心のバリアを取り去って「正規表現」に取り組む一歩を踏み出すためのメモ
長年、後回しにしてきた「正規表現」。四の五の言わずにはじめようよ!と20年前の自分に伝えたく、まとめてみました。
詳しい方が見ると、乱暴だったり、おかしなところがあると思いますが、入り口に立つことが大切だと考えています(書いた人は文系・グラフィックデザイン関連です)。
はじめに
たとえば、文章中に「コンピュータ」と「コンピューター」が混在していて、これを「コンピューター」に統一したいとき、あなたなら、どうしますか?
単純な検索置換なら、次のような順番で処理できます。
❶「コンピューター」を「コンピュータ」に一括置換する
❷「コンピュータ」を「コンピューター」に一括置換する
❸ ちょっと心配なので「ーー」(音引きの繰り返し)をチェック
これはこれでアリなのですが、1回の作業でできたらベターです。
しかし、「コンピュ-タ」のように正しく音引き(ー)が入力されていない場合には単純な検索置換ではお手上げです。
「正規表現」を使うことで、“チカラワザ”ともいえる検索置換を少ないステップで行ったり、ちょっと込み入ったものにも対応できるようになります。
「正規表現」って?
使ったことがない方でも「正規表現」という言葉は聞いたことがあると思います。
「なんか、スゴいことができそうだけど…」と理屈ではわかっているものの、「そこまではいいや」「そこまで頑張らなくても…」と距離を置いていました。(今でも思うのですが)名称の「正規」に違和感が残りますし。
そんな私ですが、今や知的好奇心の“センター”に君臨しているのが「正規表現」。ようやく全体像やコンセプトを理解でき、試行錯誤しながらですが、現場での仕事に活用できるようになってきたのです。
というか、「正規表現のない人生なんて!!」とまで思っているほど。
そこで、正規表現に対して心のバリアを持っていた昔の自分に対して「最初から、こんなふうに導入してくれたらよかったのに…」と思うメタファー的な説明をいくつか紹介します。
どれかひとつでもピンと来るものがあれば導入のステージに立てます!
[A]正規表現は「スーパー検索置換」である
乱暴にいうと正規表現は「検索置換」です。
しかし、単純な文字列の検索置換ではなく、もっと細かい指定、込み入った指定を行えます。つまり「スーパー検索置換」です。
[B]正規表現は「ワイルドカードの進化系」である
ExcelやファイルメーカーProなどのアプリケーションでは「川*」のように指定することで「川」「川岸」「川遊び」のように「川」で始まる文字列を検索できます。
これを「ワイルドカード」と呼びますが、「正規表現」はワイルドカードの進化系です。
Excelのワイルドカードにはバリエーションがありますが、正規表現では、さらに細かく指定できます。
[C]正規表現とは「パターンマッチング」である
一定の形式や法則を持つものを「パターン」と呼びます。
正規表現はパターンに沿っているもの(=マッチするもの)を指定する表現方法です。
普段、検索やデータの抜き出しなどを行うとき、「あるパターンに沿って単純作業を繰り返してるけど、これ、もっとスマートにできないの?」と感じることがあれば正規表現の出番です。
なお、正規表現によって対象となることを「マッチする」というのは、ここから来ています。
[D]正規表現は「Regular Expression」の日本語訳である
テレビ番組で「レギュラー」といえば、毎回決まって出演する人を指します。規則性のあることが「Regular」(逆は「イレギュラー」ですね)、これを文字列で表現(Expression)する方法が正規表現です。
「RegEx」(リージェックス/レゲックス)や「RegExp」という言い回しがありますが、これは「Regular Expression」に由来します。
また、UNIXなどで用いる「GREP」(グレップ)は「globally search a regular expression and print」の略ですが、この中にも「regular expression」が含まれています(GREPは「g/ここに正規表現(RE)を書く/p」に由来するとコメントいただきました)。
[E]正規表現は「おまじない」である
正規表現では、こんなふうに指定することがあります。
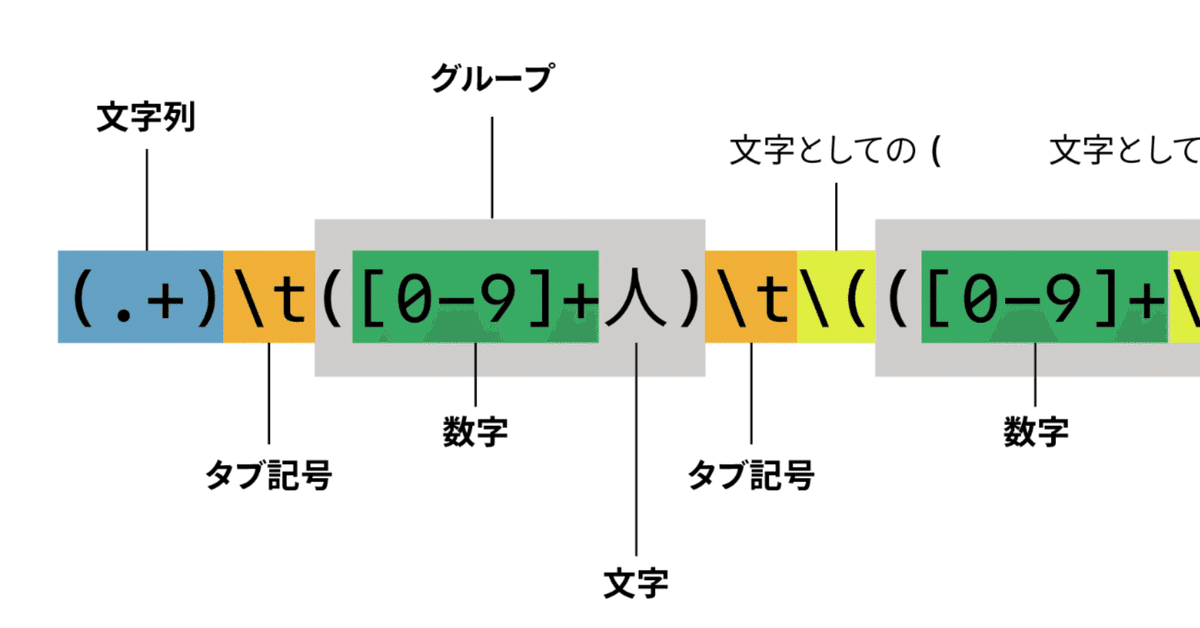
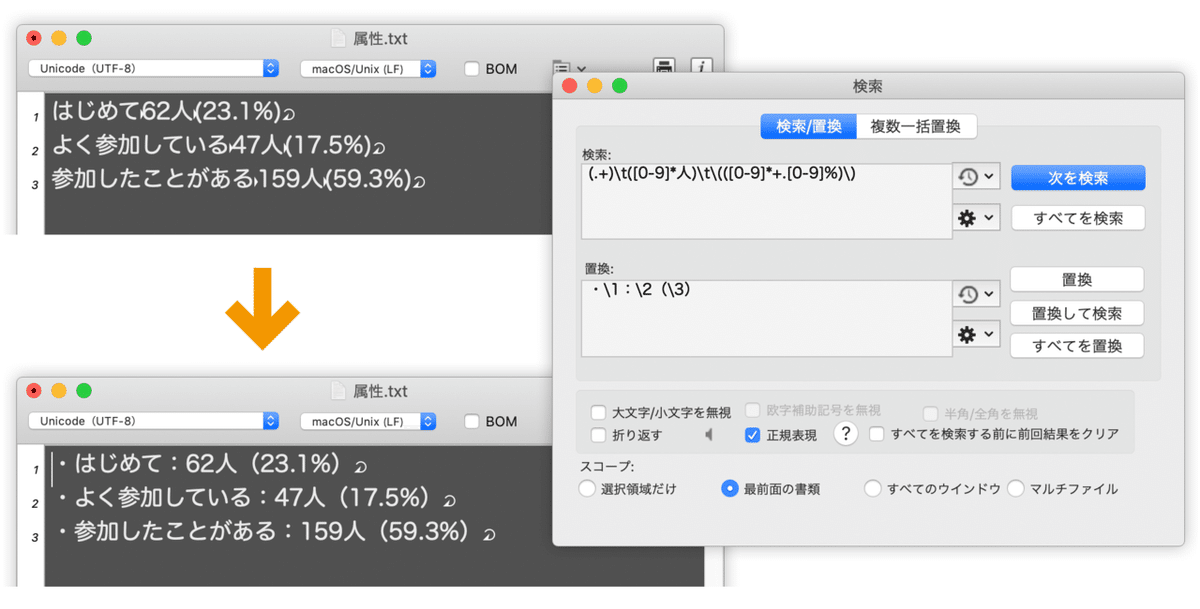
(.+)\t([0-9]+人)\t\(([0-9]+\.[0-9]+%)\)多少、正規表現を使ったことがあっても身構えてしまいますよね… 魔法の呪文!? 正規表現はルールに合致する文字列を指定する「おまじない」なんです。
ちなみに、これは「文字列、タブ記号、数字+人、タブ記号、(数字.数字%、)」という意味なのですが、「人」や「%」などの文字以外は正規表現で指定を行うための記号で、これを「メタ文字」(=メタキャラクター)と呼びます。
なお、正規表現には言語や対応アプリケーションによって「方言」があるのですが、どのような場合でもほぼ共通で使えるのは「. ^ $ [ ] ** + ? | ( )」の記号です。
これらを「おまじない」のための記号でなく、実際の文字として扱う場合には直前に「\」を付けます。そして「\」を付けることを「エスケープする」といいます。
上のサンプルでは()を文字として扱うために\(、\)のようにエスケープしています。
[F]正規表現は「パズル」である
『そろそろ常識? マンガでわかる「正規表現」』という書籍の著者の森 巧尚 さんからいただいたアイデア。
正規表現は最初抵抗ありますが、パズルと割り切れば楽しめますね。
対象となる文字列の規則性を見つけ、それを“おまじない”であるメタ文字を使って指定するというパズルです。
たとえば、さきほど出てきたこの文字列によって、次のような
(.+)\t([0-9]+人)\t\(([0-9]+\.[0-9]+%)\)文字列(実際にはExcelからテキストエディタに移した上で)をまとめて指定できます。

「パズル」と考えると楽しいし、このパズルが解けると、アドレナリンとかその手の物質が分泌されて気持ちいい!
正規表現が使えると、どのように世界が変わるの?
正規表現について書かれたものの多くはプログラマー向け。そこで「自分には関係ない」と思ってしまいます。
それ以外の用途をざっと書き出してみました。
[A]表記統一などの原稿整理(ブラッシュアップ)に役立つ
[B]文字レベルでの赤字の反映をスピーディに行える
[C]InDesignの「正規表現スタイル」を使うことで、指定箇所に自動的に文字スタイルを適用できる
[D]Keyboard Maestroなどのユーティリティにて条件指定を細かく行える
[E]入力値の検証やデータのクレンジングに活用できる
DTP関連では[A]、[B]、[C]あたりですが、どれかひとつでもお仕事に関連がありそうでしたら世界が変わります。
正規表現の初歩(を体験してみよう)
「そこまで言うならトライしてみようかな」と思っていただけるようでしたら、Safariなどのブラウザを起動して<https://rubular.com/ >を開いてみてください。
Rubularというブラウザベースのエディタを使って、実際に正規表現を体験してみましょう。
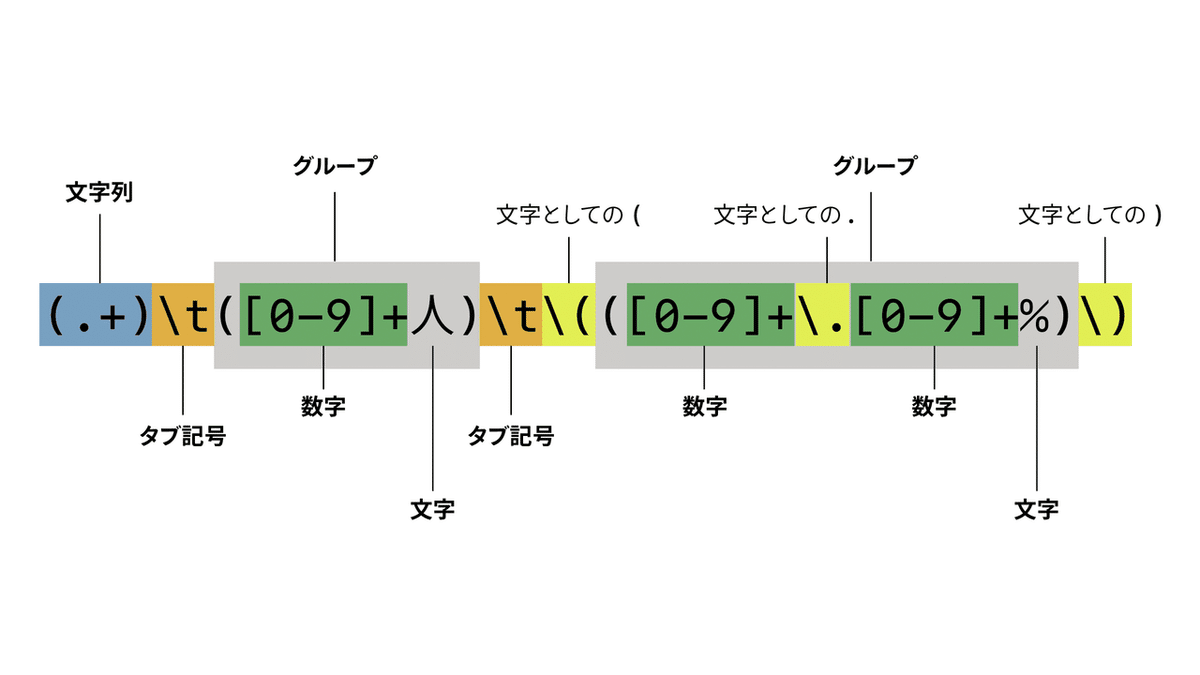
まず、Rubularの画面は、次の3つのパートで構成されています。
①Your regular expression(正規表現を指定)
②Your test string(対象となる文字列)
③Match Result(結果)
---
[Your test string]フィールドに次の文字列をコピー&ペーストしてください。
第1章
第2章
第3章
第4章
第5章
第10章
第11章
第12章
第100章---
[Your regular expression]に「第.章」と入力すると、[Match Result]では第1章から第5章までの5行がハイライトします。
このように指定した条件(「第.章」)に該当することを「マッチする」や「ヒットする」と表現します。
「.」は任意の1文字という意味の記号(メタ文字)です。1文字ですので、第10章や第100章は対象になりません。

---
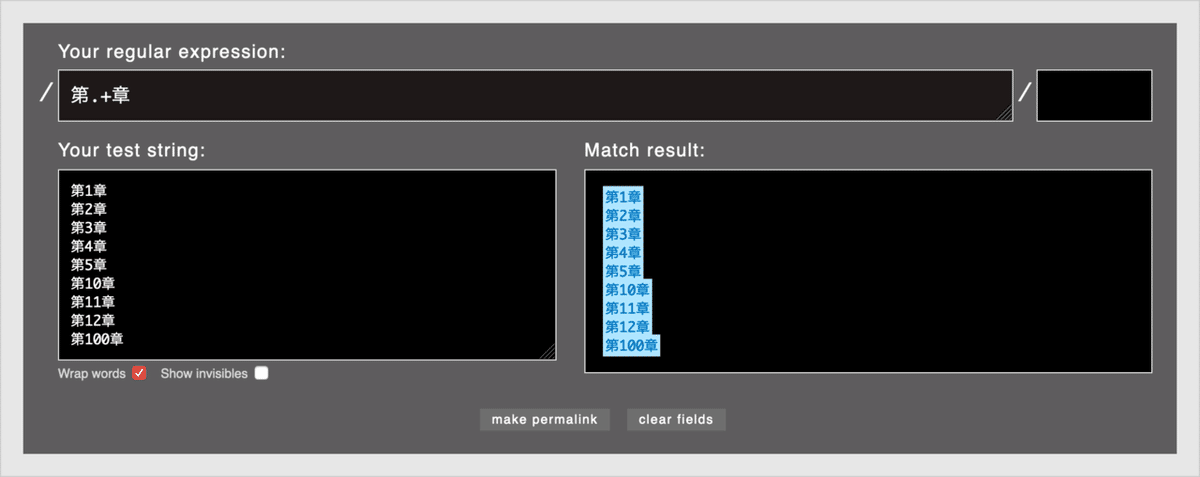
続けて[Your regular expression]に「+」を加え「第.+章」に変更してみましょう。[Match Result]では、第1章から第100章まで、すべての文字列がハイライトします。
「+」は、直前の文字が1回以上繰り返す場合にマッチします。1回以上ですので10も100も対象になります。
---
次に[Your regular expression]に「第\d章」と入力してみましょう。すると、第1章から第5章までがマッチします。
「\d」は「1桁の数字」を表します。「第.+章」と同様、「第\d+章」と記述すれば、すべての文字列がマッチします。

---
次に[Your regular expression]に「第[0-9]章」と入力すると、第1章から第5章までがマッチします。
[0-9]は、0から9の数字のいずれか1文字という意味です。

---
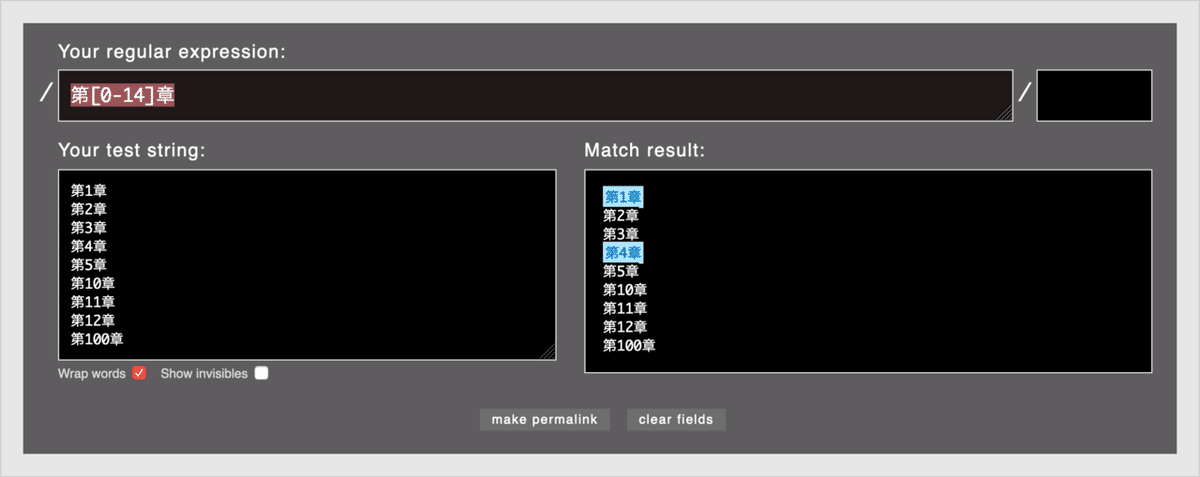
「第[0-14]章」と入力するとどうなるでしょうか?「1から14」ではなく、0から1、そして4が対象になります。つまり「14」という固まりでなく「1」と「4」とみなされてます。トリッキーですね…
---
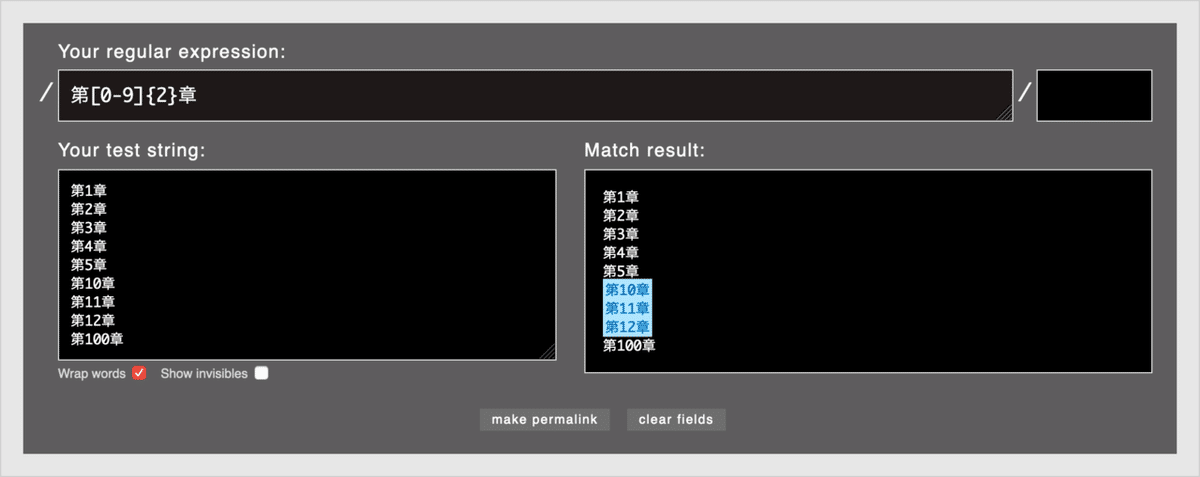
最後に「第[0-9]{2}章」と入力してみましょう。
今度は、「第10章」「第11章」「第12章」がマッチします。
[0-9]は任意の数字、{2}は直前の数字を2回繰り返すという意味です。「第.{2}章」や「第\d{2}章」と書いても同様の結果になります。
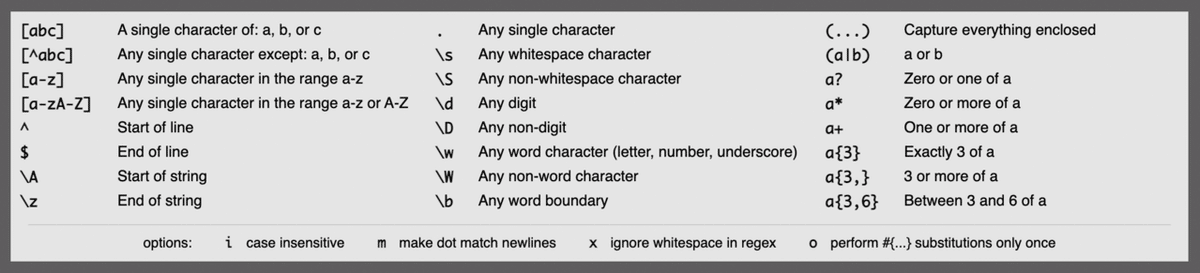
メタ文字
5つのメタ文字を使って正規表現を指定してみました。
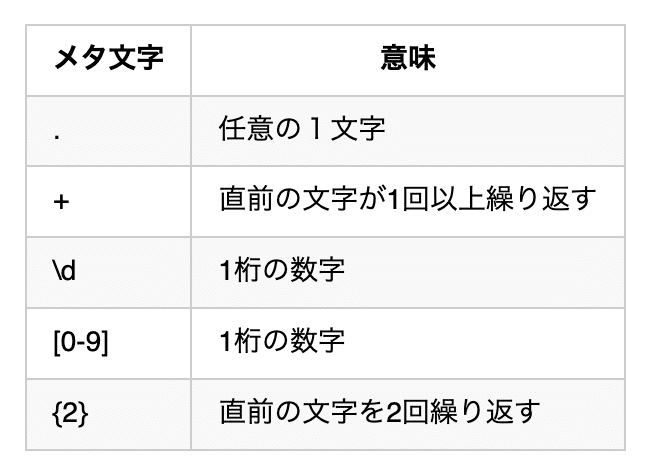
今回のサンプルでは「.」「\d」「[0-9]」は同じ結果になりました。
しかし、「第Ⅰ章」のように数字でない場合、「.」はマッチしますが、「\d」「[0-9]」ではマッチしません。
このように正規表現の記述には異なるアプローチがあり、正解は一つではありません。さらに、例外処理が必要になる場面もあります。
キーワード
次の3つの用語を覚えておきましょう。
・メタ文字(指定に使う文字)
・エスケープする(\を付けるとメタ文字でなく文字として扱う)
・マッチする(指定した条件に合うこと)
メタ文字の種類
メタ文字には、指定の際に構成する「部品」の種類があります。
なんとなく把握しておきましょう。
・文字を指定する部品
・量(個数)を指定する部品:繰り返し数
・位置を指定する部品:行の先頭/末尾、単語の先頭/末尾など
・特殊な指定部品:改行やタブ記号、数字、アルファベットなど
・グループ化するための部品
それぞれを組み合わせて使います。
どうやって勉強していけばいいの?
「正規表現」で検索すると、プログラマー向けの難解なページがたくさん出てきます(これが理解できなくても問題ないですし、また実際、プログラマー以外には関係ないことが多いです)。
重要なのは「こんな処理をしたい、というときに、どんな規則性があるか」の目を持つこと。
規則性(Regular)が掴めたら、それをどう表現(Expression)するのかを考える。そこをスタートに少しずつ試していく、これが正規表現をマスターする近道です。
はてブの方でこんなコメントをいただきました。
ちょっと使いたいときに調べて、少し理解して使って、しばらくたって忘れた頃に使いたいことがあってまた調べて、の繰り返し
私も同じような状況ですが、それで問題ないように思います。ガッツリ勉強してから…でなく、少しずつ使ってみて場数をこなしていくことが大切。
まずは踏み出してみましょう!
チートシート/リファレンス
オンラインで参照するリファランスとしては、こちらが見やすいです。
上記で紹介したRubularの下部に「Regex quick reference」が掲載されています。
ざっくり訳しました。
チートシートというよりチュートリアル的な感じですが、「サルにもわかる正規表現入門」もわかりやすいです。
置換
正規表現は「置換」まで行って完結するとも言えます。
冒頭に上げた「コンピューター」と「コンピュータ」の揺れを「コンピューター」で統一したいの場合には、「コンピューター?」のように正規表現で検索し、「コンピューター」で置換します。

ただし、「ユーザー」と「ユーザ」を対象にするため「ユーザー?」と指定すると「ユーザビリティ」も対象になってしまいます。置換処理は慎重に行う必要があります。この「何かにマッチさせない」指定が面倒です。
また、先に挙げたサンプルでは()によるグループ化を行っています。
これによってマッチしたものを次のように引用できます。単純に1つ目、2つ目、3つ目という意味です。
・\1:\2(\3)
具体的には例としてはこんな感じ。3行だけでも手作業でやるのはナンセンスですし、注意して作業してもミスが残りそうです。
#正規表現知恵袋
「#正規表現知恵袋」のハッシュタグで、実際に現場で役立った(or トライした)ユースケースを元にツイートされていますのでチェックしてみてください。
乗っかってみようという方は、次のフォーマットにて、ぜひツイートされてください!
・ユースケース:(どんな場面で、何をどうしたいのか)
・検索文字列:
・置換文字列:(省略可)
「もっといい書き方がある」「別の書き方がある」とコメントしてくださる方がいるのでありがたいです。
おまけ(1)
このサンプルが「言い得て妙」なのです。
「Windows ってあって…WINDOWSかもしんないしぃ、次にスペースが入ってるかもしんないしぃ、入ってないかもしんないし、後にやっぱ 98 が付くってゆーかー、もしかすると 95 が付いてもいいかなぁって感じでぇ…」
ちょっとわかってくると、「正規表現ならどう書くかな〜」とワクワクしてくることでしょう。
このサイトのこのギャルの表現が秀逸過ぎて、未だにこれを上回る説明に出会えてませんw pic.twitter.com/GdlRQWasr1
— CSS設計完全ガイドの人 / Adobe XD UG札幌代表 / HubSpot CMS Ninja (@assialiholic) March 16, 2021
おまけ(2)
「こんなのもあるよ」と紹介いただきました。
おまけ(3)視覚的に表示する
たくさんの方に読んでいただいているようです。ありがとうございます!
リスペクトしている「したたか企画」さんにコメントいただきました。
正規表現はこの図のようなブロックエディタがあればもっと親しみやすいでしょうね。 https://t.co/6iVrVQvwVP
— したたか企画 (@sttk3com) March 20, 2021
探してみたところ、こんなのがありました。
これに「(.+)\t([0-9]+人)\t\(([0-9]+\.[0-9]+%)\)」を入れると、次のように表示してくれます。英語ですし、日本語がきちんと表示されませんが、むっちゃいいかも。
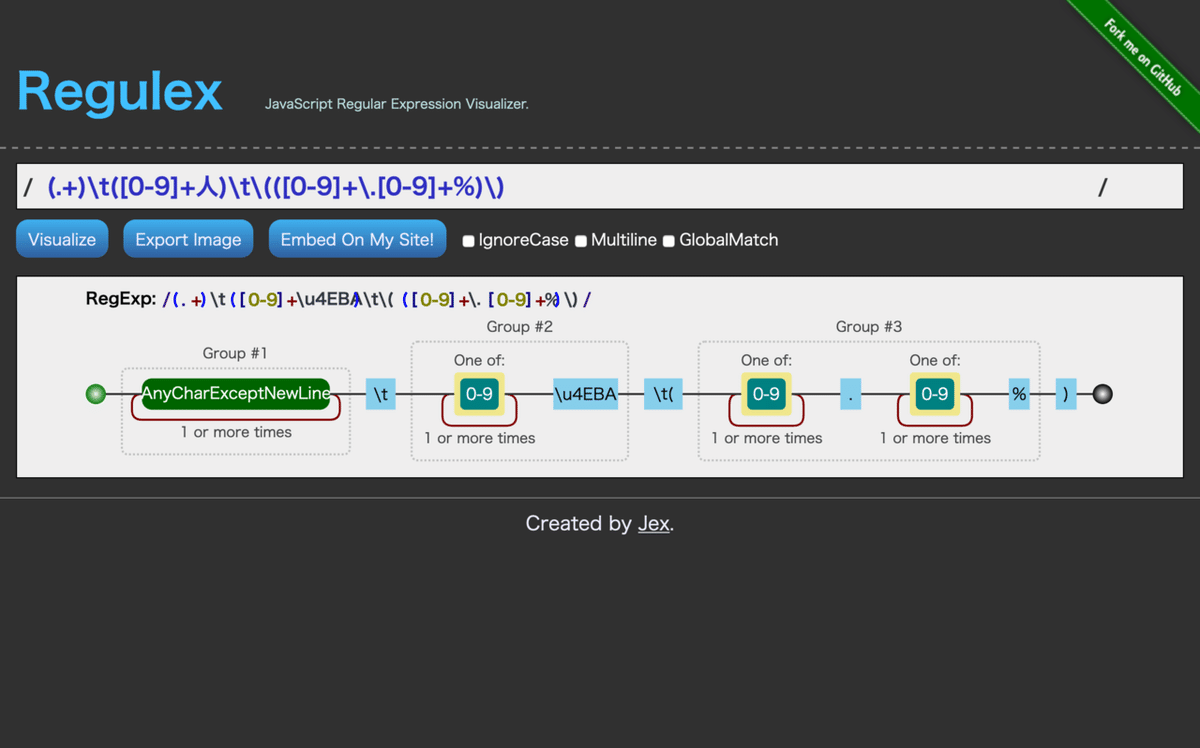
追記(2022年4月14日)
「モンスターを倒しながら正規表現が学べるゲーム」、要チェックです!!
すぐにやってみるなら、こちらから。
ここから先は

DTP Transit 定期購読マガジン
マガジン限定記事やサンプルファイルをダウンロードできます。
定期マガジンを購読されるとサンプルファイルをダウンロードいただけます。 https://note.com/dtp_tranist/m/mebd7eab21ea5