
Raspberry Pi 4でDockerコンテナからGoogleのMediaPipe v0.9.3.0のObject Detectionで物体検知をおこなう方法(2023年5月時点)

最終更新日:2023年5月30日
本記事では、Raspberry Pi 4を使用して、Dockerコンテナ上でGoogleのMediaPipe v0.9.3.0をインストールし、Raspberry Pi 4に接続したUSBカメラの映像をObject Detectionを使用して物体検知をおこなう方法を説明します。
本記事は以下の前回の記事からの続きとなります。
環境
本記事を参考に、MediaPipeを試すには以下のものが必要です。
Raspberry Pi 4
SDカード32GB (32GB以上であれば問題ないです)
USBマウス
USBキーボード
USBカメラ
インターネット接続 (本記事は有線接続です)
Winodows10パソコン(Winodows10パソコンからRaspberry Pi 4とSSH接続して操作するために使用します。直接Raspberry Pi 4から操作する場合は不要です)
前提条件
Raspberry Pi 4のOSは64bit版であること。
Raspberry Pi 4にDockerをインストール済みであること。
mediapipe-0.9.3.0-cp38-cp38-linux_aarch64.whlファイルを入手済みであること。
Raspberry Pi 4の64bit版のOSの書き込み方法とDockerのインストールは以下の記事を参考にしてください。
mediapipe-0.9.3.0-cp38-cp38-linux_aarch64.whlファイルは以下の記事からダウンロードしてください。
前提条件を満たしたらDockerコンテナを作成し、MediaPipe v0.9.3.0をインストール、その他必要なライブラリのインストールをおこない、実際にUSBカメラからの映像をObject Detectionに入力してみましょう。
準備
Raspberry Pi 4のデスクトップにmpフォルダを新規作成します。
mpフォルダの中にmediapipe-0.9.3.0-cp38-cp38-linux_aarch64.whlファイルをコピーします。
Raspberry Pi 4にUSBカメラを接続します。
ここで作成したmpフォルダをDockerコンテナにマウントするため、必ずデスクトップにmpという名称のフォルダを作成してください。
Dockerイメージの入手
ベースとするDockerイメージを入手します。ターミナルを開いて以下のコマンドを入力します。
$ sudo docker pull python:3.8.16-busterDockerイメージをダウンロードできたか確認します。以下のコマンドを入力します。
$ sudo docker images以下のようにTAGに3.8-slim-busterとあれば成功です。
note@raspberrypi:~/Desktop/mp $ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
python 3.8-slim-buster 8efd70673d8f 4 weeks ago 110MB以上でDockerイメージの入手の説明は終了です。
Dockerコンテナの起動
以下のコマンドを入力しますが、コマンド中のUSERはお使いの環境に合わせて変更してください。
※ pwdと入力するとUSERが何かわかるはずです。
※ docker runコマンド入力時、--rmを付与していないため、コンテナ停止時に削除されずに残ります。再度、起動したい場合はsudo docker start <コンテナID >で起動できます。本記事ではdockerについては割愛します。
$ sudo docker run -it --network host --device=/dev/video0:/dev/video0 -v /tmp/X11-unix:/tmp/X11-unix:rw -e DISPLAY=$DISPLAY -v /home/USER/Desktop/mp:/mp python:3.8.16-buster bashコマンドの入力後、コンテナの中に入った状態で始まります。コンテナの中では先頭に#が付与されます。(本記事の執筆時に私が使用したRaspberry Pi 4のUSERはnoteです)
note@raspberrypi:~/Desktop/mp $ sudo docker run -it --network host --device=/dev/video0:/dev/video0 -v /tmp/X11-unix:/tmp/X11-unix:rw -e DISPLAY=$DISPLAY -v /home/note/Desktop/mp:/mp python:3.8.16-buster bash
root@raspberrypi:/# 以上でDockerコンテナの起動の説明は終了です。
ライブラリのインストール
コンテナの中で以下のコマンドを順番に入力します。コンテナの中のため、先頭を$から#に変更しています。
# apt update
# apt install cython3 python3-opencv
# cd mp
# pip3 install mediapipe-0.9.3.0-cp38-cp38-linux_aarch64.whlapt install cython3 python3-opencvの入力時、以下の表示がされるのでキーボードのyを入力してEnterキーを押します。
0 upgraded, 245 newly installed, 0 to remove and 8 not upgraded.
Need to get 148 MB of archives.
After this operation, 813 MB of additional disk space will be used.
Do you want to continue? [Y/n] ライブラリのインストールが完了したら、以下のコマンドを入力して内容を確認します。
# pip3 list私の環境では以下のようになりました。mediapipeのバージョンが0.9.3.0であることを確認します。
root@raspberrypi:/mp# pip3 list
Package Version
--------------------- --------
absl-py 1.4.0
attrs 23.1.0
cffi 1.15.1
contourpy 1.0.7
cycler 0.11.0
flatbuffers 23.5.8
fonttools 4.39.3
importlib-resources 5.12.0
kiwisolver 1.4.4
matplotlib 3.7.1
mediapipe 0.9.3.0
numpy 1.24.3
opencv-contrib-python 4.7.0.72
packaging 23.1
Pillow 9.5.0
pip 22.0.4
protobuf 3.20.3
pycparser 2.21
pyparsing 3.0.9
python-dateutil 2.8.2
setuptools 57.5.0
six 1.16.0
sounddevice 0.4.6
wheel 0.40.0
zipp 3.15.0
WARNING: You are using pip version 22.0.4; however, version 23.1.2 is available.
You should consider upgrading via the '/usr/local/bin/python -m pip install --upgrade pip' command.
root@raspberrypi:/mp# 以上でライブラリのインストールの説明は終了です。
Object Detectionの学習済みモデルのダウンロード
以下のリンクからObject Detectionの学習済みモデルをダウンロードします。
本記事では、Windows10パソコンとRaspberry Pi 4をVisual Studio Code使用してSSH接続しているので、Windows10パソコン側に学習済みモデルをダウンロードしていますが、Raspberry Pi 4側で学習済みモデルをダウンロードしても問題ありません。
Visual Studio CodeでRaspberry Pi 4にSSH接続する方法は以下の記事を参考にしてください。
最後にダウンロードした学習済みモデルをRaspberry Pi 4のデスクトップのmpフォルダに格納します。
以上でObject Detectionの学習済みモデルのダウンロードの説明は終了です。
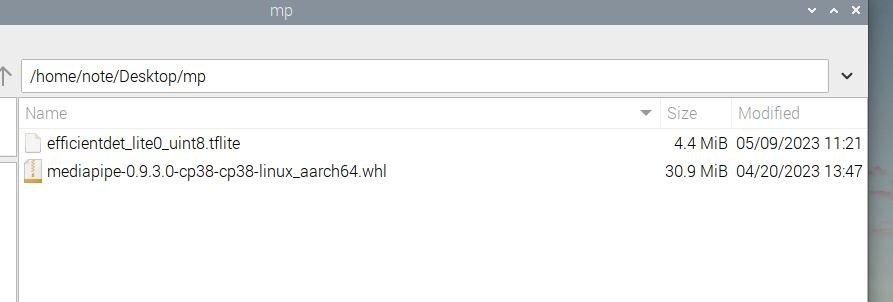
ここまでの確認
Raspberry Pi 4のデスクトップのmpフォルダの中身は以下のスクリーンショットのようになります。
Object Detectionを使用したpythonコードの作成
デスクトップのmpフォルダにobject_note.pyというファイルを新規作成してください。
object_note.pyファイルが作成できたら、以下のコードをコピー&ペーストしてください。
import cv2
import numpy as np
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
MARGIN = 10 # pixels
ROW_SIZE = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
TEXT_COLOR = (0, 0, 255) # red
def visualize(image, detection_result) -> np.ndarray:
"""Draws bounding boxes on the input image and return it.
Args:
image: The input RGB image.
detection_result: The list of all "Detection" entities to be visualize.
Returns:
Image with bounding boxes.
"""
for detection in detection_result.detections:
# Draw bounding_box
bbox = detection.bounding_box
start_point = bbox.origin_x, bbox.origin_y
end_point = bbox.origin_x + bbox.width, bbox.origin_y + bbox.height
cv2.rectangle(image, start_point, end_point, TEXT_COLOR, 3)
# Draw label and score
category = detection.categories[0]
category_name = category.category_name
probability = round(category.score, 2)
result_text = category_name + ' (' + str(probability) + ')'
text_location = (MARGIN + bbox.origin_x,
MARGIN + ROW_SIZE + bbox.origin_y)
cv2.putText(image, result_text, text_location, cv2.FONT_HERSHEY_PLAIN,
FONT_SIZE, TEXT_COLOR, FONT_THICKNESS)
return image
BaseOptions = mp.tasks.BaseOptions
ObjectDetector = mp.tasks.vision.ObjectDetector
ObjectDetectorOptions = mp.tasks.vision.ObjectDetectorOptions
VisionRunningMode = mp.tasks.vision.RunningMode
options = ObjectDetectorOptions(
base_options=BaseOptions(model_asset_path='efficientdet_lite0_uint8.tflite'),
running_mode=VisionRunningMode.VIDEO,
max_results=20,
score_threshold=0.5)
with ObjectDetector.create_from_options(options) as detector:
# The detector is initialized. Use it here.
# ...
# Use OpenCV’s VideoCapture to load the input video.
cap = cv2.VideoCapture(0)
while True:
# Load the frame rate of the video using OpenCV’s CAP_PROP_POS_MSEC
# You’ll need it to calculate the timestamp for each frame.
frame_timestamp_ms = cap.get(cv2.CAP_PROP_POS_MSEC)
# Loop through each frame in the video using VideoCapture#read()
ret, image = cap.read()
if not ret:
break
# Convert the frame received from OpenCV to a MediaPipe’s Image object.
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
# Perform object detection on the video frame.
detection_result = detector.detect_for_video(mp_image, int(frame_timestamp_ms))
# Result display
annotated_image = visualize(np.array(image).astype(np.uint8), detection_result)
cv2.imshow('screen', annotated_image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()上記のpythonコードは、以下からダウンロードも可能です。
Raspberry Pi 4のデスクトップのmpフォルダの中身は以下のスクリーンショットのようになります。
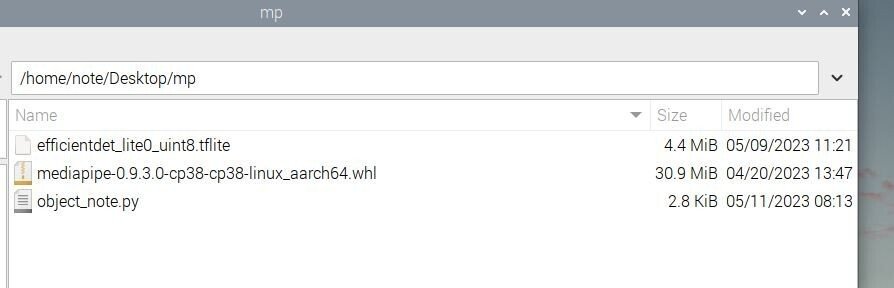
以上でObject Detectionを使用したpythonコードの作成の説明は終了です。
Dockerコンテナ内の確認
本記事のDockerコンテナ起動を実施しているので、ターミナルはコンテナの中に入っている状態のはずです。
コンテナ内でlsコマンドを実行してみてください。Raspberry Pi 4のデスクトップのmpフォルダの内容がコンテナ内にもコピーされています。
root@raspberrypi:/mp# ls
efficientdet_lite0_uint8.tflite mediapipe-0.9.3.0-cp38-cp38-linux_aarch64.whl object_note.py
root@raspberrypi:/mp# Object Detectionの実行のための準備
X Window SystemのXサーバーに対してマシンラーニングコンテナからの接続の許可
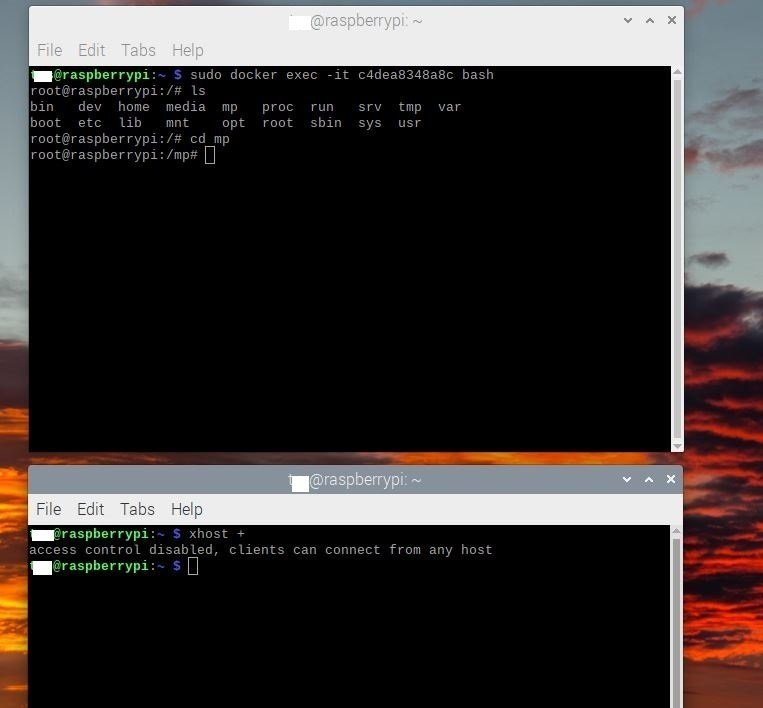
コンテナからRaspberry Pi 4のデスクトップにカメラ画像を表示するためにはGUIを使用します。コンテナからのGUI使用を許可する必要があります。本記事通りに進めている場合は、コンテナの中にいるターミナルが開いています。これとは別に新しくターミナルを開き、以下のコマンドを入力します。
$ xhost +別に新しくターミナルを開くとは、以下のスクリーンショットで説明すると、上側のターミナルは本記事で言うところのコンテナ内、この状態でもう一つターミナルを起動(下側のターミナル)してxhost +を入力します。
環境変数DISPLAYの設定
コンテナからRaspberry Pi 4のデスクトップにカメラ画像を表示するためにコンテナ内の環境変数DISPLAYを設定します。コンテナ内で以下のコマンドを実行します。
# export DISPLAY=:0以上でObject Detectionの実行のための準備の説明は終了です。
Object Detectionの実行
コンテナでobject_note.pyを実行します。以下のコマンドを入力します。
# python3 object_note.pyコマンドを入力後、以下のように出力されます。
root@raspberrypi:/mp# python3 object_note.py
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.Raspberry Pi 4のデスクトップにカメラ映像とともに推論結果が表示されます。
停止したい場合は、ターミナルでCtrl+Cを入力します。
最後に…
本記事では、MediaPipe v0.9.3.0を使用してObject Detectionを試しましたが、他にもHand LandmarkやHand Gesture Recognition等多々あります。
公式ページにはサンプルコードがあるので、試してみましょう。
この場合も、デスクトップのmpフォルダにpythonファイルを追加すればコンテナ内で実行できます。