
医学研究でよく使うpandasコードサンプル

医学研究をしていると、研究で得た大量のデータを処理するのがけっこう大変です。
エクセルに入力した数百、数千列におよぶデータをクリーニングして、SPSSなどの解析ソフトにインポートするのですが、この過程でどうしても人為的ミスが起こることがあります。
そんなとき、Pythonが心強い味方になってくれます!
特に、pandasはエクセルデータの管理をサポートしてくれるライブラリで、データ処理を自動化をしてくれるので、人為的な数え間違い、コピーし間違いを防いでくれます。
この記事では、私がよく利用するpandasのコードサンプルを紹介します。
もっと良い方法がある場合は、ぜひ提案してください。(私はPython初心者ですのでお手柔らかにお願いします)
一緒にpandasのサンプル集を充実させていきましょう!
エクセルデータ読み込み時のTIPS
エクセルファイルを読み込み
import pandas as pd
EXCEL_Path = '読み込みたいファイルの絶対パスをここに入力' #.xlsxを忘れずに!
Sheet_no = '読み込みたいシート名' #読み込みたいシートのインデントを入力することもできる
df = pd.read_excel(EXCEL_Path, sheet_name= Sheet_no)エクセルデータの読み込みは毎回行う処理ですので、もうこのコードをコピペするだけでOKです。
Macでパスを取得するときは"option"ボタンを押しながら、ファイルをクリック→"パス名をコピー"でファイルの絶対パスを取得できます
読み込みたいシートの選択は、シート名でも、インデント番号でもOKです。(3枚目のシートを読み込むときは、sheet_name = 4)
エクセルの特定の列だけ抽出してデータフレームを作成
基本、データを入力したエクセルのすべての列を解析に使用することはないと思うので、解析に必要な列だけ、列名を使って抽出することで、その後の操作が楽になります。
pd.DataFrame() の引数に columns=[] を使って、必要な列を指定します。
df = pd.DataFrame(df, columns =['CENTER_name','Patient_ID',
'Test', 'Result' ])columnsに抽出したい列名を' 'で囲って入力します。
データフレームの先頭行(1行目)を削除
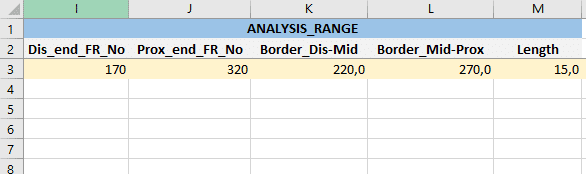
エクセルで1行目だけでなく2行目にも項目名などを入力していると、データフレームの1行目にエクセルの2行目、つまり項目名(この場合、Dis_end_DR_Noなど)が来ることがあります。
この場合、データフレームの先頭行は不要なので、1行目だけ削除したいときは、drop()関数の引数に削除したい行(この場合は0)を入力すればOKです。
df = df.drop([0])特定の名義変数が入力されている行だけ削除
軽度、中東度、高度のような名義変数を軽度=1, 中等度=2, 高度=3と数値化して入力することが多いです。たとえば、中等度と高度の患者さんのデータだけ解析したいときは、軽度、つまり1が入力している行だけ削除しなければいけません。
以下のコード使えば、指定した名義変数が入力されている行だけ削除することができます。
df = df[df['Severity'] !=1] # Severityという名前の列に、1が入力されている行だけ削除データフレームの編集・計算・追加
データフレームの基本的な統計(平均値等)を出力
データフレーム内のデータ数、平均値、標準偏差、中央値といった基礎的な統計はdescribe() 関数を用いると出力できます。
df.describe()ダミーデータの作成
軽度、中等度、高度といった名義変数を、エクセルに入力するときに、1,2,3といった数字で代用して入力することはよくあります。
エクセルのある列に入力された名義変数を、ダミーデータを作ることでその後の統計がしやすくなります。
ダミーデータの具体例をここでお見せします。解離の程度を「なし」、「マイナー」、「メジャー」という3種類の順序変数で入力しています。
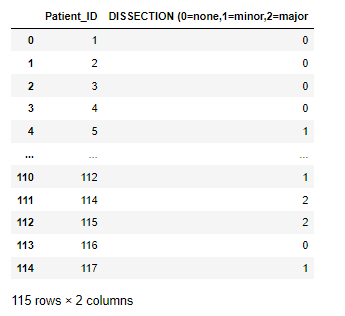
この解離の入力値からダミーデータを作成すると以下のようになります。なし、マイナー、メジャーそれぞれに列を作成し、0 or 1で表示してくれます。
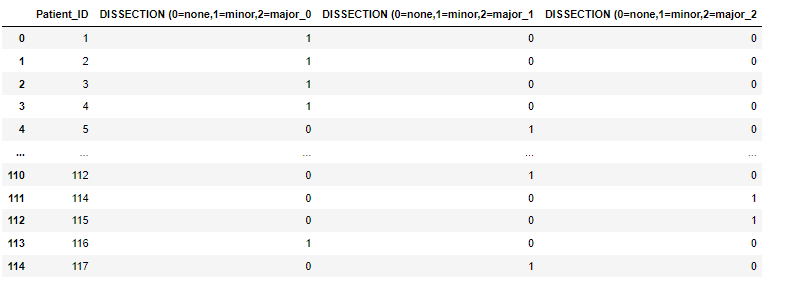
df = pd.get_dummies(df, columns=['ダミーデータを作りたい列名を入力'])患者ごとにデータを集計する
患者さんごとのデータを集計するときに、よく使われるのがgroupby()関数です。
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.html
しかし、groupby関数はデータフレームでなくシリーズを戻すので、集計後もpandasを使って解析を続けるにはデータフレームの形式に戻す必要があります。
そのためには引数に、 as_index=False をいれておくとデータフレームで戻してくれます。
もちろん、グループ分けした後にソートをすることもできます。ソートしたい時は引数 sort=True を入力してください。
df = df.groupby(['Patient_No'], as_index=False, sort=False).sum()
df = df.set_index('インデックスにしたい列名') しかし、もどってくるデータフレームにインデックスがふられているので、set_index('インデックスに指定したい列の名前')を使うと見やすくなります。
各患者が持つ行数を数える
患者さんごとにデータが入力されている行数が異なることがあります(例えば、患者1は50行、患者2は65行、患者3は35行など)。
これを自分で数えるのは手間がかかるので、pandasに自動で数えてもらいましょう。
データフレームに新しい列を追加し、その列のセルすべてに1を入力→ groupby().sum を用いて、グループ分けすると、この1だけ入力した列が患者ごとの行数をあらわすことになります。
df['Total_number'] = 1 # Total_numberという列を新たに作成し、それ列のすべてのセルに1を入力
df = df.groupby(['Patient_No'], as_index=False, sort=False).sum()データフレーム内で列同士使った計算をして、新たに列を作成
軽度のサンプル数、中等度のサンプル数、高度のサンプル数と3列にわけて入力したデータがある場合、各重症度のサンプルの割合を計算することが多いです。
その場合、3つの列の値を足し合わせて、総サンプル数をか計算したり、その総サンプル数を用いて、各重症度のサンプルのパーセンテージを計算したりします。
これらの計算はエクセル側で簡単に計算できますが、pandasの中でも列同士をつかった計算が可能です。
#4列目の値を6列目の値で割って、100をかけた値を計算し、新たな列を作成
df['新しく作る列の名前']= df.iloc[:,3]/df.iloc[:,7]*100[ ]の中はインデントなので、1列目の値をとるときは [:,0] に設定する必要があります。つまり5列目の値を使いたいときは [:,6]に設定します。
今回は割り算をしていますが、もちろん四則演算すべてが可能です。
クロス集計表を作成
データフレーム内のデータを用いて2×2表を作成することもできる。
Cross_table = pd.crosstab(df['解析したい列名1'], df['解析したい列名2'],
margins=True, margins_name='Total',
normalize='columns')margen=True を引数に用いると、合計数を算出してくれる。
normalize=True を用いると、割合(%)を算出してくれる。計算する割合の分母は引数を'all'、 'index'、 'columns'の中から選択することで変更できる。
欠損している患者番号を取得し、データフレームに行を挿入
例えば200人の患者データを解析していて、エクセルに患者番号を1, 2, 3…., 198, 199, 200と患者番号を割り当てているけど、一部の患者は治験から離脱したためデータが欠損していることがあります。
その欠損している患者番号を取得するにはset()関数が便利です。
# 最初に欠損している患者番号を取得
Missing = set(range(1,200))-set(df['患者番号が入力されている列名を入力'])
print('欠損している患者番号は、', Missing,
'です。欠損している人数は', len(Missing),'人です')さらにfor文を使えば、欠損している患者番号のところに、空の列を挿入することができます。
# まず最初に欠損患者用にデータが入っていない列を1列だけ作成。
# 元のデータフレームと結合しやすいように、元データフレームから列名は取得しておく。
missing_rows = pd.DataFrame(columns=df.columns)
# for文を使って、空の行を挿入する
for row in Missing:
missing = pd.DataFrame({'患者番号を入力している列名をここに入力': row}, index=[0])
missing_rows = pd.concat([missing_rows, missing]) # missing_rowsに欠損している患者のみのdfが作成
# 作成した空の行を元のデータベースと結合し、順番をソートする
df = pd.concat([df, missing_rows]).reset_index(drop=True)
df = df.sort_values(['患者番号を入力している列名をここに入力'], ascending=True)見た目の調整
データフレームの列を移動(列の順番を変更)
単純に列の順番を変えるには、iloc[]を使う。
df_after = df.iloc[:, [1, 2, 0, 3, 4, 5]] # 1列目を3列目に移動
loc[]を使って移動させたい列のデータを変数に入力→insert()関数で挿入→drop()関数でもとの列を削除する。
Copy_column = df.iloc[:,0] #1列目のデータをCopy_columnという変数に入力
df.insert(5, column="Copy_Col", value=Copy_column) # 6列目に"Copy_Col"という列を作成し、値を入力
df = df.drop('消したい列名を入力', axis=1)不要な列を削除する
列を削除するときは、drop()関数を用いる。
axis = 0 と設定すれば、行を削除できる。
df = df.drop('削除したい列の名前1', '削除したい列の名前2', axis=1)データフレームの列名の変更
insert()関数を用いることで列名を変更できる。
df = df.rename(columns={'変更前の列名':'変更後の列名'})指定した列をインデックスにする
エクセルに出力すると、インデックスがA列(一番最初の列)になるので、出力する前に設定しておくと仕上がりが見やすくなります。
df = df.set_index('指定したい列の名前')列を指定して、すべての行をソートする
患者番号や検体番号順にデータ全体をソートするときには以下のコードが便利です。
df = df.sort_values(['ソートしたい列名'], ascending=True)エクセルへの出力
エクセル出力時、データフレームごとにシートを作成
複数のデータフレームを、一つのエクセル、つまり複数のシートに出力するにはExcelWrite()関数を用いる。
with pd.ExcelWriter('biomag_Summary.xlsx') as writer:
df1.to_excel(writer, sheet_name = '1つ目のシートの名前を入力')
df2.to_excel(writer, sheet_name = '2つ目のシートの名前を入力')指定した列のデータをマッチさせて、複数のデータフレームを結合する
merge()関数を用いることで複数のデータフレームを指定した列の値であわせて、結合できる。
df_combine = pd.merge(df1, df2, on='Patient_ID')
df_combine = pd.merge(df_combine, df3, on='Patient_ID')
以上、私がいつも研究用に使っているpandasコードサンプルでした。
今回の方法が、pythonを用いて研究をしている皆さんに役立つことを願っています。
また、私のブログでは今後もAIサービスやミュンヘンの状況などを書いていく予定です。アウトプットの励みになりますので、スキ、フォローをよろしくお願いします。
これまでに書いた記事一覧はこちらからご覧いただけます。
https://note.com/doctor_u/n/nacb6a14e1a53
この記事が気に入ったらサポートをしてみませんか?