
深層学習で洋服の写真を並び替え(回帰アプローチ)|札幌の長期インターンシップインタビュー

私たちダイアモンドヘッド株式会社ではファッションアパレルに特化した商品情報を管理する自社サービスを展開しています。
サービスの中では商品に紐づく写真を多数管理しており、写真は規則に則って順序付け(並び替え)された状態でショッピングモールやショッピングアプリへと写真を含めたデータが配信されてます。
今回の記事は、商品画像の並び順を深層学習を用いて自動化する実験を主に長期インターンシップ参加者と新卒入社数名で取り組んだレポートを記事化しました。
参加したインターンシッププログラム
以下、レポート本文です。
1. 背景
現状では、弊社運営のスタジオで撮影した画像をお客様が閲覧できるようになった後、ECサイトにおいて表示したい画像の並びになるよう人手で並び替えを行っている。 しかし、全商品の全画像を手動で並び替えるのは非常にコストが大きい。
2. 目的
「1. 背景」で述べた画像の並び替えを、近年注目を浴びている人工知能技術である「深層学習」を活用して、自動で高速に行うことを試みる。
「レギュレーションに基づく画像ソート」(以下、本タスク)とは、与えられた画像群内の画像を任意のレギュレーションに基づいて並びかえる(ソート)することである。
例えば、以下のようなレギュレーションのもとで入力となる画像群が与えられたとすると、その画像群内の画像を、「バック」が写っている画像は最初に、「洗濯タグ」が写っている画像は最後に、「袖」が写っている画像は中盤に、というように並び替えることを言う。

3. アプローチ
本タスクへのランキング問題としての私のアプローチについて概要を述べる。(分類問題としてのアプローチは別記事を参照。)
画像が入力として与えられた際に、その画像が所望のソートされた画像順列内でどの位置に存在するかを機械学習モデルに予測させたいと考えた。
よって、所望の画像順列の最初を0、最後を1としたときに、画像順列内においてどの程度の位置にあるのかを、入力画像に対してスカラー値を出力させることによって予測させることとした。
例えば、以下のような例であれば、「バック」が写っている画像は「0」を、「裾」が写っている画像は「0.375」を、「ブランドタグ」が写っている画像に対しては「0.875」をそれぞれ出力させたい。
以降、このTargetとなる値のことを “Percentile Rank” と呼ぶこととする。画像群内の全画像に対してこの ”Percentile Rank” を予測させ、その予測値を昇順にソートすることによって、ソートされた画像順列を得る。

つまり、機械学習モデルに対しては、以下のように、画像を入力としてその画像に対する “Percentile Rank” を出力させる。

この機械学習モデルを構築する手法として、近年、自然言語処理や画像認識の分野で注目されている深層学習を用いる。
4.有用であり得るデータ
本実験環境において、本タスクに対して有用であり得るデータは以下である。
商品の画像データ(JPG) ※必須
商品の品番
各商品に登録されている画像枚数
画像内のアイテムがその商品のメインカラーか否か
画像内のアイテムのカラーコード
行った実験ごとに用いたデータが異なるため、上記のうち、使用したデータについては後ろの節で改めて述べることとする。
5. アーキテクチャ
深層学習においては、ライブラリで公開されている事前学習済みモデルに、ユーザが解きたいタスク(今回では回帰に帰着させた画像ソート)に合った「ヘッド」を組み合わせ、それらの内部パラメータを最適化する(学習する)ことによって、所望の結果を得ようとするのが一般的であるため、今回についても同様の手法をとることとする。
今回はヘッドとして事前学習済みモデルから得られる特徴量ベクトルをPercentile-Rank(スカラー)に変換する一層の全結合層を用いた。
ヘッドとして考えられるものとしては、CNNやTransformerなど無数にあり、その総数も大量に考えられるため、今回は実験していない。実験の結果わずかに性能が向上することも十分に考えられる。
事前学習済みモデルとしては、以下のモデルを試し、総合的に見て最も性能のよかった “Swim Transformer-base” を採用した。
EfficirentNet-B5 (effnet のうち、真ん中よりちょっと上のモデル)
EfficirentNet-V2-M (effnet v2 のうち、真ん中のモデル)
Convnext-base (Convnextのうち、真ん中のモデル)
Convnext-large (Convnextのうち、大きめのモデル)
Convit-base (Convit のうち、真ん中のモデル)
Swim Transformer-base (swin-transformerのうち、真ん中のモデル)
Swin Transformer-V2-base (swin-transformer-v2のうち、真ん中のモデル)
また、これらの事前学習済みモデルをダウンロードする際に使用したライブラリは “Pytorch Image Models (通称:timm)” である。
ただし、時間がなく、データが増えてはそれで学習しを繰り返していたので、モデルの性能を比較できるようになってはいるが学習に用いたデータはバラバラである。
具体的にどのような学習をしたのかは後の節で述べる。
また、乱数のSeedを固定していないものもあるが、それぞれ損失曲線を確認しある程度収束したところで学習を終わらせている。
まず、EfficientNet-B5、EfficientNet-V2-M、Convnext-base、Convnext-largeを比較するため、YシャツとTシャツの商品について、各商品のメインカラーの画像のみのデータで実験した結果が以下である。

以上より、convnext-largeが学習の収束が早くスコアもいいという観点から最も性能が良かった。
次に、そのconvnext-largeとconvit-base、Swin-Transformer、Swin-Transformer-V2を比較するため、パンツの商品について、各商品のメインカラーの画像のみのデータで実験した結果が以下である。

以上より、Swin-Transformerが最も性能が良かったため、今回のタスクのための事前学習済みモデルとして採用した。
5.1 画像に対する前処理について:
画像に対する前処理は、事前学習の際に行った処理と同じものをしている。これはtimmライブラリを用いて簡単にできる。
今回採用したSwin Transformerにおいては、画像を384×384にリサイズし、Pytorchのテンソルにしたのち、以下のような正規化を行っている。これは事前学習の際に用いられた “Image Net” における画像のRGBの平均値と標準偏差を用いている。

6.実験と考察
今回、行った実験は以下の3種類である。
・実験1: メインカラーのみの全Tops
・実験2: メインカラーのみのPants
・実験3: メインカラーとサブカラーのTops
ここで、全トップスとは、以下のカテゴリすべてを含む。
Yシャツ
Tシャツ
ワンピース
シャツ
ニット
ムートンコート
カーディガン
テーラードジャケット
ブルゾン
カバーオール
ベスト
その他スーツ
セットアップ
パーカー
ダウンベスト
タンクトップ
ダウンジャケット
ルームウェア
その他トップス
カットソー
ポロシャツ
モッズコート
ブラウス
インナー
レインコート
その他アウター
以下、それぞれの実験について、その詳細と評価について述べる。
また、全実験について、Trainの損失としてL1ロス、Evalの評価関数としてKendall-tauの順位相関係数を用いている。(L1ロスは小さければ小さいほど良く、Kendall-tauの順位相関係数は1に近ければ近いほど良い。)
6.1. 実験1: メインカラーのみの全Tops
本実験では、全Topsに対して、以下のようなレギュレーションでの画像ソートを試みた。

また、「3. 有用であり得るデータ」で述べたデータのうち、「商品の画像データ(JPG)」と「商品の品番」「各商品に登録されている画像枚数」を用いており、「各商品に登録されている画像枚数」を利用して、商品に紐付けれられている総画像枚数が10枚以下のものを抽出し、「商品の品番」を利用して、品番数 1008品番、全画像枚数 5665枚からなる訓練(Train: training)用データと、品番数 253品番、全画像枚数 1409枚からなる検証(Eval: Evaluation)用データに分割した。(Train : Eval≅ 0.8 : 0.2)
機械学習モデルへの入力から出力を得るまでの流れは以下のようになっている。

また、学習は 20epoch 行った。Trainの損失は以下のようになった。最適化のステップを重ねるごとに徐々に損失が下がっており、学習が進んでいることが確認できた。

Evalの損失は以下のようになった。1epoch目から0.97を超えており、それ以降は小数第三位での改善しか見られないため、数epoch程度の学習で十分なように思われる。

考察:Evalutationに用いた 253品番中 230品番 で正解データとモデルの予測が完全に一致。残りの23品番では、どこかしら間違っていた。
その23品番のうち、機械学習モデルがどのような順列を出力しているかを可視化したところ、「商品の正面からの商品画像と裏からの商品画像をうまく認識できていない」という間違いが数品あったが、ほとんどは人間でも判断が難しいような「特徴カット」付近で間違いが頻発していることがわかった。その例を載せる。
例えば、以下の商品では、「後ろから撮った襟より」の画像を、商品の表裏をうまく認識できておらず、「特徴カット」ではなくおそらく「襟より」の画像として認識しているように見える。
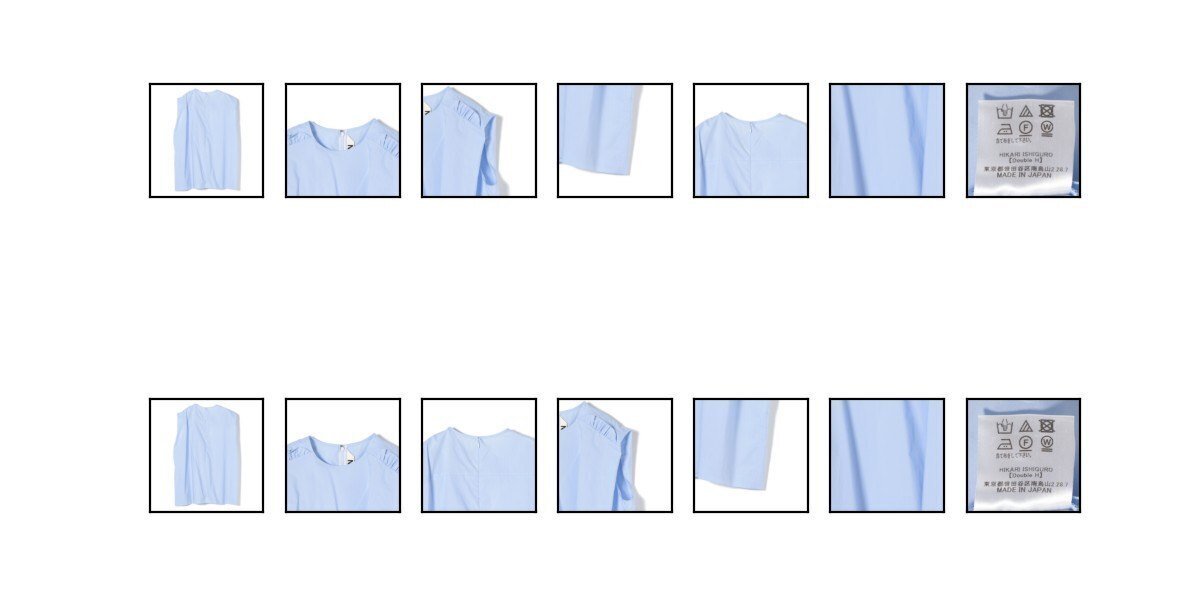
以下の2品番は人間でも難しいような「特徴カット」か否かの識別を間違えている例である。


以上より、メインカラーのみのTOPSについては、非常に良い性能が出ており、間違いも人間でもかなり判断を迷うものが多かった。
6.2. 実験2: メインカラーのみのPants
本実験では、全pantsに対して、以下のようなレギュレーションでの画像ソートを試みた。

実験1と同様「4. 有用であり得るデータ」で述べたデータのうち、「商品の画像データ(JPG)」と「商品の品番」「各商品に登録されている画像枚数」を用いており、「各商品に登録されている画像枚数」を利用して、商品に紐付けれられている総画像枚数が14枚以下のものを抽出し、「商品の品番」を利用して、品番数 385品番、全画像枚数 2715枚からなる訓練(train: training)用データと、品番数 97品番、全画像枚数 677枚からなる検証(Eval: Evaluation)用データに分割した。(Train : Eval≅ 0.8 : 0.2)
また、学習は20epochで行った。
Trainの損失は以下のようになった。最適化のステップを重ねるごとに徐々に損失が下がっており、学習が進んでいることが確認できた。

Evalの損失は以下のようになった。3epoch目から0.92後半の値に若干収束した後、7epoch目で0.94を超えるような急激な改善が見られ、それ以降は0.93〜0.94を行き来するような結果になった。

考察:Evalutationに用いた 97品番中 77品番 で正解データとモデルの予測が完全に一致。残りの20品番では、どこかしら間違っていた。
その23品番のうち、機械学習モデルがどのような順列を出力しているかを可視化したところ、TOPS同様「商品の正面からの商品画像と裏からの商品画像をうまく認識できていない」という間違いが多く、すなわちレギューレーションのうち、「ウエスト寄り」と「バックウエスト寄り」を間違えたり、「バック」「ひっくり返した表」「ひっくり返した裏」を間違えたものが多かった。その例を以下に載せる。



これらの間違いへの対策として簡単に思いつくものとしては、例えば、各画像に対して、「商品を表から撮ったか後ろから撮ったかを表すフラグ」のようなものを用意し、機械学習モデルに入力する特徴量として追加することなどが考えられる。
6.3. 実験3: メインカラーとサブカラーのTops
本実験では、サブカラーも含むTシャツ・Yシャツに対して、以下のようなレギュレーションでの画像ソートを試みた。

レギュレーションを見るとわかるように、実験1および実験2では含まれていなかったサブカラーを含めたレギュレーションにした。
ただし、サブカラー内の順番(例えば、サブカラーに赤と青があるとき、どちらをさきにならべるか)は定義しておらず、無秩序になっている。
また、本実験では、「4. 有用であり得るデータ」で述べたデータのうち、「画像内のアイテムがその商品のメインカラーか否か」を特徴量として追加することとした。
さらに、本実験ではこれまでのように画像枚数に閾値を設けてデータを抽出するのではなく、サブカラーが2色以内の商品(すなわち、メインカラーと合わせて最大三色)のみを抽出したため、商品ごとの画像枚数のレンジに対応するために、「各商品に登録されている画像枚数」も特徴量として追加した。
以上を踏まえ、機械学習モデルへの入力から出力を得るまでの流れは以下のようになっている。

訓練の損失は以下のようになった。これまでと同様、最適化のアルゴリズムにしたがって訓練Lossは落ちていく。

検証ロスは以下のようになった。学習時間がなかったので、発表時点では収束するまで回しきれていないが、実験1,2よりはるかに悪いことがわかる。

考察:評価に用いた412品番中 204品番 で正解データとモデルの予測が完全に一致。残りの208品番では、どこかしら間違っている。
原因は、画像にうつっているものがメインカラーの画像か否かをうまく認識できていないからであると予測される。例を以下に示す。


商品の形状に引っ張られすぎており、メインカラーか否かを追加した特徴量のみでは識別できない。一方で正解しているものは以下のようなもので簡単なものが多かった。


単色カラー内での並び替えを目的としたPercentileRankを予測する回帰を、複数カラー内での並び替えに特徴量を追加して無理やり適用したが、結果はあまり良くなかった。
複数カラー内での並び替えには、それに適したモデルを開発するほうが適切であると思われる。
7. まとめ:
シングルカラーに対しては、完全ではなくとも十分な性能が発揮できると考えられる。
一方で、複数カラーに対しては、単純なフラグを特徴量として入力するだけでは対応しきれず、別のアプローチを開発する必要があると考える。
[参考] Percentile Rank:

[参考] Kendall-Tauの順位相関係数:
ソート結果を評価する方法としてはKendall-Tauの順位相関係数を用いた。以下がその簡単な説明となる。

Pairwise的なアプローチ(後発):
Percentile Rankを予測する回帰モデルの後発機として、Pairwise方式のソート手法を開発した。
その概要を簡単にまとめたものが以下となる。

本プロジェクトで開発したPercentile-Rankを予測するモデルでは、画像1枚のみをモデルに入力するものであった。
一方で、このPairWise方式では、2枚の画像をモデルに入力し、どちらの画像が前にくるかを予想させることを、n枚の画像に対して nC2 回 行いソート結果を得るものである。
深層学習の知見がある方への補足
コードはすべて、Pytorchを用いて記述しています。Hugging faceのTrainerは使っていません。
実用環境を鑑みて、Cross Validationは、品番による Group Shuffle split を行っています。また、これも時間の都合上5foldに分けたうちの1つのfoldでやっています。
Scheduler を使っていません。自然言語処理の分野では、Schedulerを使うのが定番だと思いますが、Computer Visionの分野ではどうなんでしょうか? KaggleなどのWeb上ではSchedulerを使っていないものも散見され、こちらの実験では、Schedulerを使わないほうが性能が良かったので外しました。
混合精度学習(amp.autocast)を用いています。
DropoutとMulti Sample Dropoutを試しましたが、時間がなかったのと、なしでも十分な性能が出ており過学習の兆候がみられないので、結局つけていません。
モデル内の一部のパラメータ更新を行わないような、いわゆる「凍結 (freeze)」は行っていません。
勾配蓄積をもちいています。
さらなる過学習対策としてAdversarial Weight perbutationを検討してもいいかもしれません。
optimizerはAdamWを使っています。
インターンシップに興味をお持ちの方へ
募集要項や応募選考フローや良くある質問などの情報を長期インターンシップ募集サイトにまとめました。興味をお持ちの方はリンク先をご確認下さいますようお願いします。

ダイアモンドヘッドの公式LINEアカウント
LINEアカウントを友達登録すると、チャットを利用しての個別相談や限定イベントへ参加できます。以下リンクから友達追加が可能です。
以上となります。ご拝読ありがとうございました。