSにlambda関数トリガーを登録できます。
(IAMとかネットワーク設定、各種パラメータなどは、今回長くなりそうなので省きます)
Lambda
import boto3
import json
import os
queue_name = os.environ["QUEUE_NAME"]
task_definition = os.environ["TASK_DEFINITION"]
subnets = os.environ["SUBNET"]
ecs = boto3.client('ecs')
def lambda_handler(event, context):
print("starting.... lambda")
# sqs
sqs = boto3.resource('sqs', region_name="XXXXXXXXX", endpoint_url="https://sqs.XXXXXXXXX")
queue = sqs.get_queue_by_name(QueueName='SQSのQueue名を指定します')
for record in event['Records']:
payload = record["body"]
json_dict = json.loads(payload)
# 何かしらここでAPI側で詰め込んだパラメータを取得する
......
# Queueを削除しちゃいます(どのくらい削除するかは、それぞれの判断で)
msg_list = queue.receive_messages(MaxNumberOfMessages=1)
for message in msg_list:
message.delete() こんな感じで、lambda側でSQSに情報を取りに行ってます。
情報を取ったならばこの後のlambdaの処理でPDFを作成して、S3にアップロードすればよい事になります。
ちょっと脱線
lambdaのレイヤーめっちゃ便利だって話。結構lambdaから離れていたので、キャッチアップできてなかったのですが、
lambdaにレイヤーが用意されていて、今回使ってみましたがとっても便利でした。これまでは、どこかの環境でライブラリなど全て入れた状態のzipファイルを作成して、lambdaにzipでのアップロードが必要でしたが、
このレイヤーを使用することにより、事前にライブラリのアップロードや、他の人が上げてくれたライブラリのarnを指定することでlambdaがそのライブラリを参照し使用することが可能になりました。
上記のboto3なんかはレイヤーでいれました。
参考がてらにyumdaとかで入れると便利です。
こんな感じでワンライナーでできるぞよ
docker run --rm -v "$PWD"/wkhtmltopdf:/lambda/opt lambci/yumda:2 yum install -y wkhtmltopdfまさかの壁にぶち当たる
lambdaでPDFを作成して、s3にアップするところまで作った段階で、あることに気づく・・・
「PDFは、基本日本語ですけど。。。ファッ!? (゜Д゜;)」
そういえば、今までNotoSansJapaneseを使用して、作成されとった。
まいっか、NotoSansJapaneseをレイヤーで入れればいっかという、単純な考えw
ここに気をつけよう。lambdaのデプロイパッケージサイズは、レイヤー含めて250MBという事。
これはクォータの上限引きあげも対応していないので、おわたw
NotoSansJapaneseのサイズでかいもん><

なので、いろいろ変えると軋轢あるし、時間もないし、方向転換します。
そもそも、これまでは、ECSのAPIの中で、PDFを作成していたので、その作成している部分を非同期で実行できればいいやという事で、lambdaからECSのコンテナを独立して立ち上げてそこで処理をすれば、工数的にも楽だわって事で!
実際には、Djangoのカスタムコマンドを実行してあげる形
API→SQS→Lambda→ECSに帰結
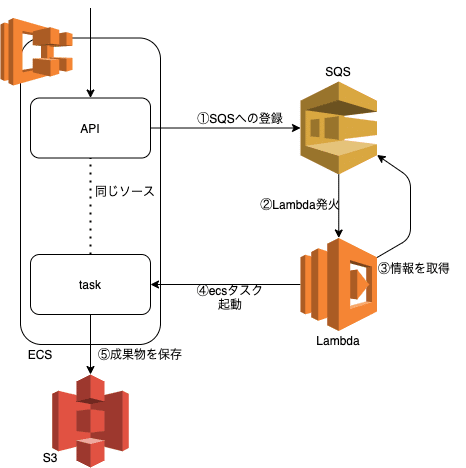
上記のような流れにしました。ECSで実行されるコンテナのソースコードは、今のAPIで管理しているソースと同じ形にすることで、時短的な感じで実行できるようになりました(本来は、分けて開発すべきですがw)
とはいえ、このスキームでのsqs-lambda-ecsは、何かと使えそうな形なので今回は、記事にしてみました。
新しい形でのAPI to SQS だったり、lambdaからSQSのパラメータを取得するところについては、前のecsを立ち上げない方法と同じなので、説明を省きます。lambdaからecsを立ち上げて実行するところを簡単に記載しておきます。
lambdaからecsを起動するコード
# ECSタスクの実行(単発)
response = ecs.run_task(
cluster='クラスター名',
taskDefinition='タスク名',
launchType='FARGATE',
networkConfiguration={
"awsvpcConfiguration": {
"subnets": ["サブネット"],
"assignPublicIp": "ENABLED",
}
},
overrides={
'containerOverrides': [
{
'name': task_definition,
'command': ["python","manage.py","コマンド",f"{key}",f"--hoge_id={hoge_id}"],
'memory': 512
}
]
}
)上記のコードでECSを立ち上げることができます。task自体は、手動で作成しても、terraformなどで管理してもいいと思いますが、何かしら作成しておきましょう。
このような形でecsのタスクが立ち上がり、処理が実行されます。実行結果などslack通知してもいいですし、何かしらでキャッチしてもいい気がしますが、今回は、説明が複雑になるのでエラー処理含めて端折って説明させて頂きました。
まっさらな状態から新しく構築できれば、様々な方法の選択肢がある場合もありますが、実際の現場では、すでにあるシステムからできるだけ工数をかけない方法を選択したりしなければいけないこともあり、最適解の模索が続いているかと思いますが、同じような悩みをお持ちの方に少しでも届けばと思います。