
「Pythonによる異常検知」を寄り道写経 ~ 第3章3.4節「機械学習による時系列データの解析」①多層パーセプトロン

第3章「時系列データにおける異常検知」
書籍の著者 曽我部東馬 先生、監修 曽我部完 先生
この記事は、テキスト「Pythonによる異常検知」第3章「時系列データにおける異常検知」3.4節「機械学習による時系列データの解析」の通称「寄り道写経」を取り扱います。
2回連続で機械学習を利用した時系列データ解析を寄り道写経します!
今回は 多層パーセプトロン(MLP)です。
※異常検知はありません。
ではテキストを開いて時系列データ解析の旅に出発です🚀

はじめに
テキスト「Pythonによる異常検知」のご紹介
このシリーズは書籍「Pythonによる異常検知」(オーム社、「テキスト」と呼びます)の寄り道写経です。
テキストは、2021年2月に発売され、機械学習等の誤差関数から異常検知を解明して、異常検知に関する実践的なPythonコードを提供する素晴らしい書籍です。
とにかく「誤差関数」と「異常度」の強い結びつきを堪能できる1冊です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「Pythonによる異常検知」第1版第6刷、著者 曽我部東馬、監修者 曽我部完、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
3.4 機械学習による時系列データの解析
主に Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
今回の寄り道ポイントです。
ニューラルネットワークの1モデルである多層パーセプトロンで単変数の時系列データ解析を行います。
飛行機乗客数データセットを利用します。
テキストで利用された「線形回帰」「サポートベクトル回帰」「ランダムフォレスト回帰」の結果と比較してみます。
この記事で用いるライブラリをインポートします。
### インポート
# 数値計算、確率計算
import pandas as pd
import numpy as np
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
# データ作成
from sklearn.model_selection import train_test_split
# 描画
import matplotlib.pyplot as plt
from matplotlib import dates as mdates # 描画時の日付編集用
plt.rcParams['font.family'] = 'Meiryo'
多層パーセプトロン(MLP)
多層パーセプトロン(Multilayer perceptron: MLP)はニューラルネットワークの基礎的なモデルです。
今回は入力層 2、1つ目の隠れ層 12、2つ目の隠れ層 8、出力層 1 のモデルです。
テキストでは再帰型ニューラルネットワーク(LSTM)の名称を用いていますが、テキストオリジナルコード「ML_lstm.py」には多層パーセプトロンと表記されているので、この記事も多層パーセプトロンと呼びます。

準備
1.データの読み込み
R 標準データセットの「飛行機乗客数データセット」を使用します。
以下のサイトからデータ取得します。
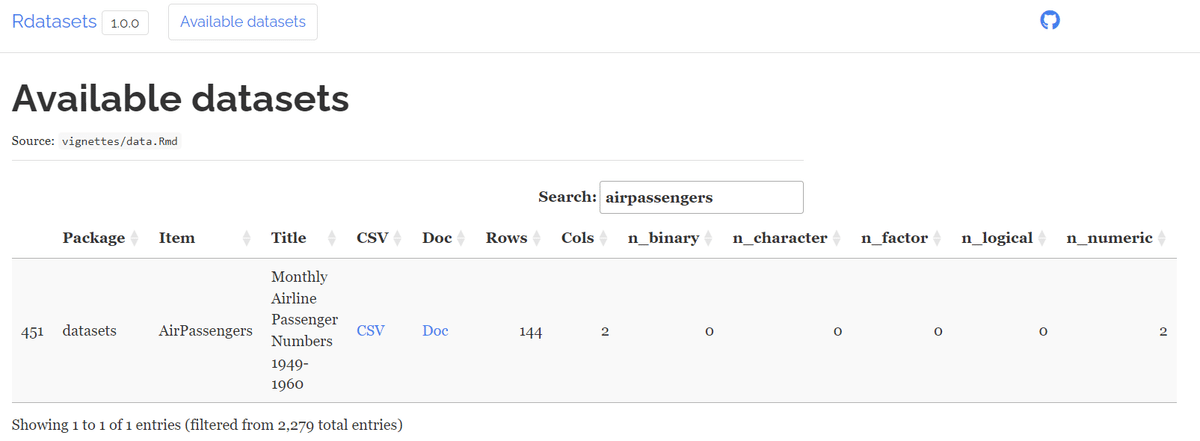
### データの取得
## データの取得・加工
# データセットを取得するWebサイトのURLの設定
URL = (r'https://vincentarelbundock.github.io/Rdatasets/csv/datasets/'
r'AirPassengers.csv')
# データセットの読み込み
data = pd.read_csv(URL, usecols=[2])
# indexに年月日を設定
data.index = pd.date_range(start='1949-01', periods=144, freq='MS')
## データの外観の確認
# データフレームの表示
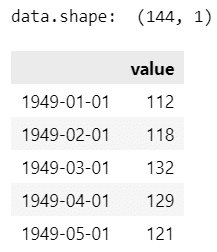
print('data.shape: ', data.shape)
display(data.head())
# データの可視化
data.plot(figsize=(8, 3));【実行結果】
1949年1月から144か月間の月間国際線乗客数(単位:千人)です。

2.ラグ特徴量作成関数の定義
ラグ特徴量を作成する関数を定義します。
テキストの「create_dataset関数」を改造しました。
### データフレームの指定列に対してラグ特徴量を追加する関数の定義
# num_lag期間の説明変数xと翌期の目的変数yを生成
# ★テキストオリジナルコードのcreate_dataset関数と同等
def add_lag_features(df, col, num_lag):
data = df.copy()
for lag in range(1, num_lag+1):
data[f'lag{lag}'] = data[col].shift(lag)
data = data.dropna()
y, x = data[col], data.drop(col, axis=1)
return x, y【実行結果】なし
3.学習データとテストデータの分割
学習データとテストデータを分割します。
### 学習データとテストデータに分割:時系列データ用 ★scikit-learnで分割
# 学習データ0.67,残りをテストデータに分割, 時系列を維持するためシャッフルしない
train, test = train_test_split(data, train_size=0.67, shuffle=False)
# 分割結果の概要表示
print('train.shape:', train.shape)
display(train.head())
print('test.shape:', test.shape)
display(test.head())【実行結果】

4.説明変数の作成
説明変数を「ラグ1とラグ2のラグ特徴量」とします。
### ラグ特徴量を2つ作成して、説明変数xと目的変数yに分離
# 設定
num_lag = 2 # 追加するラグ特徴量の数、テキストは2
# 学習データ、テストデータにラグ特徴量を追加して説明変数と目的変数を分離
x_train, y_train = add_lag_features(df=train, col='value', num_lag=num_lag)
x_test, y_test = add_lag_features(df=test, col='value', num_lag=num_lag)
# 説明変数xと目的変数yの確認
print('x_train.shape:', x_train.shape)
display(x_train.head())
print('y_train.shape:', y_train.shape)
display(y_train.head())
print('x_test.shape:', x_test.shape)
display(x_test.head())
print('y_test.shape:', y_test.shape)
display(y_test.head())【実行結果】


モデルの構築
pytorchでモデル構築します。
1.データセットの作成
pytorchのデータローダを作成します。
### データセットの作成
## 設定
batch_size = 2 # バッチサイズの設定、テキストは2
seed = 1234 # 乱数シード
torch.manual_seed(seed) # 乱数シードの固定
# 学習データセットの作成: dataloaderの作成 ※時系列順序を維持するのでshuffle=False
x_train_tensor = torch.tensor(x_train.values.astype('float32'))
y_train_tensor = torch.tensor(y_train.values.reshape(-1, 1).astype('float32'))
train_dataset = TensorDataset(x_train_tensor, y_train_tensor)
dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
# テストデータセットの作成: tensor化
x_test_tensor = torch.tensor(x_test.values.astype('float32'))【実行結果】なし
2.多層パーセプトロンモデルの構築
### NNのモデル定義
# モデル定義 ※テキストオリジナルコードのMultilayer Perceptron modelと同様
model_nn = nn.Sequential(
nn.Linear(in_features=num_lag, out_features=12),
nn.ReLU(inplace=True),
nn.Linear(in_features=12, out_features=8),
nn.ReLU(inplace=True),
nn.Linear(in_features=8, out_features=1),
)
# モデル表示
print(model_nn)【実行結果】

3.モデルの学習
エポック数 200 の学習を実行します。
検証データは利用しません。
%%time
### NNの学習
## 乱数シード
torch.manual_seed(seed)
## 学習関数の定義
def train_nn(model, num_epochs, dataloader, loss_func, optimizer):
# 学習履歴リストの初期化
loss_history = [0] * num_epochs
# エポック数を繰り返し処理
for epoch in range(num_epochs):
# バッチ数を繰り返し処理
for x_batch, y_batch in dataloader:
pred = model(x_batch) # 1.予測値を生成
loss = loss_func(pred, y_batch) # 2.損失値を計算
loss.backward() # 3.勾配を計算(誤差逆伝播)
optimizer.step() # 4.パラメータ更新
optimizer.zero_grad() # 5.勾配の初期化
loss_history[epoch] += loss.item() # 損失値の一時格納
# 損失値を正す(バッチ数で除算)
loss_history[epoch] *= (y_batch.size(0) / len(dataloader.dataset))
# 500エポックごとに損失値を表示
if (epoch + 1) % 100 == 0:
print(f'Epoch {epoch + 1: >4}, Loss {loss.item():.2f}')
# 戻り値:学習履歴リスト
return np.array(loss_history)
## NNのパラメータなどの設定
# 学習率 テキストはおそらく0.001
learning_rate = 0.0005
# エポック数 テキストは50
num_epochs = 200
# 損失関数 平均二乗誤差
criterion = nn.MSELoss()
# 最適化手法 Adam
optimizer = torch.optim.Adam(model_nn.parameters(), lr=learning_rate)
## 学習の実行
history = train_nn(model_nn, num_epochs, dataloader, criterion, optimizer)【実行結果】

学習曲線(損失曲線)を描画します。
### 損失関数の可視化
plt.figure(figsize=(5, 3))
plt.plot(history)
plt.xlabel('Epochs')
plt.title('学習曲線:損失関数')
plt.grid(lw=0.5);【実行結果】
収束している感じがします。


予測
学習データとテストデータを用いて予測を行います。
### NNの予測
# 予測の実行
pred_train_nn_tensor = model_nn(x_train_tensor)
pred_test_nn_tensor = model_nn(x_test_tensor)
# numpy配列化
pred_train_nn = pred_train_nn_tensor.data.numpy()
pred_test_nn = pred_test_nn_tensor.data.numpy()【実行結果】なし
予測値を可視化します。
テキストの図3.28の「LSTM」の可視化に相当します。
### 学習期間、テスト期間の観測値・予測値の描画
## 描画領域の設定 gridspec(gs)で7分割した領域をax1:4つ、ax2:3つに割り当て
fig = plt.figure(figsize=(10, 4))
gs = fig.add_gridspec(1, 7)
ax1 = fig.add_subplot(gs[0, :4])
ax2 = fig.add_subplot(gs[0, 4:])
## 学習データの描画
# 観測値の描画
ax1.plot(y_train.index, y_train, color='tab:red', lw=0.7, ls='--',
label='観測値')
# 予測値の描画
ax1.plot(y_train.index, pred_train_nn, color='tab:blue', lw=0.9, label='予測値')
# x軸ラベルを年表示に固定化
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
# 修飾
ax1.set(xlabel='年月', ylabel='乗客数[千人]', title='学習データ')
ax1.grid(lw=0.5)
ax1.legend()
## テストデータの描画
# 観測値の描画
ax2.plot(y_test.index, y_test, color='tab:red', lw=0.7, ls='--')
# 予測値の描画
ax2.plot(y_test.index, pred_test_nn, color='tab:blue', lw=0.9)
# 修飾
ax2.set(xlabel='年月', ylabel='乗客数[千人]', title='テストデータ')
ax2.xaxis.set_tick_params(rotation=30)
ax2.grid(lw=0.5)
## 全体修飾
fig.suptitle('NN', fontsize=16)
plt.tight_layout()
plt.show()【実行結果】
テキストの結果と近いと思います。
一定の時間間隔の「横ずれ」が起きているようです。
テキストによると「非定常性のデータをそのまま適用してしまうとデータが有する非定常性を処理できず、見せかけの回帰が起きてしまいます」とのこと。

線形回帰、サポートベクトル回帰、ランダムフォレスト回帰による予測プロットと比べてみます。



これらの予測も見せかけの回帰が起きているようです。
今回の寄り道写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。