
【エロプログラミング講座#3】例の保存ランキングの動画を自動で保存する

★購入された方へ★
プログラミング言語やライブラリのバージョンの違いによって、当講座のサンプルコードが動作しない場合がございます。お手数ですが、動作しない場合はメールアドレス、コメント、XのDMからご報告していただけると助かります。
基本的に記事を販売している限りはサンプルコードを保守し続けます。
講座内に不明点があり、自力で解決するのが難しいという方は、お気軽に私のプロフィールに書かれたメールアドレスか、コメント、XのDMなどにご連絡いただけますようお願いいたします。
前回の続きです。
エロプログラミング講座#3
6.HTMLの基礎
さて、WEBページから動画なり画像を持ってくるということは、当然WEBページそのものの構造について知らなければなりません。
普段皆さんが目にしているWEBページは一見綺羅びやかにコンテンツを並べていますが、あれらは全てHTMLで構成されています。
言うなれば、WEBページは人間で言うところの外面で、HTMLは人間を構築しているタンパク質や臓器みたいなものです。
百聞は一見にしかずということで、実際にWEBページのHTMLソースを覗いてみましょう。
皆さんが毎日のように利用しているGoogleのトップ画面にアクセスしてみます。

どのPCブラウザでもそうですが、適当にWEBページ上で右クリックすると「検証」または「調査」という項目があります。


クリックすると、以下のようにページのHTMLが表示されます。この画面は「デベロッパーツール」と言います。覚えておきましょう。
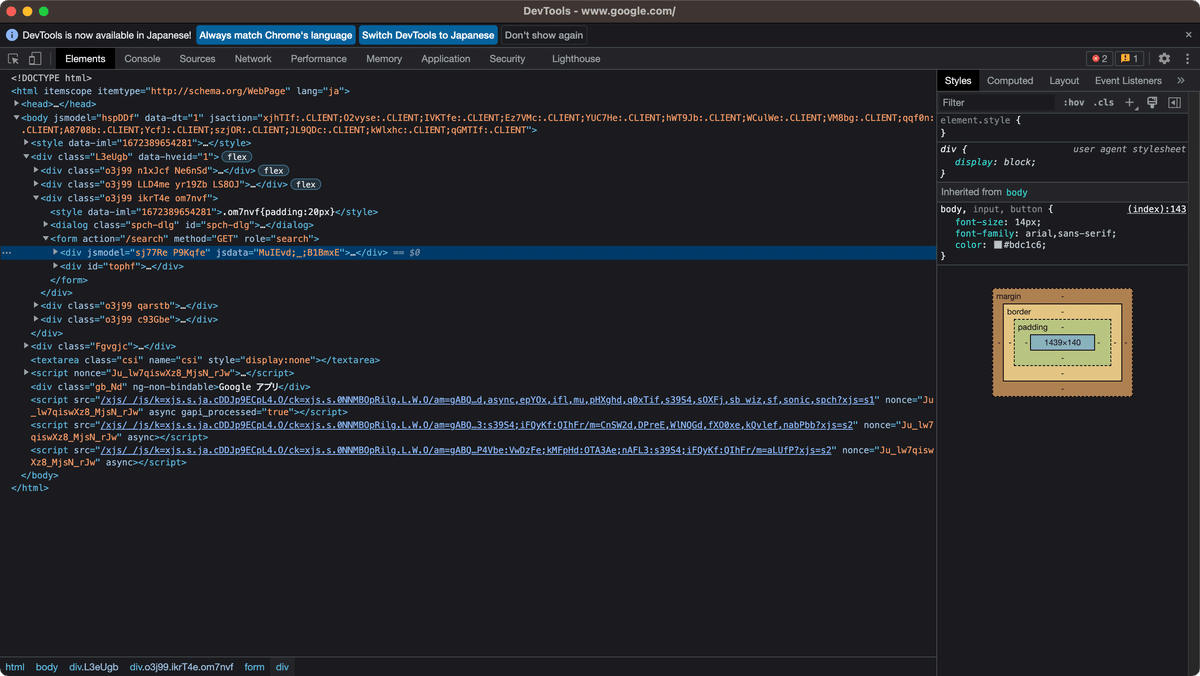
これだけ見ても意味がわかりませんね。
HTMLは「要素」と呼ばれるパーツを組み合わせて作成されています。

青い四角はレイアウト。黄色い四角はテキスト。赤い四角はボタンなど。
緑の四角は画像です。
ページ全体のHTMLを読む意味はありません。必要な部分だけをピックアップしたいときはどのようにすればよいのでしょうか。
デベロッパーツールの一番左上にあるボタンを押すことで、任意の要素を選択できるモードになります。

ボタンを押下した後に、WEBページの検証したい部分にマウスカーソルを当ててください。

また、その要素をクリックすると、デベロッパーツールでも該当箇所がハイライトされます。

こちらはGoogleのトップページのどでかいロゴを選択した結果です。以下の要素で構成されています。
<img
class="lnXdpd"
alt="Google"
height="92"
src="/images/branding/googlelogo/2x/googlelogo_light_color_272x92dp.png"
srcset="/images/branding/googlelogo/1x/googlelogo_light_color_272x92dp.png 1x, /images/branding/googlelogo/2x/googlelogo_light_color_272x92dp.png 2x"
width="272"
data-atf="1"
data-frt="0">スクレイピングをする上で、HTMLの知識はそこまで必要ではないので、
簡単に解説します。
HTMLには「タグ」という、どのような要素なのかを示すものがあります。
「タグ」名は一番初めに書くことになっているので、この場合は「img」の部分がタグ名です。
他にも「div」とか「span」、「video」などの数多のタグがありますが、
覚えなくても問題ありません。
次に、HTMLの要素は「属性」を持っています。
例えば、「img」タグは「ここに画像を表示します」という意味のタグなのですが、じゃあ具体的にどの画像を表示するのか? がHTMLくんには分かりません。
そこで、人間様が「src」属性を用いて画像の場所を指定する必要があります。
あと「class」属性は、その要素につけるグループ名みたいなものです。
なので、「前田敦子」タグにclass属性を付けるとしたら「AKB48」になります。
<前田敦子 class="akb48'></前田敦子>ちなみに、今回のGoogleロゴ画像にはありませんでしたが、
「id」属性という重要なものがあります。
この「id」属性を使うことで、非常に簡単に要素を特定できます。
「前田敦子」タグにid属性を付けるとしたら「maeda_atsuko」でしょうか。
<前田敦子 id="maeda_atsuko" class="akb48"></前田敦子>7.スクレイピング体験
では手始めに、PythonプログラムでGoogleのトップページのロゴを保存してみましょう。
まずはVSCodeを開き、右クリックで新規ファイルを選択します。

ファイルの名前は「google.py」とでもしておきましょう。
「google.py」のトップに、前回紹介したインポート文を書き込みます。

from bs4 import BeautifulSoup
import requests
import lxml次に、これは直接的にWEBスクレイピングに関係するものではないのですが、便利な関数を追加します。
from bs4 import BeautifulSoup
import requests
import lxml
# ---ここから追加---
import base64
def decode_base64(s: str) -> str:
decoded = base64.b64decode(s)
decoded_str = decoded.decode('utf-8')
return decoded_str.strip()前回、僕のキーボードの不具合でhキーが打てないという事態になってしまったのですが、今後も同じことがあると面倒なのでこの関数を使います。
先程も述べたとおり、このコードは別にWEBスクレイピングに必要ではないのでコピーアンドペーストするだけで構いません。

この記事が気に入ったらチップで応援してみませんか?