
アンケートの回収数と出現率のはざまで。

回収数の設定
おはようございます!
今日は、皆さま気になる回収数の設定についてのお話です。
「どれくらい集めれば正確なの?」
「男女別、年齢別で集めたほうがいいの? 分けないほうがいいの?」
初めてのリサーチだと迷うことがたくさんありますよね。
では、どの程度の回収数を確保すればよいのかについて説明します。一つは回収数、そしてその内訳である割り付けです。
ネットモニター調査での回収サンプル数は通常の書面調査と同様に回収数を事前に設定します。
一般的にアンケート調査で統計的に十分かという議論は、母集団の数に対してサンプル数が十分かどうかという議論に用いられます。
アンケートはサンプリング調査で、調査結果が母集団の姿を反映することが前提で、その誤差が限りなく少ないことが理想です。一般的なアンケートでは、「許容誤差:±5%,信頼レベル:95%、回答比率:50%」を前提にします。
適正なサンプルサイズとは?
サンプルサイズが少ないと誤差が大きくなってしまい、母集団の代表と言えるような結果が得られません。他方で多すぎると、誤差は小さくなるものの調査自体にかかる費用と手間が増えていきます。上記を前提にしたサンプルサイズは以下です。計算式は省略します。
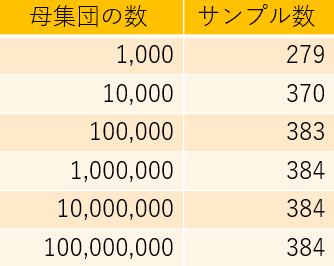
このように回収数に着目すると、サンプル調査ではどのような母集団であっても無作為に抽出する場合には384のサンプル回収で良いと分かります。
他方でアンケート調査では調査結果を属性等により分析すること、一般的にはクロス集計することが一般的であるため、実際の調査では上記より多くのサンプル数を回収します。
その際には分析軸のセルに入る結果の数を前提として回収数を算定しますが、クロス集計をする場合には一般的には100 以上の回答があると各セル間の差異も可視化しやすいと言われています。
この場合、回答1つの差異は1%になります。10の回答しかない場合にはセル間の1の差異は数字上は10%となります。
そのため回収数を増やすことで、より詳細な分析が可能となりすます。ただし分析に必要な回収数には正解があるものではありません。
割り付け設定のポイント
書面調査では不可能なネットモニター調査の特徴の一つは、事前に設定した回収割り付けについて、回収状況をみながら調査期間を延ばすことで、一定程度は確保することがあるということです。
例えば、性別、年齢層、地理的に回答が異なることが予想される場合には、回収状況に応じて当該回収が少ない層の回答が確保できるまで調査を継続して、結果を回収することも可能となります。
そのため調査設計では、この割り付けの設定が重要となります。
基本的に割り付けは母集団の構成費を反映することが重要です。性別、年齢、地域などについては統計情報を参考にして回収数を設定することが可能です。商品やブランド調査ではシェアや販売実績を利用します。
以下は2000サンプルを均等で回収する場合と、
人口比で回収する場合の比較です。

下段は人口比が等しくなるよう割り付けた場合の回収数
しかし、実際の調査ではこのように母集団の構成比がわからない場合も少なくありません。そのような場合には、分析に必要な回収数を前提にして対象層を均等に割り付ける方法や任意に設定する場合もあります。例えば、
例1 <インターネットを通じた出前の利用調査>(合計 500回収)
対象:20~69歳
回収:1000回収
年齢:10歳刻みの男女均等回収(各層は男女50回収)
例2 <自社製品の利用実態調査>(合計 500回収)
対象:自社製品購入者
商品 a=100
b=100
c=100
d=100
e=100
このようにネットモニター調査では事前に回収の割り付けを設定して、回収の確保も一定程度は可能となります。本来的には母集団の構成費を反映することが望ましいのですが、母集団の構成費が特定できないことも少なくありません。そのような場合には分析に必要な回収数を設定します。
ただし、登録されているモニターによっては特定年齢層が少ないというということもあります。
またこれは対象国によっても異なります。
国によっては高齢者が少ないことや、若者層の参加・協力率が高くはないという状況があり、回収分プル数の設定には留意が必要です。
ロジックとは。
ネットモニター調査では、書面調査とは異なり回答の対象者を特定することや、矛盾した回答を事前に排除、制御することが可能です。
例えば。
書面調査では「問1でAと答えた人だけに問2を回答させる」というような場合、矢印などのインストラクションを付けても問1でAと回答した人以外が回答したり、反対に問1でAと回答した人が回答しない場合があります。
その他には毎月の食費が5万円と回答したのに、その内訳では回答した額以上を記入し、合計が合わないなどの矛盾が生じる場合もあります。
このような回答の矛盾を事前に回避するための調査画面でのルール設定を一般に「ロジック」と言います。
ネットモニター調査では、このロジックを設定することで、回答者の導きや、矛盾する回答を回避することが可能です。
例えばこんなロジックがあります。
<1>SAとMAの設定
選択肢を1つ選ぶ場合、2つは選択できないように制御する。
選択肢を複数選ぶ場合、2つは選択でるように制御する。また背反する回答については選択できないようにする。
<2>自由記述の設定
その他などを選択して具体的に記載しなければ次に進めない、あるいは具体的記入は任意とする。
<3>入力数字
入力する数字に矛盾がないかを制御。回答者の就業年数は年齢から義務教育期間を除いた年数の間で制御する。例えば30歳の人は就業年数は15年以下飲み会う可能。全体数と内数は合致するよう制御する。
<4>誘導
「問●でaかbを選択した方のみ回答」の場合、その他の選択肢を選んだ人は回答対象外に制御する。
<5>選択
「利用したことがある物を選択して、そのうち最も利用している物を1つ選ぶ」の場合、利用したことがある物は任意の数を選択可能にし、最も利用している物は利用したことがある物のうと1つと一致する、最も利用したことがある物は1つのみ選択すると制御。
ネットモニター調査の設計時には、書面調査で設定する設問への誘導の他、矛盾する回答が生じないように制御します。
そのため、各選択肢について、SAかMAか、回答対象者は全てALLか特定か、その他数値等の制御が必要かを設問票に記載して、開発担当と協議・調整します。そのうえでテスト段階で制御が正しく作動するかを実施者は最終確認する必要があります。
これにより実施後に、書面調査の分析の前段に行うデータクリーニングは基本的には不要となりますが、それでもなお自由記述を必須と設定した場合には、例えば「あああああ」「あいうえお」といった適切ではない、バットデータが出現する可能性があります。
最後に、出現率について。
出現率IRとは、ネットモニター調査において、対象条件に合致するサンプル数が属性・集団の中に含まれる比率を意味します。
たとえば、18歳以上であれば性別、居住地に関係なく対象とする、という場合、登録モニターが全て18歳以上であれば出現率は100%となります。大卒者や正規雇用者などをターゲティングする場合は統計情報から大学卒比率、約51.9%や正規雇用比率、約62.9%を出現率として設定します。
出現率は回収数の設定や費用の検討において重要な指標になります。例えば年収1000万円超 1500万円以下をターゲティングする場合、統計情報では全体で約3.4%(男性5.2%、女性0.7%)であるため、ネットモニター調査会社の登録モニターのうち対象年齢層の3.4%程度が対象層になると推定できます。
さらに実際の回収では回答率も考慮しなければならないため、さらに回収数、率は低減します。
その他には、公式の統計での裏付けが確認出来ない場合もあります。例えば、毎年帰省している人、年間に航空機の利用が30回以上利用する人、転職を複数回以上している人、などについては関連する情報、例えば帰省の人数や乗車率などの報道情報、航空会社の上級会員数(非公開)、転職に関する調査などを参考にして、確からしい出現率を設定します。
ただし、統計的な根拠があってもそれがモニターとして実際に存在するのか、回答してもらえるかは必ずしも一致しないとうことには留意が必要です。
その他にもう一つ費用について、多くのネットモニター調査会社では、この出現率に応じて回収単価が設定されます。
回答者に対する報酬は一般的には設問数に応じて設定されますが、他方でこの出現率が低いターゲット層についてはレアな対象という理由で、調査実施の困難性から単価が高く設定されます。一般に契約段階で出現率が確認されて単価が設定されますが、事前に想定した出現率が実査の結果、大幅に低下した際には単価が上方修正されることもあります。これはネットモニター調査会社によって異なります。
なおネットモニター調査会社によっては出現率を事前に調査する出現率調査を行っているところもあります。これは5問程度のスクリーニング設問を通じて一般配信を行い、ターゲット層がどの程度存在するのかを確認する方法で、これによって調査の実施可否やコストを事前に確認することが可能となります。
いずれにしても出現率によって回収可能なサンプル数や費用が調整される点についての確認が必要となります。
オンラインリサーチを始めたいと思ったら。
ぜひお問合せください!
お問い合わせはこちらから!