
「Pythonによる異常検知」を寄り道写経 ~ 第3章3.5節「時系列データにおける異常検知」機械学習編②特異スペクトル変換法

第3章「時系列データにおける異常検知」
書籍の著者 曽我部東馬 先生、監修 曽我部完 先生
この記事は、テキスト「Pythonによる異常検知」第3章「時系列データにおける異常検知」3.5節「時系列データにおける異常検知」3.5.2項「機械学習による時系列データの異常検知」の通称「寄り道写経」を取り扱います。
7回連続で機械学習を利用した時系列データの異常検知を寄り道写経します!
今回は時間窓を利用した特異スペクトル変換法です。
ではテキストを開いて時系列データの異常検知の旅に出発です🚀

はじめに
テキスト「Pythonによる異常検知」のご紹介
このシリーズは書籍「Pythonによる異常検知」(オーム社、「テキスト」と呼びます)の寄り道写経です。
テキストは、2021年2月に発売され、機械学習等の誤差関数から異常検知を解明して、異常検知に関する実践的なPythonコードを提供する素晴らしい書籍です。
とにかく「誤差関数」と「異常度」の強い結びつきを堪能できる1冊です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「Pythonによる異常検知」第1版第6刷、著者 曽我部東馬、監修者 曽我部完、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
3.5 時系列データにおける異常検知
主に Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
今回の寄り道ポイントです。
前回から引き続き時間窓データを用います。
テキストによると特異スペクトル変換法は「スライド窓を利用した時間窓データ=時系列の行列について、行列の特異値と特異スペクトルを利用して異常度を算出する手法」です。
記事で用いるデータセットはテキスト提供データを引用いたします。
この記事で用いるライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
特異スペクトル変換法
文章で説明するのは難しいです…
履歴行列(部分訓練データ)とテスト行列、特異値分解などの概念は図や数式による説明が必要そうです。
ぜひテキストやWeb情報などでご確認ください。
例えば Fire Engine さんのブログが参考になりました。

データの読み込み
テキストのデータを引用いたします。
ECGデータと呼ばれる心電図の公開データです。期間の単位はミリ秒です。
テキストによると「時系列異常検知のベンチマーク解析に頻繁に用いられる」そうです。
### データの読み込みとデータセットの作成 ※テキストのコードを引用、一部改変
# データの読み込み
data_orgn = np.loadtxt('./data/discord.txt', delimiter='\t')
# 最初の6000件・3列目のデータを分析
data = data_orgn[:6000, 2]
# 結果表示
print('data.shape:', data.shape)
print(data[:5], '...')【実行結果】
2行目はECGデータの冒頭5個を表示しています。


STEP 1, 2 サンプルを作成して異常度を算出する
時間窓サンプル作成関数を定義します。
### 時間窓サンプルの作成関数の定義 ※テキストと異なるコード
def make_samples(data, window): # window: 時間窓幅
result = [data[i:i + window] for i in range(len(data) - window + 1)]
return np.array(result)時間窓幅、その他の設定です。
### パラメータの設定 ※テキストの設定と同じ
w = 50 # 時間窓幅
l = 25 # 履歴行列・テスト行列の行数
d = 10 # 履歴行列・テスト行列の列数
m = 2 # 特異値行列算出に利用する履歴行列・テスト行列の列数
T = len(data) # 時系列データの総数全データを一括利用してモデルの学習とテストを実行します。
### 時間窓・特異スペクトル変換法による異常検知の実行
# ※テキストのコードを引用、一部改変
# 異常度を格納する配列の準備
anomaly_score = np.zeros(T)
# 時間窓ごとに異常度算出を繰り返し処理
for s in range(l+w-1, T-d):
# 履歴行列の作成
H_hist = make_samples(data[s-w-l+1:s], w).T
# テスト行列の作成
H_test = make_samples(data[s-w-l+1+d:s+d], w).T
# 履歴行列・テスト行列を特異値分解して左特異ベクトルを取得
U_hist = np.linalg.svd(H_hist)[0]
U_test = np.linalg.svd(H_test)[0]
# 左特異ベクトルのm列分の行列積をさらに特異値分解して特異値ベクトルを取得
SV_vec = np.linalg.svd(U_hist[:, 0:m].T @ U_test[:, 0:m])[1]
# print('特異値ベクトル:', SV_vec)
# 異常度の算出:1-特異値行列の最大値の二乗 1000倍して単位を大きくする
anomaly_score[s] = (1 - SV_vec[0]**2) * 1000
# 異常度の表示
print('異常度データ数:', anomaly_score.shape)
print('異常度 :', anomaly_score[:10], '...')【実行結果】


STEP 3 異常度の閾値を算出する
なんとなく分位点法を使ってみます。
テキストは異常度の閾値に言及しておらず、テキストオリジナルコードでは6番目に大きい異常度を閾値にしています。
分位点を$${0.1\%}$$とすることで、6番目に大きい異常度が閾値になります。
### 異常度の閾値の算出 by 分位点法
# 分位%点の設定
q = 0.001
# 閾値の算出
num_quantile = int(round(len(anomaly_score) * q, 0))
threshold = sorted(anomaly_score)[::-1][num_quantile - 1]
# 閾値の表示
print('分位点数:', num_quantile)
print('閾値:', threshold)【実行結果】
異常度の閾値はおよそ 0.90 です。
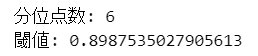

STEP 4 異常値を確認する
異常値を抽出してみます。
### 異常値の抽出
anomaly_index = np.where(anomaly_score >= threshold)[0]
anomaly_values = np.array(anomaly_score)[anomaly_index]
print('異常値の時点:', anomaly_index)
print('異常値の値 :', anomaly_values)【実行結果】
6点の異常値は 4300 ミリ秒付近に集中しています。

続いて可視化です。
テキストの図3.47に相当するグラフを描画します。
描画関数を定義します。
### 特異スペクトル変換法による異常検知の描画関数の定義
def plot_anomaly(data, anomaly_score, threshold):
# 描画領域の設定 gs:gridspecで上下のaxesの高さを5:2にする
fig = plt.figure(figsize=(10, 5))
gs = fig.add_gridspec(2, 1, height_ratios=(5, 2))
ax1 = fig.add_subplot(gs[0, 0])
ax2 = fig.add_subplot(gs[1, 0])
# 観測値の描画
ax1.plot(data, lw=0.9)
ax1.set(ylabel="ECG's value[$ms^2/Hz$]")
ax1.grid(lw=0.5)
# 異常度の描画
ax2.plot(anomaly_score, color='tab:red', lw=0.9)
ax2.hlines(threshold, 0, 6000, color='red', ls='--')
ax2.sharex(ax1)
ax2.set(ylabel='異常度')
ax2.grid(lw=0.5)
# 全体修飾
fig.suptitle('特異値ベクトル変換法の異常検知\n'
f'上段:観測値、下段:異常度 閾値{threshold:.3f}')
fig.supxlabel('時間[ミリ秒]')
plt.tight_layout()
plt.show()異常度を可視化します。
### 異常度の可視化 ★図3.47に相当
plot_anomaly(data, anomaly_score, threshold)【実行結果】
上段の青い線が観測値、下段の赤い線が異常度です。
観測値は4300ミリ秒あたりに他の時間と異なる部位があります。
赤い水平点線の異常度の閾値は4300ミリ秒付近を異常値だと判定しています。
うまく異常検知できているようです!

今回の寄り道写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。