
急激なアクセス増加を捌くために実践したこと

スプラ3のアップデートにポケモンデイでのDLCの発表など楽しみがたくさんあって嬉しい日々を過ごしています、アイミツ開発チームでエンジニアリングをしている deliku です!
今月の初めに、通常時の100倍以上のスパイクアクセスが発生し、システムの増強を行なったのですが、そのときに実践したことや考えたことを今回お話ししようかと思います。
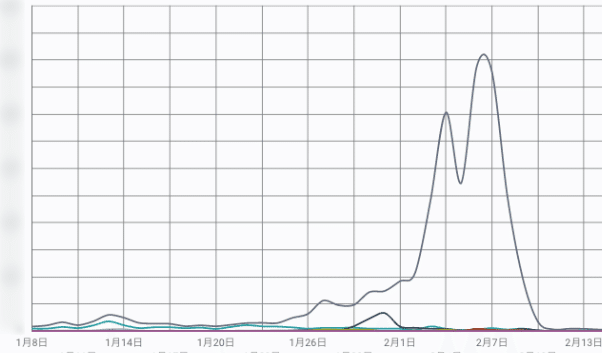
アラート検知
システムは CloudWatch や datadog にて監視を行なっており、スパイクアクセスにともないシステムが高負荷状態になったことで、閾値を超えたリソース情報をSlackに通知するようになっています。
初動
アラート通知内容を確認後、Slackでサービスへの影響有無を報告します。
弊社では普段はリモートで働くメンバーが多いのですが、緊急度が高いものや意思決定をすぐ行う必要があるものは、SlackハドルやGoogleMeetで即集合 / 即意思決定を行うのが良いと考えています。
役割分担
また、最初に役割を明示的にするというのが大事だと私は考えています。
オライリーの入門監視 インシデント管理という章に役割について記載がありますが、インシデントの解決に取り組んでいる人たちに最新情報を直接聞いてしまって、インシデント解決対応の邪魔をすることは避けないといけません。意外にやってしまってる人もいるかと思います。これは体制が周りに伝わっていない場合にも起こりえるので、注意が必要です。
障害は現在進行形で問題は発生している場合が多いことと、原因調査にはすくなくとも時間がかかります。ただ当事者のエンジニア以外からは割と大変さが伝わっていなかったりします。そういうときに営業やサポートチームからは、なぜ障害が起きたのか?もう治ったのか?原因は?という問い合わせもくるでしょう。この本では、こうあるべきだという体制について言及してくれています。
現場指揮官判断する人
顧客や社内のコミュニケーション、調査には携わらない。あがってきた情報をもとに適切に判断する役割です。
スクライブ記録する人
障害対応中は刻刻と状況が変わるものです。後から障害報告書を作成するためにも対応内容は時系列で記録すべきです。
コミュニケーション調整役最新状況のコミュニケーションを関係者に行う人です。障害でなにが発生しているかはこの人に聞くべきです。
SME
実際に障害対応、調査する人です。
原因調査
弊社ではDBにAuroraを使用しているのですが、特定ページへのアクセス集中および、そのページで発行されるいくつかの重いSQLがボトルネックになっておりました。Performance Insights を有効化していることで、負荷状況の評価やボトルネックの特定が容易にできますので、有効化することをおすすめします。

負荷図には重要なグラフィック要素があります。点線の Max vCPUの行は、CPU キューイングが発生する前に CPU でアクティブにできるセッションの最大数を表します。たとえば、2 つの vCPU と 4 つのアクティブなプロセスがあった場合、一度に 2 つのプロセスだけが vCPU でアクティブになります。他の 2 つのプロセスは実行キューで待機します。 したがって、vCPU ラインは、負荷が使用可能なリソースを超えているかどうか、またはインスタンスに空き容量があるかどうかを測定するための良い基準です。
対策
結論から書きますと、下記2点の対応を実施しました。
負荷要因となっている参照クエリをリーダーインスタンスに向けた
リーダーインスタンスを増設し、参照クエリの負荷分散を行なった
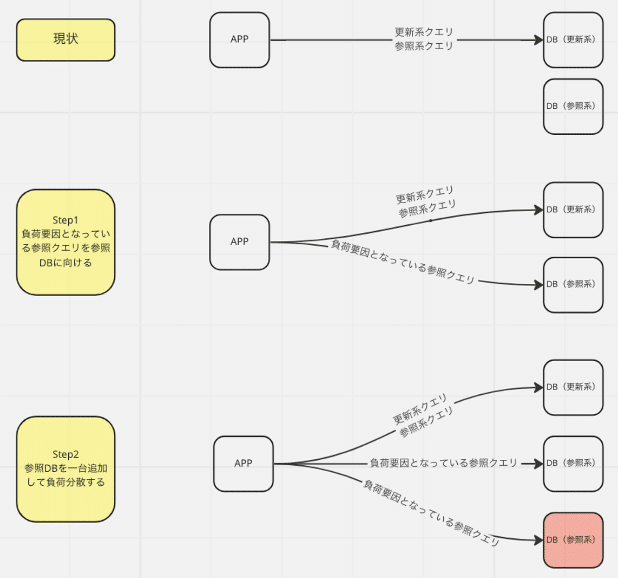
1 負荷要因となっている参照クエリをリーダーインスタンスに向けた
アイミツサービスでは、CQRS(コマンドクエリ責務分離)を採用しています。
そのため特定のクエリをリーダーインスタンスに流すのは比較的簡単に実現できました。リーダーインスタンスのDBConneciton定義を追加し、クエリ実行時に明示的にConnecitonを指定する方法をとりました。

また今回私たちは採用しませんでしたが、Laravelにはstickyオプションというものがあります。Reader / Writer 構成にする場合に選択肢の1つとして上がるのかなと思います。

2 リーダーインスタンスを増設し、参照クエリの負荷分散を行なった
今後同じことが発生した場合に、リーダーインスタンスを広げていくことで負荷分散ができると考えて、スケールアウト戦略をとりました。
クラスメソッドの下記記事は情報が整理されていて大変参考になりました。
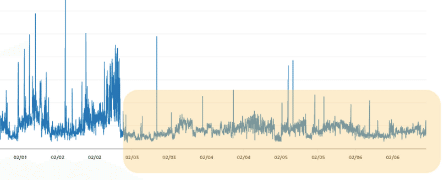
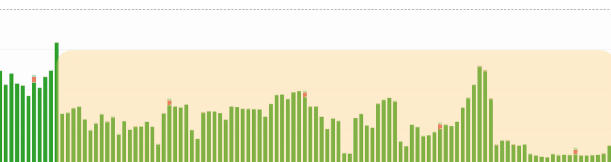
対策後
色をつけた箇所が負荷対応後のグラフになります。応答速度 / ライターインスタンスは平時状態までさがり、リーダーインスタンスにも適度な負荷状態に落ち着いています。

アラート対応を振り返る
今回の対応が落ち着いてから 対応時系列を Notionにまとめました。Slackでなにをやっているかを適時アウトプットしていたので、それを拾ってまとめるだけなのですが、客観的に振り返りができるので私はよくこのやりかたをしています。(対応時系列以外にも、そのときなにが選択肢にあがりどういう意識決定をしたかもNotionに全部書いています)
アラートがきてから検知するまでに時間がかかりすぎなかったか?関係者に情報の伝達はできていたか?などベストをつくせていただろうかをセルフで振り返ります。

まとめ
アラート対応は普段あまりないことですが、場数を踏まないとこういう対応の経験値が積めないのも悩ましいかなと思ったりします。(カオスエンジニアするなどHowはあると思いますが)
私がアラート対応をするうえで大事にしているのは、サービスを提供しているその先にはユーザがいること、もちろんユーザからの問い合わせを受ける社内のメンバーもいるので、提供しているサービスがダウンすることがないように、真摯に向き合っていくことだと思っています。
▶ 【PR】ユニラボ に興味がある方へ
今回の記事を読んでユニラボに興味を持っていただけた方は、まずはカジュアル面談でざっくりお話させていただければと思います!