
フリーソフト&ノンコーディングでWebページ掲載情報をスプレッドシートに自動的に取り込む方法 ~importxml()関数編~

WebページのデータをGoogle スプレッドシートに自動的に取り込む小技をまとめます。
本記事では、この小技を日経BP SHOPのバックナンバーページで試してみます。
非エンジニアでも十分できると思うのですが、少しHTMLの知識があった方がよいです。
もっと手っ取り早くという方には、こちらのテキストエディタと正規表現を利用したやり方が参考になるかもしれません。
概要と強み/弱み
Googleスプレッドシートを使ったことはあるでしょうか?
Webブラウザで操作できるExcelシートみたいなやつです。Excelで使える代表的な関数(sumやaverageなど)はもちろん、ピボットテーブルやグラフも使えるので、複数人でデータを共有しながらまとめる時には非常に便利です。
そんなGoogleスプレッドシートですが、インターネット接続を前提としたWebブラウザアプリならではの関数がいくつか存在しています。 その一つがURLを指定してWebページ上の情報を取り込めるimportxml()です。
このimportxml()にデータを取り出したいWebサイトのURLと、データのXPathを指定すると、スプレッドシートに自動的にデータが取り出されます。
要は、WebサイトのHTMLタグを頼りに、必要なデータを見つけ出して一覧にしてくれる機能なのです。
強みとしては、HTML上の記載がキチンとしていれば、一括で1行1データずつ、整理された情報を抽出してくれること。
こちらの記事のように、記事タイトルと著者名を手で仕分けする必要はなくなります。
ただ、大きな弱点もあったりします。
一つは、データ抽出に2〜3時間かかる場合があること。
理由ははっきりとわかりませんが、Googleサーバーの方でこの関数の実行に頻度や更新タイミングなどの制約をかけているということを書いているサイトがありました。Googleの公式ドキュメントには、そうした記載を見つけられなかったので事実かどうかはわかりません。
Googleニュースページを対象に、この関数を実行させたことがあるのですが、確かに更新に2時間程度かかるような印象でした。
もっとも、時間がかかる以上に問題だと思えるのは、更新中のセル表示がLordingではなく、#N/Aになることです。関数の書き方を間違えたのか、待ち状態なのか、判断がつかないのがちょっと辛いです。
さらにもう一つの弱点は、この関数を受け付けないページがあること。
例えばこちらのハーバード・ビジネス・レビューのページではエラーになってしまいます。このページに対してGAS(Google Application Script)を使ってデータ取得コードを書いてみたところ、そもそもJavascriptに対するアクセスエラーと思しき情報を返してきていました。
Webスクレイピング避けのような設定をしているページでは、関数が働かないのかもしれません。
importxml()の使い方
importxml()は、その関数名の通りXMLやHTML、CSVなど、Web上のさまざまな種類の構造化データから情報を取り出すことができるGoogleスプレッドシートの関数です。
IMPORTXML({URL}, {XPathクエリ})
[参考] IMPORTXML - ドキュメント エディタ ヘルプ
この関数を使いこなすのに、HTMLとXPathの知識が必要になります。
XPathを確認する
XPathは、XML形式の文書から、特定の要素や属性を指定するための書き方です。 HTMLの場合は、タグやクラス名から要素を指定します。
[参考] XPath Tutorial
XPathを確認するには、ブラウザの機能を使うと楽です。 Chromeでは下記の通り確認できました。
1.XPathを確認したいリンクを右クリック。「検証」を選択。
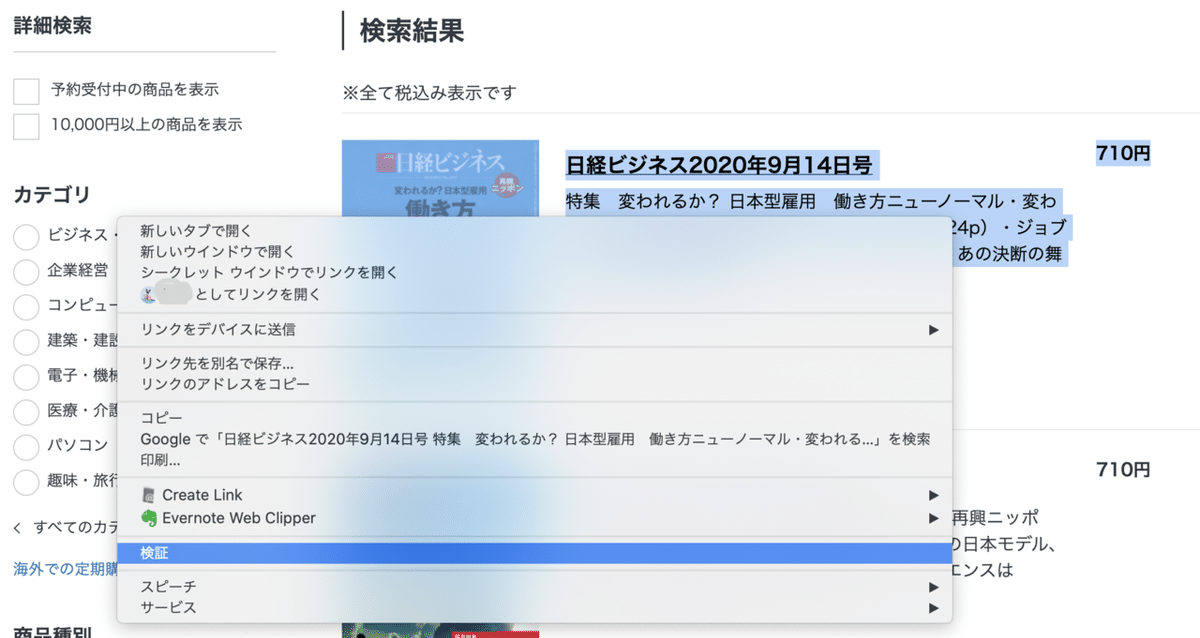
2.右側に表示されるページの該当箇所のHTMLソースを確認。

「検証」をクリックした箇所を中心に、HTMLのソースを開いてくれているので、抽出したい情報がどんなHTMLタグを使用して書かれているか確認します。
雑誌の発行年月日とコンテンツ見出しが書かれた箇所は、こんな記述です。
<h3 class="list-hdg">日経ビジネス2020年9月14日号</h3>
<p class="list-txt-outline is-sp-none">特集 変われるか? 日本型雇用 働き方ニューノーマル・変われるか? 日本型雇用 働き方ニューノーマル(024p)・ジョブ型、在宅、単身赴任解消、副業 もう戻らない! あの決断の舞台裏(026p)・独自</p> それぞれ、h3タグ、pタグが使われており、クラス名もあてられていることがわかります。
この情報を元にXPathを書くと下記の通りです。
//h3[@class='list-hdg']/text()
//p[@class='list-txt-outline is-sp-none']/text()
HTMLソースに対するXPathの基本的な書き方
<基本>
・HTMLでは<html>から各タグが入れ子になっています。入れ子の一番外側のタグから順番に記載します。
・入れ子状態の全てを記述する必要はなく、’//'で省略可能です。
・タグ名だけでなく、クラス名、IDなどを指定することで、要素を効率よく指定することができます。
<主な文法>
nodename ・・・特定したい要素名。HTMLタグ(h2,h3,p,a)などが相当します。
/nodename ・・・nodenameの配下を指定します。
//nodename ・・・nodename以前のノードの省略。
@nodename ・・・アトリビュートの指定。よく見かけるHTMLタグ<a href="〜">でいうと、aがnodename、hrefはアトリビュートになります。
/nodename/text() ・・・nodenameの要素をテキストとして抽出します。
ちなみに要素の右クリックメニューからXPathをコピーすることもできます。
「Copy」を選んで、さらに「Copy XPath」か「Copy full XPath」をクリックすると、選択した要素のXPathがコピーできるのですが、この方法で取得したXPathではimportxml関数がうまく動かないことが多いです。
Googleスプレッドシートでの書き方
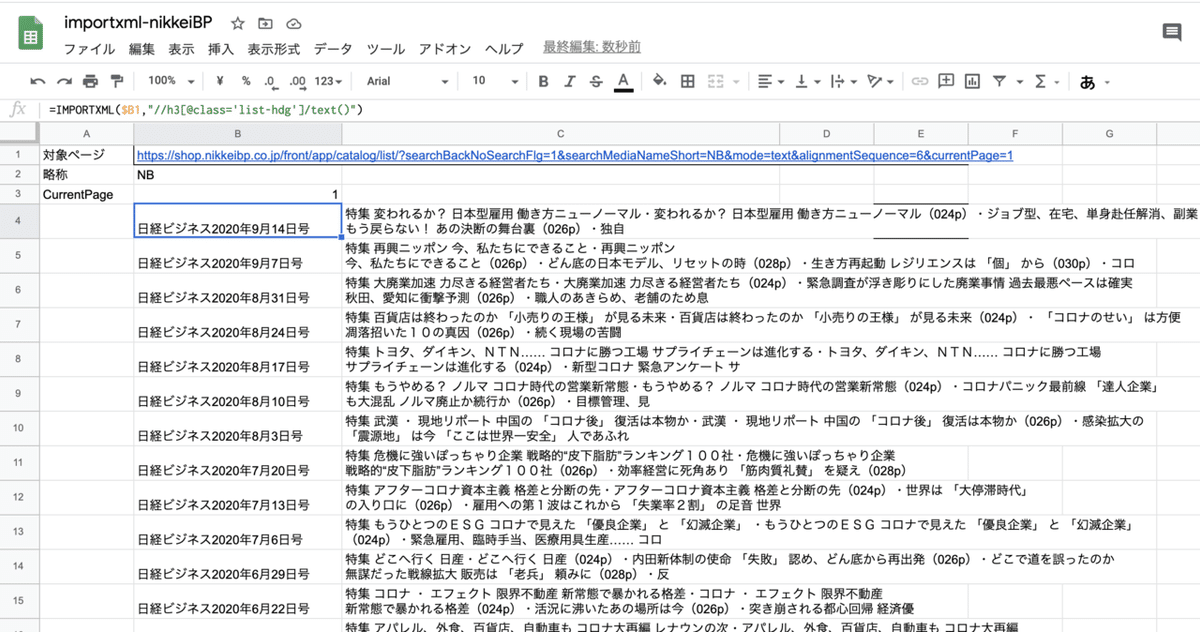
importxml()関数の実行結果は、この関数を記述したセルの下にずらっと表示されます。
そのため、複数の要素を抽出したい場合は、1列1要素として考えるのが良いようです。
実行結果はこんな感じになります。
注意点
このやり方の弱みは散々、上のところで書いたのですが、無事に表を取得できても注意点は残ります。
今回の日経BPの場合は各号に1コンテンツだけの配置だったので、1号が1行ごとにそろいました。
ところが、取得したいページによっては、キーとなる項目に対して複数の項目がぶら下がっていることがあります。
この場合、例えば掲載雑誌名に対して複数の項目が取得されることにより、雑誌名とコンテンツが同じ行に入らず、ずれてしまうことが起こります。
XPathには、今回紹介していない関数も色々あるので、複数項目が現れた時を想定して回避することは可能です。だけど少し煩雑になるのと、なにより修正した後に結果が返ってくるまでに時間がかかるため、修正した式がうまく機能しているか検証するのに時間がかかるのがネックです。
最後に、ご参考まで日経BPページのバックナンバーリスト取得例を貼っておきます。2020年9月18日時点で、機能していることは確認済みです。