
画像の不正利用を検知するための機械学習アプローチ

マクアケ開発本部MLチームの濱川です。
この記事では、アタラシイものや体験の応援購入サービス「Makuake」で公開するプロジェクトにおいて、他のプロジェクトの画像が不正に利用されていないかを検知する仕組みについて紹介します。
具体的には、機械学習を活用した物体検出の仕組みと、抽出された物体(画像)から特徴量を抽出する方法に焦点を当てています。手順も含めて紹介しますので、機械学習にこれから取り組もうと考えている方にも参考になれば幸いです。
画像の不正利用検知の必要性について
検知の必要性については、一般的な著作権などの観点ももちろんありますが、Makuakeのプロジェクト掲載基準として『プロジェクトの要素に「アタラシイ」があること』(Makuake基本方針より)を定めているため、
類似チェックのニーズが高いサービスであるという点も関係しています。
画像の不正利用の検知手法について
他のプロジェクトの画像が完全にコピーされた場合は検知が比較的容易ですが、画像の一部が加工されて使用されると、画像同士の類似度が低くなり検知が難しくなります。
この課題に対処するため、画像内の物体を事前に物体検出で抽出し、その物体から特徴量を計算します。
これにより、画像を比較する際に、画像の一部が抜き出されていても共通の特徴を検知することが可能になります。
物体検出について
では物体検出のプロセスを解説します。
Pythonを活用して物体検出を実行するには、多くのライブラリやフレームワークがありますが、今回はYOLOアルゴリズムを採用しています。
YOLOの主要な特徴を紹介します。
リアルタイム性能:
YOLOは画像を1つの処理パスで通過させ、物体の検出を一度の推論で行います。これにより、高いリアルタイム性能が得られます。
単一のニューラルネットワーク:
YOLOは単一のニューラルネットワークで構成され、物体の位置とクラスの予測を同時に行います。これによりネットワークの単純さと効率性が実現されます。
マルチスケール検出:
YOLOは複数のスケールで物体を検出できるように設計されています。
これにより小さな物体や遠くの物体も効果的に検出できます。
実際にYOLOを利用して画像から物体を検出して抽出する手順は以下の通りになります。
アノテーション作業:
a. 学習データセットにおいて、画像内の物体の位置とクラスをアノテーション(注釈付け)します。
b. 通常、バウンディングボックス(物体の境界ボックス)や物体のクラスラベルが含まれます。
c. アノテーションは、機械学習モデルが物体を学習し、未知の画像で物体を検出するために必要な情報です。
d. 物体認識モデルを十分に効果的に学習させるには、大量のバリエーション豊かな画像が必要で、一般的には最低でも500枚程度の画像が必要ですが、物体の認識度を向上させるためには、数万から数十万枚といった大規模なデータセットが求められます。

プロジェクト画像を使って学習:
e. アノテーションが完了したデータセットを用いて、YOLOモデルを学習させます。
f. 学習は、学習データセットに対して境界ボックスの位置やクラスを正確に予測できるようにモデルのパラメータを調整するプロセスです。
以下のコマンドで学習を実施します。
yolo train data=datasets.yaml model=yolov8l.pt
project=./runs device=0,1,2,3 epochs=200以下パラメータの説明になります。
yolo:
YOLOの学習プロセスを開始するためのコマンドです。 pipからインストールします。
train:
モデルを学習させるためのトレーニングセットを指定するパラメータです。datasets.yamlはトレーニングデータセットの設定が格納されたYAMLファイルです。このファイルには先ほど作成したアノテーションファイルなどの情報が含まれています。
model:
学習に使用するYOLOのモデルファイルを指定します。yolov8l.ptは、YOLOv8のバージョンの学習済みのファイルを使用しています。
project:
学習のログやモデルの保存先となるプロジェクトディレクトリを指定します。./runsはプロジェクトディレクトリのパスを表しています。
device:
学習に使用するデバイス(GPU)を指定します。0,1,2,3は4つのGPUを指定しています。これにより、並列で学習が行われます。
epochs:
学習エポックの数を指定します。学習を200回繰り返すという意味になります。
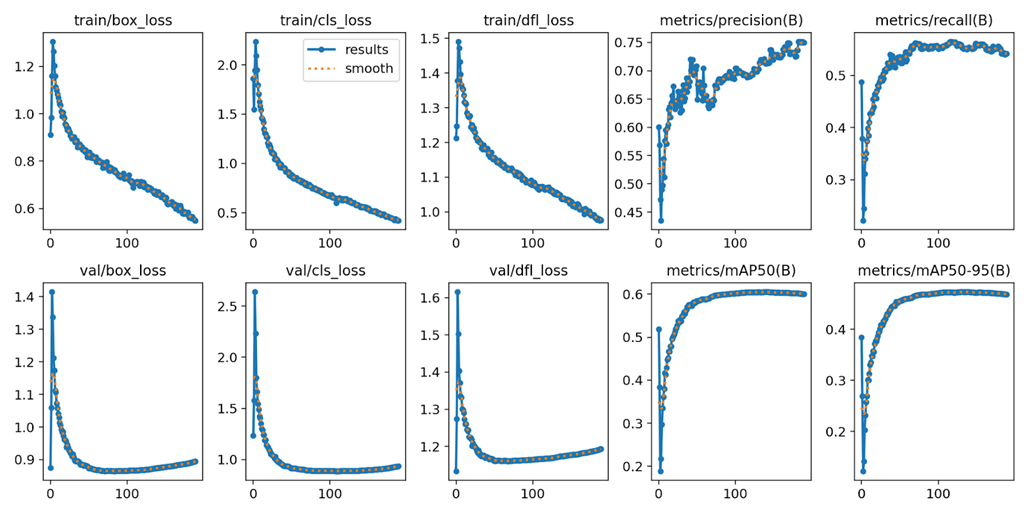
各項目の説明は省略しますが、box_lossはYOLOトレーニングで計算される損失で、モデルが物体の位置をどれだけ正確に予測できるかを示します。
この損失が減少すると、モデルの予測精度が向上していることを意味します。
一方、metrics/mAP50 と metrics/mAP50-95 は物体検出モデルの性能を示す指標で、これらが高いほどモデルの精度が良いことを意味します。トレーニング中にbox_lossが減少し、mAPが上昇するとモデルがより正確に物体を検出できるようになっていることを示します。
学習済みモデルを取得:
g. 学習を終えたら、学習済みのモデルとして保存します。(学習済みモデルはprojectのパラメータに指定された場所にbest.ptという名前のファイルとして出力されます。)
h. 物体検出を行う際には、学習済みモデルを利用します。
yolo predict model=best.pt
source=./sample.jpg(こちらはYOLOコマンドで学習モデルを使用してsample.jpgから物体抽出を実施)

物体から特徴量を計算しANN(近似最近傍探索)でindex化する
次にYOLOを用いて抽出した物体に対して画像の特徴量を計算し、それを効率的に管理するプロセスを説明します。
今回はAKAZEアルゴリズムを用いて物体検出で抽出した画像から特徴量を計算します。特徴量の計算が完了した後、特徴量をANN(近似最近傍探索)と呼ばれる手法で効率的に管理します。
ANNは、最も近い近傍点を効率的に探索する手法であり、これにより大規模なデータセットにおける検索速度が飛躍的に向上します。
計算された特徴量をANNでindex化することで、類似画像の抽出が迅速かつ効率的に行えるようになります。
以下はAKAZEとANNのライブラリannoyを使用した簡単なサンプルになります。AKAZEアルゴリズムを使用して画像から特徴量を抽出し、それをAnnoyIndexに保存しています。
import cv2
import numpy as np
from annoy import AnnoyIndex
# 画像の読み込み
image_path = "path/to/your/image.jpg"
image = cv2.imread(image_path)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# AKAZEディテクターの生成
akaze = cv2.AKAZE_create()
# 特徴量の検出と記述子の計算
keypoints, descriptors = akaze.detectAndCompute(gray_image, None)
# ANNに保存するためのデータ形式に変換
data = np.array(descriptors, dtype=np.float32)
# AnnoyIndexのモデルを作成
dim = data.shape[1] # 特徴量の次元数
annoy_index = AnnoyIndex(dim, metric='angular')
# 特徴量をAnnoyIndexに保存
for i, feature_vector in enumerate(data):
annoy_index.add_item(i, feature_vector)
# AnnoyIndexを保存
annoy_index.save('annoy_index.ann')このサンプルでは、一つの画像の特徴量をAnnoyIndexに保存していますが、実際には日々公開されるプロジェクトの画像をYOLOを使用して物体検出し、その抽出した画像に対してAKAZEとAnnoyIndexを組み合わせてindex化しています。
ANNでindex化することで高速かつ効率的に類似した画像を検出することができます。
画像検知について
実際の画像検知について、似た画像を探し出すプロセスは以下の通りです。
まず、対象となる画像からYOLOを用いて物体を検出し、その検出された各物体に対してAKAZEを適用して特徴量を計算します。これらの特徴量をもとに、AnnoyIndexに似た特徴量を持つ画像の一覧を取得しています。
結果画像を表示することによって、類似した画像を見つけ出すことが可能となります。
最後に
今回、私たちマクアケ開発本部MLチームが取り組んでいる、画像の不正利用を検出するシステムについて簡単にご説明しました。
以前、このシステムを導入する前は似たような画像が存在するかどうかを人力で調査していました。今では、自動的に似ている画像を選別することが可能になりました。
将来的にはさらなる精度向上を図り、大幅な効率化を実現することを目指しています。
一緒に働く仲間を大募集中です!
いかがですか?マクアケではエンジニアを募集中です!
少しでも興味を持っていただいた方は、是非カジュアル面談でお話しませんか?お気軽にご連絡ください!
◉エントリーをご希望の方
◉カジュアル面談をご希望の方
◉マクアケの中の人を知りたい方
この記事がおもしろかった!と思っていただけたら、是非「スキ」&「シェア」をしていただけますと嬉しいです。